1. 从赛马说起
0x1:赛马问题场景介绍
假设在一场赛马中有m匹马参赛,令第i匹参赛马获胜的概率为pi,如果第i匹马获胜,那么机会收益为oi比1,即在第i匹马上每投资一美元,如果赢了,会得到oi美元的收益,如果输了,那么回报为0。
有两种流行的马票:
- a兑1(a-for-1):开赛前购买的马票,马民赛马前用一美元购买一张机会收益为a美元的马票,一旦马票对应的马在比赛中赢了,那么他持有的那只马票在赛后兑换a美元,否则,他的马票分文不值。
- b兑1(b-to-1):赛后交割的马票,机会收益为b:1,一旦马票对应的马输了,则该马民赛后必须交纳一美元本金,但是如果赢了,赛后可以领取b美元。
当b = a-1时,”a兑1“和”b赊1"两种马票的机会收益等价。例如,掷硬币的公平机会收益倍数是2兑1或者1赊1。
假设某马民将全部资金分散购买所有参赛的马匹的马票,bi表示其下注在第i匹马的资金占总资金的比例,那么bi>=0, 。如果第i匹马获胜,那么该马民获得的回报是下注在i匹马的资金的oi倍,而下注在其他马匹上的资金全部输掉。于是,赛马结束时,如果第i匹马获胜,那么该马民最终所得的资产为原始财富乘以因子bioi,而且这样发生的概率为pi。
。如果第i匹马获胜,那么该马民获得的回报是下注在i匹马的资金的oi倍,而下注在其他马匹上的资金全部输掉。于是,赛马结束时,如果第i匹马获胜,那么该马民最终所得的资产为原始财富乘以因子bioi,而且这样发生的概率为pi。
从这里可以看到,如果马民采取但是“showhand策略”,即每次都将所有资金全部投资出去,那么该马民的整体资产就取决于一个随机变量bioi的速率(称之为累积因子),不断累乘利润。令Sn为该马民在第n场赛马结束时的资产,则有:
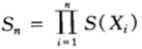 ,其中
,其中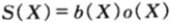 是当第X匹马获胜时,马民购买该只马票所得收益的累积因子。
是当第X匹马获胜时,马民购买该只马票所得收益的累积因子。
所以,相对收益是一个累积因子,如果马民中了X马票,那么他的相对收益就是原始财富乘以该因子。
0x2:赛马投资双倍率公式定义
由上面对一场赛马的相对收益公式定义可知,一场赛马的双倍率为:
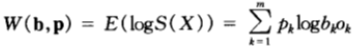
假设赛马的结果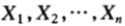 为服从p(x)的独立同分布序列,那么该马民在策略b之下的相对收益将以指数因子为
为服从p(x)的独立同分布序列,那么该马民在策略b之下的相对收益将以指数因子为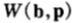 呈指数增长,即:
呈指数增长,即:

证明过程如下:
由于独立的随机变量的函数仍然是独立的,从而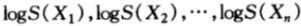 也是独立同分布的,由弱大数定律可得:
也是独立同分布的,由弱大数定律可得:
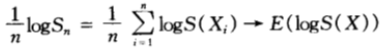
于是有:
由于马民的相对收益是按照 方式增长,因此,接下来的问题是如何在所有投资组合策略b的集合中,寻找使得最大化的策略,以便得到最快的双倍率累计结果。
方式增长,因此,接下来的问题是如何在所有投资组合策略b的集合中,寻找使得最大化的策略,以便得到最快的双倍率累计结果。
0x3:最大双倍率策略估计
1. 最优下注策略Kelly策略,以及最优双倍率的上界
如果选择b使得双倍率达到最大值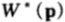 ,那么称该值为最优双倍率:
