Python 3最重要的新特性大概要算是对文本和二进制数据作了更为清晰的区分。文本总是Unicode,由str类型表示,二进制数据则由bytes类型表示。Python 3不会以任意隐式的方式混用str和bytes,正是这使得两者的区分特别清晰。你不能拼接字符串和字节包,也无法在字节包里搜索字符串(反之亦然),也不能将字符串传入参数为字节包的函数(反之亦然)。这是件好事。
不管怎样,字符串和字节包之间的界线是必然的,下面的图解非常重要,务请牢记于心:
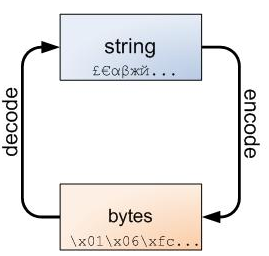
字符串可以编码成字节包,而字节包可以解码成字符串。
>>> '€20'.encode('utf-8')
b'xe2x82xac20'
>>> b'xe2x82xac20'.decode('utf-8')
'€20'这个问题要这么来看:字符串是文本的抽象表示。字符串由字符组成,字符则是与任何特定二进制表示无关的抽象实体。在操作字符串时,我们生活在幸福的无知之中。我们可以对字符串进行分割和分片,可以拼接和搜索字符串。我们并不关心它们内部是怎么表示的,字符串里的每个字符要用几个字节保存。只有在将字符串编码成字节包(例如,为了在信道上发送它们)或从字节包解码字符串(反向操作)时,我们才会开始关注这点。
传入encode和decode的参数是编码(或codec)。编码是一种用二进制数据表示抽象字符的方式。目前有很多种编码。上面给出的UTF-8是其中一种,下面是另一种:
>>> '€20'.encode('iso-8859-15')
b'xa420'
>>> b'xa420'.decode('iso-8859-15')
'€20'编码是这个转换过程中至关重要的一部分。离了编码,bytes对象b'xa420'只是一堆比特位而已。编码赋予其含义。采用不同的编码,这堆比特位的含义就会大不同:
>>> b'xa420'.decode('windows-1255')
'₪20'据说百分之八十的金钱损失皆因使用错误的编码导致,因此务必小心谨慎。
转载于:http://www.ituring.com.cn/article/1116