仍在更新
前言
关于我突然补起树剖这件事呢,其实是因为最近做的题可以用树剖做,结果发现我不会树剖,就开始恶补了树剖。
树剖是什么
树剖,即树链剖分。
树链剖分的定义:
一种对树进行划分的算法,它先通过轻重边剖分将树分为多条链,保证每个点属于且只属于一条链,然后再通过数据结构(树状数组、BST、SPLAY、线段树等)来维护每一条链。——百度百科
首先声明几个定义:
- 重儿子:一个点的儿子中子树大小最大的儿子。
- 轻儿子:一个点的儿子中除了重儿子的儿子。(注:叶子节点既没有重儿子也没有轻儿子,因为他没有儿子)
- 重边:连接父亲和重儿子的边。
- 轻边:连接父亲和轻儿子的边。
- 重链:相邻重边连起来的,连接重儿子的一条链。(但是起点是轻儿子)
那么树链剖分可以处理什么问题呢?
- 更改路径上的值
- 查询一条路径的总和
- 更改一个子树的值
- 查询一个子树的值
先用两个 ( ext{dfs}) 来预处理一些东西。
dfs1
这个 ( ext{dfs}) 求出每个的点的父亲、深度、子树大小和重儿子。
void dfs1(int x,int fa)
{
f[x]=fa;//父亲
deep[x]=deep[fa]+1;//深度
size[x]=1;//大小
for (int i=a[x].head;i;i=a[i].next)
{
int v=a[i].to;
if (v==fa) continue;
dfs1(v,x);//深搜儿子
size[x]+=size[v];//大小传递
if (size[v]>=size[son[x]]) son[x]=v;//求出重儿子
}
}
dfs2
这个 ( ext{dfs}) 记录每个点的新编号、新编号的值和所处重链的开头。
void dfs2(int x,int tp)
{
top[x]=tp;//重链开头
id[x]=++cnt;//新编号
v1[cnt]=val[x];//重新赋值
if (!son[x]) return;//叶子结点没有重儿子,结束
dfs2(son[x],tp);//先重儿子后轻儿子,理由见下
for (int i=a[x].head;i;i=a[i].next)
{
int v=a[i].to;
if (v!=f[x]&&v!=son[x]) dfs2(v,v);//轻儿子的重链开头是他本身
}
}
处理问题
那么在 ( ext{dfs2}) 中为什么要先走重儿子后走轻儿子呢?
模拟一下:
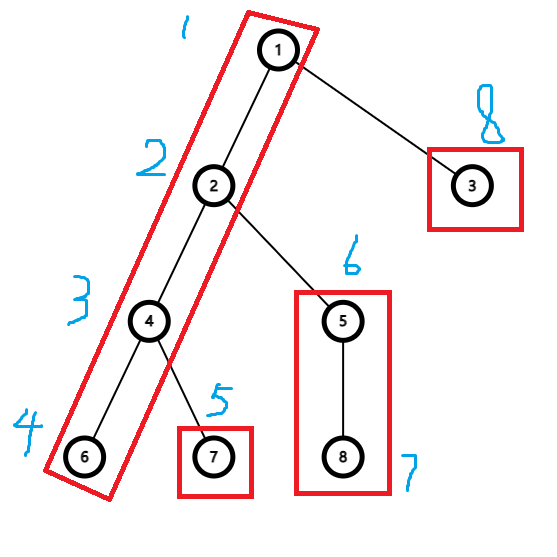
容易看出图中的重儿子有 2、4、6、5、8,有四条重链(用红框框住的),同时由于先走重儿子的缘故,重链上的编号是连续的。