,那么称该值为最优双倍率:

上式中,b作为随机变量,作为b的函数,在约束条件之下求其最大值。可以写入如下拉格朗日乘子函数并且改变对数的基底(不影响最大化b),则有:
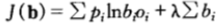
关于bi求导得到:
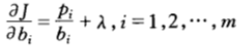
为了求得最大值,令偏导数为0,从而得出:

代入约束条件可得λ=-1,以及bi=pi。从而,我们得到b=p为函数J(b)的驻点,即按照比例b=p下注是最优的策略,该策略也被称为Kelly策略。
由此,我们得到一个最优下注定理,即按比例下注是对数最优的,最优双倍率的公式计算如下:
 ,并且当按比例
,并且当按比例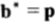 的下注策略可以达到该最大值。证明过程如下:
的下注策略可以达到该最大值。证明过程如下:
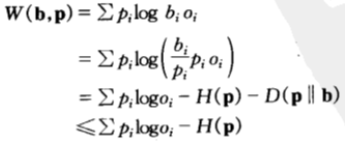
等号成立的充要条件是b=p,即马民应该按照每匹马获胜的概率按比例分散地购买马票。
考虑仅有两匹马参赛的特殊情形,假设马1获胜的概率为p1,马2获胜的概率为p2。假设两匹马的机会收益率均等(均为2兑1方式),此时的最优下注策略为按概率比例下注,即b1=p1,b2=p2。
此时最优双倍率为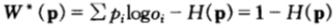 ,按照这样的增长率,将导致相对收益无限增长,
,按照这样的增长率,将导致相对收益无限增长,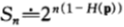 。
。
至此,我们证明了对于一系列独立同分布的赛马,如果马民将全部现金反复购买马票而不是捂住现金不动,那么按比例下注是相对收益增长最快的策略。
继续考虑一种特殊情形,即关于某种分布具有公平机会收益倍率的情形。换言之,除了知道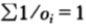 之外,无其他信息可用。此时,记
之外,无其他信息可用。此时,记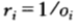 ,将其视为参赛马匹的一种概率密度函数(这是用来估计赛马获胜概率的所谓马民法)。在此记号下,双倍率可以写为:
,将其视为参赛马匹的一种概率密度函数(这是用来估计赛马获胜概率的所谓马民法)。在此记号下,双倍率可以写为:
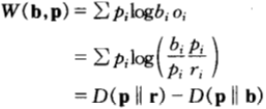
该方程给出了双倍率在相对熵视角下的另一种解释:双倍率是马民法的估计到真是分布的距离,与马民下注策略到真是分布的距离之间的差值。
所以,马民要赚钱,只有当他的估计(由b表示)比马民法所得的估计(由r表示)更好。上式才为正数,相对收益才会不断增加。
2. 收益双倍率守恒定理
考虑一种更特殊的情形是:如果每只马票的机会收益倍率为m兑1,此时,机会收益均等,服从均匀分布且最优双倍率为:
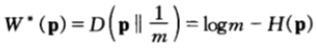
在此情形下可以看到:双倍率与熵率之和为常数。
这就是双倍率与熵率对偶守恒定律,即对于均匀的公平机会收益倍率,有: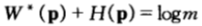 。
。
熵每减小一比特,马民的收益就翻一番,在熵越小的比赛中,马民的获利越丰厚。
0x4:赛马最终收益(相对收益)随机变量结果讨论
