一、基数排序介绍
基数排序(Radix Sort)是桶排序的扩展,它的基本思想是:将整数按位数切割成不同的数字,然后按每个位数分别比较。
具体做法是:将所有待比较数值统一为同样的数位长度,数位较短的数前面补零。然后,从最低位开始,依次进行一次排序。这样从最低位排序一直到最高位排序完成以后, 数列就变成一个有序序列。
二、基数排序图文说明
基数排序图文说明
通过基数排序对数组{53, 3, 542, 748, 14, 214, 154, 63, 616},它的示意图如下:
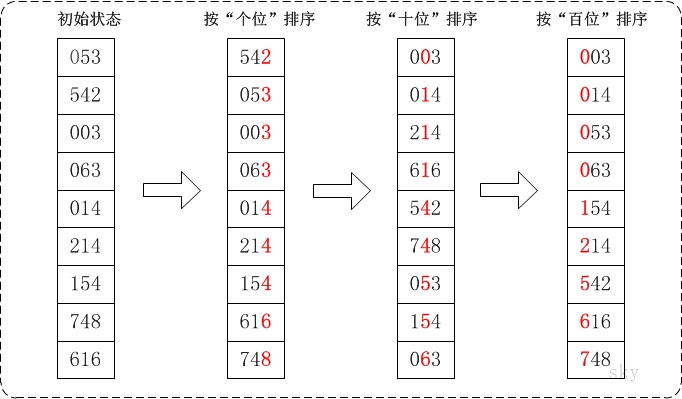
在上图中,首先将所有待比较树脂统一为统一位数长度,接着从最低位开始,依次进行排序。
1. 按照个位数进行排序。
2. 按照十位数进行排序。
3. 按照百位数进行排序。
排序后,数列就变成了一个有序序列。
1 /* 2 * 获取数组a中最大值 3 * 4 * 参数说明: 5 * a -- 数组 6 * n -- 数组长度 7 */ 8 int get_max(int a[], int n) 9 { 10 int i, max; 11 12 max = a[0]; 13 for (i = 1; i < n; i++) 14 if (a[i] > max) 15 max = a[i]; 16 return max; 17 } 18 19 /* 20 * 对数组按照"某个位数"进行排序(桶排序) 21 * 22 * 参数说明: 23 * a -- 数组 24 * n -- 数组长度 25 * exp -- 指数。对数组a按照该指数进行排序。 26 * 27 * 例如,对于数组a={50, 3, 542, 745, 2014, 154, 63, 616}; 28 * (01) 当exp=1表示按照"个位"对数组a进行排序 29 * (02) 当exp=10表示按照"十位"对数组a进行排序 30 * (03) 当exp=100表示按照"百位"对数组a进行排序 31 * ... 32 */ 33 void count_sort(int a[], int n, int exp) 34 { 35 int output[n]; // 存储"被排序数据"的临时数组 36 int i, buckets[10] = {0}; 37 38 // 将数据出现的次数存储在buckets[]中 39 for (i = 0; i < n; i++) 40 buckets[ (a[i]/exp)%10 ]++; 41 42 // 更改buckets[i]。目的是让更改后的buckets[i]的值,是该数据在output[]中的位置。 43 for (i = 1; i < 10; i++) 44 buckets[i] += buckets[i - 1]; 45 46 // 将数据存储到临时数组output[]中 47 for (i = n - 1; i >= 0; i--) 48 { 49 output[buckets[ (a[i]/exp)%10 ] - 1] = a[i]; 50 buckets[ (a[i]/exp)%10 ]--; 51 } 52 53 // 将排序好的数据赋值给a[] 54 for (i = 0; i < n; i++) 55 a[i] = output[i]; 56 } 57 58 /* 59 * 基数排序 60 * 61 * 参数说明: 62 * a -- 数组 63 * n -- 数组长度 64 */ 65 void radix_sort(int a[], int n) 66 { 67 int exp; // 指数。当对数组按各位进行排序时,exp=1;按十位进行排序时,exp=10;... 68 int max = get_max(a, n); // 数组a中的最大值 69 70 // 从个位开始,对数组a按"指数"进行排序 71 for (exp = 1; max/exp > 0; exp *= 10) 72 count_sort(a, n, exp); 73 }
radix_sort(a, n)的作用是对数组a进行排序。
1. 首先通过get_max(a)获取数组a中的最大值。获取最大值的目的是计算出数组a的最大指数。
2. 获取到数组a中的最大指数之后,再从指数1开始,根据位数对数组a中的元素进行排序。排序的时候采用了桶排序。
3. count_sort(a, n, exp)的作用是对数组a按照指数exp进行排序。
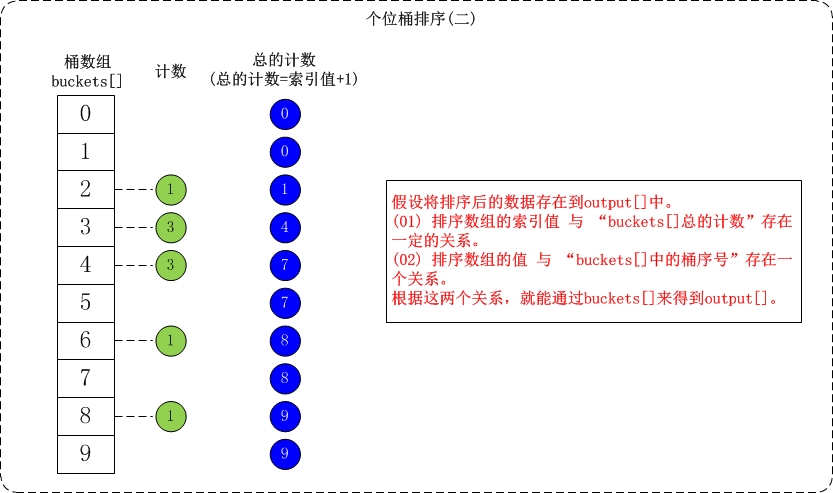
下面简单介绍一下对数组{53, 3, 542, 748, 14, 214, 154, 63, 616}按个位数进行排序的流程。
