一、 Selenium自动化主要就是
1. 选择界面元素
2. 操作界面元素
输入:点击、输入、拖拽
输出:获取元素的各种属性
3. 根据界面上获取的数据进行分析和处理
二、 选择元素
1. WebDriver:操作整个浏览器的当前整个页面
A. 当前页面上选择符合查找条件的对象
B. 打开网址、回退、前进、刷新页面
C. 获取、改变浏览器窗口大小,关闭浏览器,截屏
D. 获取、设置cookies
2. WebElement:操作和对应Web元素
A. 当前web元素的所有子元素里边符合查找条件的元素
B. 操作该web元素,如:点击元素、输入字符、获取元素坐标、尺寸、文本内容、其他的属性信息。
三、 通过ID选择元素(效率最高)
写法1:
element = driver.find_elements_by_id(" ")
写法2:
from selenium.webdriver.common.by import By driver.find_element(by = By.ID, value = " ")
四、已知异常可以放在try catch 中
try: ele = driver.find_element_by_id(" ") except NoSuchElementException: print('NoSuchElementException')
五、获取元素信息
1. text属性:显示该元素在web页面显示出来的文本内容
2. get_attribute方法
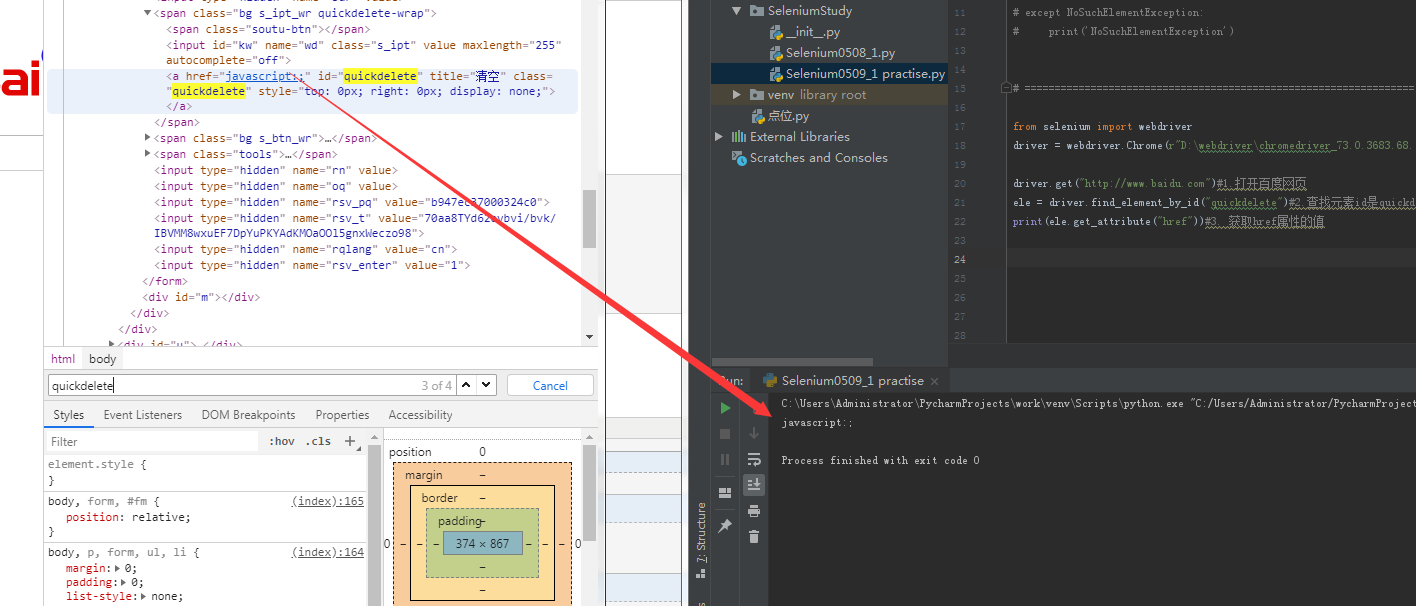
A. 某个属性的值: ele.get_attribute('href')
from selenium import webdriver driver = webdriver.Chrome(r"D:webdriverchromedriver_73.0.3683.68.exe") driver.get("http://www.baidu.com")#1.打开百度网页 ele = driver.find_element_by_id("quickdelete")#2.查找元素id是quickdelete的元素 print(ele.get_attribute("href"))#3. 获取href属性的值
B. 某元素对应html源代码: ele.get_attribute('outerHTML')
from selenium import webdriver
driver = webdriver.Chrome(r"D:webdriverchromedriver_73.0.3683.68.exe")
ele = driver.find_element_by_id("u1")
print(ele.get_attribute('outerHTML'))
driver.quit()

C. 某元素的内部部分的html源代码: ele_attribute('innerhtml')
from selenium import webdriver
driver = webdriver.Chrome(r"D:webdriverchromedriver_73.0.3683.68.exe")
ele = driver.find_element_by_id("u1")
print(ele.get_attribute('innerHTML'))
driver.quit()

P.S.
每次代码最后一行不加上driver.quit(),chromedriver的进程就一直都在,关闭浏览器也没有用