在实际的情况中,马民不一定会倾囊投资,一般来讲,应当允许马民有选择地保留一部分现金。令b(0)为原始财富中预留为现金的比例,b(1),b(2),....,b(m)为分别购买每匹马的马票的资金比例。那么在赛事结束时,最终资产与原始财富的比例(即相对收益)为:
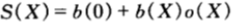
此时的最优化策略依赖于机会收益,我们分情况讨论:
1. 服从某种分布的公平机会收益倍率
这种情况下,机会收益分布为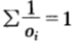 ,对于公平机会收益倍率,保留现金的选择并不影响分析。因为我们可以在保留现金的情况下按
,对于公平机会收益倍率,保留现金的选择并不影响分析。因为我们可以在保留现金的情况下按 ,i=1,2,...,m比例下注在第i匹马得到的效果是相同的,因为整个计算是等比例缩放的。于是,马民到底保存多少现金没有关系,可以简单理解为整体马民投入的钱减少了,多投多赚,少投少赚,依然是按比例下注策略最优。
,i=1,2,...,m比例下注在第i匹马得到的效果是相同的,因为整个计算是等比例缩放的。于是,马民到底保存多少现金没有关系,可以简单理解为整体马民投入的钱减少了,多投多赚,少投少赚,依然是按比例下注策略最优。
2. 超公平机会收益倍率
这种情况下,机会收益分布为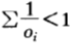 ,这种比赛的机会收益整体优于公平机会收益倍率的赛事,颇有送钱给马民的感觉。所以,任何人都希望将全部资金都押进去而不必保留现金。在这种比赛中,依然是按比例下注策略最优。
,这种比赛的机会收益整体优于公平机会收益倍率的赛事,颇有送钱给马民的感觉。所以,任何人都希望将全部资金都押进去而不必保留现金。在这种比赛中,依然是按比例下注策略最优。
3. 次公平机会收益倍率
这种情况下,机会收益分布为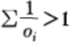 ,此情形更代表现实生活,这种情况代表了赛马组织在流程内做了手脚导致收益机会总和小于1。在此种赛马中,马民只应该用一部分资金买马票,而将其他的现金捂住,这是最起码的策略。此时,按比例下注不再是对数最优了。
,此情形更代表现实生活,这种情况代表了赛马组织在流程内做了手脚导致收益机会总和小于1。在此种赛马中,马民只应该用一部分资金买马票,而将其他的现金捂住,这是最起码的策略。此时,按比例下注不再是对数最优了。
Relevant Link:
《信息论基础》阮吉寿著 - 第六章
2. 边信息对赛马博弈结果的影响
假设马民具有一些关于赛马结果的成功和失败的信息,例如,马民或许拥有某些参赛马匹的历史记录,那么这些信息会如何影响最终的相对收益呢?
我们将马民得到的边信息定义为互信息,将因该信息而导致的双倍率的增量定义为信息价值,接下来我们来推导互信息与双倍率增量之间的联系。
假设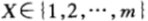 为第X只马票,它获胜的概率为p(x),机会收益率为:o(x)兑1。设(X,Y)的联合概率密度函数为p(x,y)。用
为第X只马票,它获胜的概率为p(x),机会收益率为:o(x)兑1。设(X,Y)的联合概率密度函数为p(x,y)。用![]() ,
,![]()
 表示已知信息Y的条件下的下注策略。此处
表示已知信息Y的条件下的下注策略。此处 理解为当得知信息y的条件下,用来买第x只马票的资金的比例。一般地,
理解为当得知信息y的条件下,用来买第x只马票的资金的比例。一般地,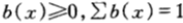 表示无条件下注策略。
表示无条件下注策略。
设无条件和条件双倍率分别为:

再设双倍率增益为:
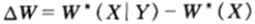