(1) 个位的数值范围是[0,10)。因此,参见桶数组buckets[],将数组按照个位数值添加到桶中。

(2) 接着是根据桶数组buckets[]来进行排序。假设将排序后的数组存在output[]中;找出output[]和buckets[]之间的联系就可以对数据进行排序了。
三、基数排序的C++实现
1 /** 2 * 基数排序:C++ 3 * 4 * @author skywang 5 * @date 2014/03/15 6 */ 7 8 #include<iostream> 9 using namespace std; 10 11 /* 12 * 获取数组a中最大值 13 * 14 * 参数说明: 15 * a -- 数组 16 * n -- 数组长度 17 */ 18 int getMax(int a[], int n) 19 { 20 int i, max; 21 22 max = a[0]; 23 for (i = 1; i < n; i++) 24 if (a[i] > max) 25 max = a[i]; 26 return max; 27 } 28 29 /* 30 * 对数组按照"某个位数"进行排序(桶排序) 31 * 32 * 参数说明: 33 * a -- 数组 34 * n -- 数组长度 35 * exp -- 指数。对数组a按照该指数进行排序。 36 * 37 * 例如,对于数组a={50, 3, 542, 745, 2014, 154, 63, 616}; 38 * (01) 当exp=1表示按照"个位"对数组a进行排序 39 * (02) 当exp=10表示按照"十位"对数组a进行排序 40 * (03) 当exp=100表示按照"百位"对数组a进行排序 41 * ... 42 */ 43 void countSort(int a[], int n, int exp) 44 { 45 int output[n]; // 存储"被排序数据"的临时数组 46 int i, buckets[10] = {0}; 47 48 // 将数据出现的次数存储在buckets[]中 49 for (i = 0; i < n; i++) 50 buckets[ (a[i]/exp)%10 ]++; 51 52 // 更改buckets[i]。目的是让更改后的buckets[i]的值,是该数据在output[]中的位置。 53 for (i = 1; i < 10; i++) 54 buckets[i] += buckets[i - 1]; 55 56 // 将数据存储到临时数组output[]中 57 for (i = n - 1; i >= 0; i--) 58 { 59 output[buckets[ (a[i]/exp)%10 ] - 1] = a[i]; 60 buckets[ (a[i]/exp)%10 ]--; 61 } 62 63 // 将排序好的数据赋值给a[] 64 for (i = 0; i < n; i++) 65 a[i] = output[i]; 66 } 67 68 /* 69 * 基数排序 70 * 71 * 参数说明: 72 * a -- 数组 73 * n -- 数组长度 74 */ 75 void radixSort(int a[], int n) 76 { 77 int exp; // 指数。当对数组按各位进行排序时,exp=1;按十位进行排序时,exp=10;... 78 int max = getMax(a, n); // 数组a中的最大值 79 80 // 从个位开始,对数组a按"指数"进行排序 81 for (exp = 1; max/exp > 0; exp *= 10) 82 countSort(a, n, exp); 83 } 84 85 int main() 86 { 87 int i; 88 int a[] = {53, 3, 542, 748, 14, 214, 154, 63, 616}; 89 int ilen = (sizeof(a)) / (sizeof(a[0])); 90 91 cout << "before sort:"; 92 for (i=0; i<ilen; i++) 93 cout << a[i] << " "; 94 cout << endl; 95 96 radixSort(a, ilen); // 基数排序 97 98 cout << "after sort:"; 99 for (i=0; i<ilen; i++) 100 cout << a[i] << " "; 101 cout << endl; 102 103 return 0; 104 }