由于获得某场赛马X中边信息Y而引起的双倍率的增量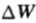 满足:
满足:
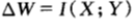
下面来证明该定理。在具有边信息的条件下,按照条件比例买马票,即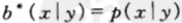 ,那么关于边信息Y的条件双倍率
,那么关于边信息Y的条件双倍率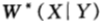 可以达到最大值,于是:
可以达到最大值,于是:
 ,最右一步用到了贝叶斯概率分解公式。
,最右一步用到了贝叶斯概率分解公式。
一般地,当无边信息时,最优双倍率为
 ,这和我们前面讨论的一致。
,这和我们前面讨论的一致。
从而,由于边信息Y的存在而导致的双倍率的增量为:
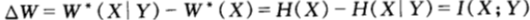
从上面讨论可以看到,边信息没有改变双倍率的期望值,只是改变了对赛马结果X不确定熵的取值,在守恒定律的作用下,边信息给最终双倍率带来的增量,等价于边信息给赛马结果X不确定性减低的熵值,即互信息。
毫无疑问,独立的边信息并不会提高双倍率,只是降低赛马结果X的不确定熵。这也一个侧面说明了最优双倍率是一个理论最优值,和具体的过程和结果概率分布X无关。
Relevant Link:
《信息论基础》阮吉寿著 - 第六章
3. 多轮赛马序列下的守恒定理
0x1:赛马序列随机过程下的相对收益
在赛马中,边信息最通常的表现形式是所有参赛马匹在过去比赛中的表现(即历史先验知识),如果各场赛马之间是独立的,那么这些信息毫无用途,但是如果假设各场赛马构成的序列之间存在关联关系,那么只要允许使用以前比赛的记录来决定新一轮赛马的下注策略,就可以计算出有效的双倍率。
假设由各场赛马结果组成的序列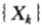 是一个随机过程,假设每场赛马的下注策略依赖于此前的各次比赛的结果,此时,具有均匀的公平机会收益倍率的比赛的最优双倍率为;
是一个随机过程,假设每场赛马的下注策略依赖于此前的各次比赛的结果,此时,具有均匀的公平机会收益倍率的比赛的最优双倍率为;

该最优双倍率可以在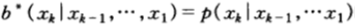 时达到。
时达到。
当第n场赛马结束时,马民的相对收益变成:
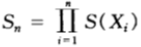
且双倍率(增长率指数)(假设为m兑1方式)为:
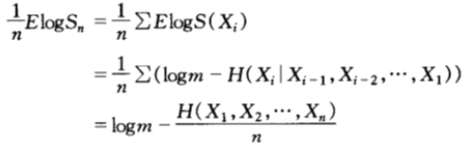
其中,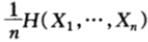 是n场赛马的平均熵。对于熵率为
是n场赛马的平均熵。对于熵率为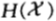 的平稳过程,对上式两边取极限可得:
的平稳过程,对上式两边取极限可得:
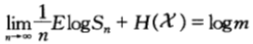
我们再次看到了守恒定理,即熵率与双倍率之和为常数。
0x2:通过一个随机过程案例看最优收益增长率公式
笔者思考:赛马中的最优双倍率策略,体现了一种绝对理性主义的策略思想,即每一步的决策都完全遵循某种理性主义思辨的结果,不参杂任何主观的臆断因素,只要保证了这一点,那么最终的收益结果就可以达到一个理论最优值,和所参与的博弈游戏过程都无关,不管过程中胜败如何,最终得到的收益都是可预期的,且最优的。
我们来看一个扑克牌博弈的例子,叫红与黑。一副扑克牌分成26张红和26张黑,每一轮中从两堆中随机抽取一张,游戏参与者需要猜测是红色还是黑色,直到所有牌发完。我们假设该游戏的机会收益为2兑1,显然,红色和黑色出现的概率相同,这种游戏是公平机会收益的。
接下来问题来了,你需要采取什么游戏策略,以此来博得最大的收益呢?
仔细分析一下就会发现,第一轮时,我们没有任何先验知识,红和黑的概率都是1/2,此后每一轮后,剩下的红黑牌数量都会发生变化,所以对红和黑的猜测概率也会不断发生变化,将整个游戏看做是一个随机过程,上一小节已经讨论过,最优双倍率策略为,即不断根据场上当前的概率p(Xi)来决定本轮的猜测策略。
考虑以下两种下注方案:
- 顺序地下注,每一轮中都可以计算出下一张牌的条件概率并且按该条件概率为比率下注。于是,将按照(红,黑)的概率分布为(1/2,1/2)下注第一张,当第一张为黑色时,再以(26/51,25/51)为概率分布下注第二张,如此下去。
- 一次性下注所有52张牌构成的序列,那么总共有
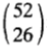 种可能的序列,且每个序列出现的概率相等。于是,按比例下注意味着将现金分成份,对每一个序列下注
种可能的序列,且每个序列出现的概率相等。于是,按比例下注意味着将现金分成份,对每一个序列下注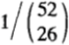 的资金。当然假设我们猜对或猜错每张扑克牌是红是黑的概率各占一半。
的资金。当然假设我们猜对或猜错每张扑克牌是红是黑的概率各占一半。
上述两种方案本质是等价的。用归纳法来看,52张牌组成的所有序列中,第一张牌是红色的所有序列恰好占一半,所以方案2在第一轮赌红色也是一半资金。以此类推。一般地,如果将种可能的序列视为基本事件,那么可以验证:对每个基本事件下注资金,则所有下注的策略在任何场合都是与红色与黑色在此场合出现的概率成比例。类比赌马模型,我们只将资金下注在可能的基本事件上,而且只下注在使得相对收益增长率是252的因子的观测序列上,对于其他序列分文不投,那么,最终相对收益为:

可以看到,此回报并不依赖于具体的序列,这就像AEP中所说的,任何序列都有相同的回报,从这个角度来讲,所有序列都是典型的。
Relevant Link:
《信息论基础》阮吉寿著 - 第六章
4. 熵对语料库的随机逼近
为了讨论方便,假设英文的字母表由26个字母和空格共计27个字符构成。通过收集一些文本样本,根据这些文本中的字符的经验分布建立英文词频模型。
0x1:不同Ngram-Size对英文语料的随机逼近效果分析
在英文语料中,单字母出现的概率远不是均匀的,例如:
- 字母E出现的概率最高达13%
- 频率最低的字母Q和Z大约为0.1%
双字母也一样远不是均匀分布,例如:
- 字母Q后面总是跟着字母U
- 但频率最高的双字母是TH(通常出现的概率为3.7%),而不是QU
可以利用这些双字母出现的频率来估计一个字母后面跟随另一个字母的概率,即字母表的二阶概率转移矩阵。
同理还可以继续增加step-size的长度,估计更高阶的条件概率并建立更复杂的模型,但是,随着step-size的增加,很快会遇到”概率空洞问题“。例如,建立三阶的马尔科夫逼近,必须估计条件概率p(xi | xi-1,xi-1,xi-3)的值,那么整个三阶概率转移矩阵表就是一个274的巨大表格。这样,要想得到所有这些3阶条件概率的精确估计,就必须引入百万数量级的样本。这在实际工程里当然很难做到,不可能总能准备好那么大量的样本,所以这部分概率空洞的条件概率项就置零,但是置零又会导致整个句子的累乘式为零,所以为了解决这个问题,又引入平滑技术,相关的细节讨论,这里不再展开,可以参阅另一篇文章。
需要注意的是,不管NLP中引入的什么平滑技术,还是后来发展处的词向量嵌入等技术,对于NLP问题来说,我们都可以借助信息论的一个核心概念:”熵“来得到很好的解释。
N阶Ngram词频模型是一种随机逼近的方法(NLP中还有其他随机逼近方法),使用越高的阶,模型的复杂度就越高,相应的对英文语料的逼近就越强。定量地度量所谓的逼近效果的方法就是不确定熵,可以这么理解:随着词模型复杂度的增加,可以捕获到英文语料中的更多结构信息,且使得下一个字母的条件不确定性变小,相应的,熵值也就越小。例如:
- 使用0阶模型时:熵为log27=4.76比特/字母。
- 使用1阶模型时:以列视角看2阶概率转移矩阵,每个字母大多数时候就不是像0阶那样相对均匀分布了,而是集中在某些2阶词组中,概率分布的均匀性降低,熵值也就降低了,例如笔者在测试集中算得在1阶模型情况下,熵为4.03比特/字母,
- 使用4阶模型时:相比于1阶,单个字母在不同4阶词组中的分配更加集中了,所以熵值进一步降低,例如笔者在测试集中算得在4阶模型情况下,熵为2.8比特/字母。
但需要明白的是,即使是4阶模型,甚至工程师们最喜欢的5阶模型(5-gram)也不能捕获到英文的所有结构,答案很简单,因为即使是5阶模型,依然存在不小的不确定熵。
0x2:不同马尔科夫阶的模型对Webshell语料库的随机逼近效果
为了更形象说明上面的理论,我们借助香农在最早的论文中提到的一种对英文语料的简单随机逼近方法,来一起看一下不同的阶数,是如何影响语言模型的随机逼近效果的。
用一个语料库(例如一个样本集合)为道具,若构造二阶模型:
- 那么随机选择一个样本,并随机选定该样本内的一个字母,这相当于初始化过程。
- 再随机地选择另一个样本,随机地从某处开始往下搜索,直到出现第一个字母为止,将紧随该字母的那个字母选取为第二个字母。如果一直都没有搜索到第一个字母,则重新选择另一个样本。
- 得到第二个字母后,重复前面过程,当我们找到第二个字母后,取其后面的那个字母作为第三个字母。
- 如此下去,我们可以生成一个文本序列,它就是我们的语料库的二阶统计量的拟合。
笔者这里用网络安全里常见的webshell语料库为例,下载链接在这里。
# -*- coding: utf-8 -*- import os from random import choice def N_order_Markov_processes(order, path_list): finnal_sequence = "" # initial, choice a random file choice_file_path = choice(path_list) choice_file_path_content = open(choice_file_path).read() choice_file_path_word = choice(choice_file_path_content) finnal_sequence += choice_file_path_word # search another file for i in range(order): while True: choice_file_path = choice(path_list) choice_file_path_content_list = list(open(choice_file_path).read()) try: last_word_index = choice_file_path_content_list.index(choice_file_path_word) + 1 choice_file_path_word = choice_file_path_content_list[last_word_index:last_word_index + 1][0] finnal_sequence += choice_file_path_word break except Exception, e: continue return finnal_sequence def main(): path_list = [] ROOT_PATH = '/Users/zhenghan/Downloads/webshell-sample-master/php' for f in os.listdir(ROOT_PATH): if f == '.DS_Store': continue file_path = os.path.join(ROOT_PATH, f) path_list.append(file_path) # generate a 32 length sequence, which each word is an zero-order markov sequence finnal_sequence = "" for i in range(32): finnal_sequence += N_order_Markov_processes(1, path_list) print "finnal_sequence: ", finnal_sequence if __name__ == '__main__': main()
- 0阶逼近结果:几乎没有捕获到任何结构信息
-
- 1阶逼近结果:
-
- 2阶逼近结果:
-
- 3阶逼近结果
-
- 4阶逼近结果
-
- 5阶逼近结果





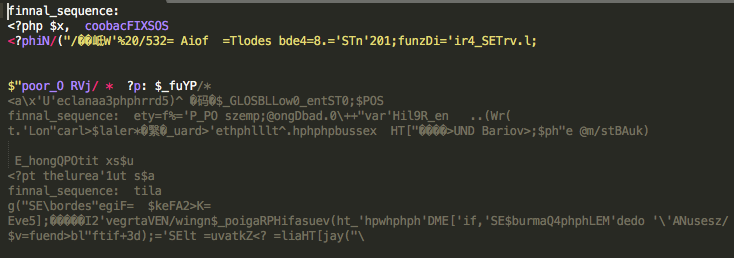
可以看到,到5阶的时候, 随机逼近的结果开始出现了正确的php标签,即开始渐渐捕获到了语料库中的一些结构信息。
Relevant Link:
https://github.com/ysrc/webshell-sample
5. 从熵角度看不同词素抽象方式在WEBSHELL文本检测中的效果区别
0x1:我们要讨论什么问题?
下图展示了一个webshell文件的截图
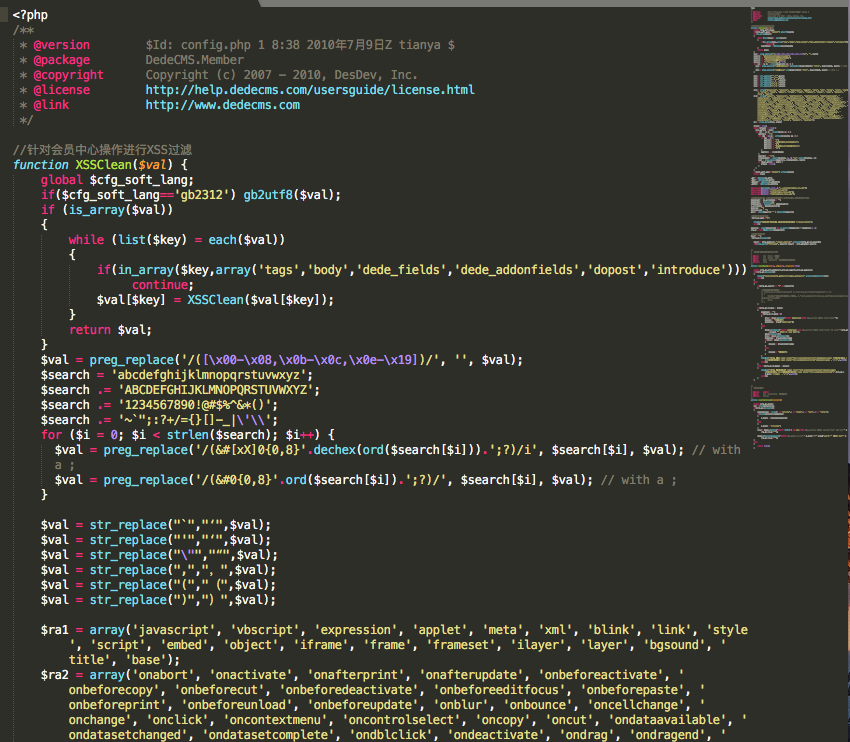
如果要将这类plain text文件输入机器学习模型,就需要进行向量化特征工程,但问题是如何进行向量化呢?本章我们来对比两种主流的方法,并说明其优劣和原理。这两种方法包括
- char-based vector method:逐个将每个char翻译为其对应的ascii向量。
- ast-token-based vector method:将原始文件通过词法引擎预处理为一种词法树的形式,然后按照顺序逐个将每个ast-token翻译为其对应的index索引向量。
-
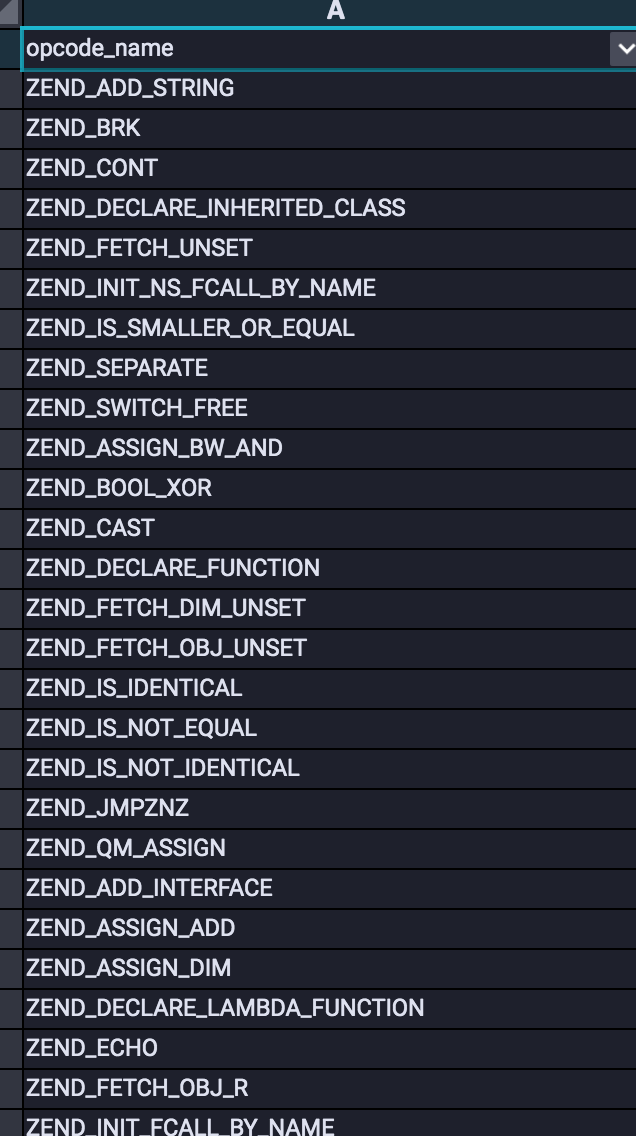
上图给出了ast-token的一个部分截图,以帮助读者建立直观感受。
0x2:如何对一种方案的熵进行建模分析
评估方案本身的熵是一个比较抽象的目标,我们寻找一个等价的问题,我们将每种技术方案都想象成一个人,它们共同在参与一个博弈估计的游戏。在此游戏中,给嘉宾任意一个web文件(可能是合法文件也可能是非法webshell文件),随机指定一个词素(char或者ast-token)作为初始化,并不断让嘉宾猜测下一个出现的词素。
与赛马的情形一样,最优的博弈策略是与下一个词素出现的条件概率成比例。猜对了词素的机会收益是:
- char有256个词素:256兑1
- ast-token有129个词素:129兑1
由于一连串的分布下注等价于下注一个序列的所有项,因此,在n个词素之后可得到所有的收益总额为:
- char-based method:Sn = (256)nb(X1,X2,...,Xn)
- ast-token-based method:Sn = (129)nb(X1,X2,...,Xn)
于是,经过n论下注,相对收益的对数期望满足下式:
- char-based method:
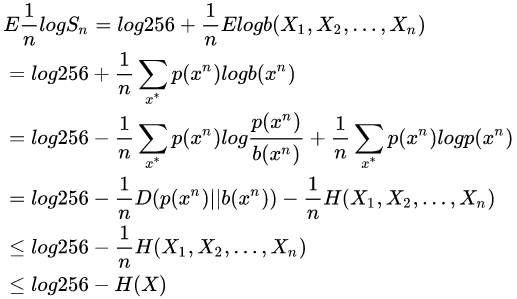
- ast-token-based method:

此处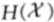 是不同方案下,词素的熵率。于是
是不同方案下,词素的熵率。于是![]() 和
和![]() 是两种方案各自的熵率的上界。
是两种方案各自的熵率的上界。
如果假设webshell文本是遍历的,且参赛嘉宾使用最优双倍率策略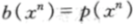 (即最大后验概率估计),那么其上界估计依概率收敛于各自的熵率,即:
(即最大后验概率估计),那么其上界估计依概率收敛于各自的熵率,即:
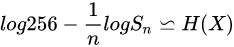
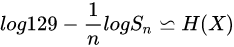
进一步的,又因为熵率的上界为:H(X) <= log|X|。
所以,综上所述,ast-token-based的特征工程方式,要比char-based的方案熵率要小,即不确定度更小,在相同的训练样本情况下,ast-token-based方式可以获得理论上更好的效果。
0x3:评估建模方案好坏的另一个方面 - 互信息
互信息的公式如下:
![]() ,它定义了X含有Y的信息量。
,它定义了X含有Y的信息量。
这里X就是不同方案中的特征向量,而Y就是label标签位。可以这么理解,通过输入特征向量,能多大程度降低对未知label标签的模糊程度。
这项评估也很简单,可以在特征工程阶段进行,在开始实际训练之前,我们肯定都有一份带标签的特征向量训练集。通过对X和Y进行相关性分析,可以得到一个互信息的量化度量。一个好的技术方案,其特征向量和待预测标签之间的互信息应该是很高的。
这里举一个虚构的具体例子说明,假设你的训练集里有如下带标签的特征向量数据。
.... [1,1,1,0,0,0] -> lable = 1 [0,0,0,1,1,1] -> lable = 1 ... [1,0,0,1,0,1] -> lable = 0 [0,1,1,0,1,0] -> lable = 0 ...
读者注意到了吗?上述训练集中,出现了2对完全相反的特征向量,但同时其label又是相同的。这个现象怎么理解呢?用熵的理论视角来看就是:
- 对于label=1来说,该数据集的是一个均匀分布,即最大熵分布,互信息为0
- 对于label=0来说,该数据集的是一个均匀分布,即最大熵分布,互信息为0
当然这是一个虚构的极端例子,现实工程中不会极端。但与其类似的场景却屡见不鲜,笔者自己在项目中也曾经遇到过。当然原因有很多,脏数据总是在所难免的,pure data在实际工程中是很少见的。
笔者这里想告诉大家的是,在开始训练之前,一定要关注数据本身的质量,如果训练集本身对待预测目标的互信息很低,那么不管投入多少理论研究资源,都是无法突破理论上界,也不能拿到好的结果。
0x4:Convolution or Sequence?
需要注意的是,图像领域的问题因为本身具备几个核心特性,因而特别适合于CNN卷积网络,例如:
- 平移不变性
- 轻度扭曲近似不变性
- 等比例放缩近似不变性
- 噪点容忍鲁棒性
- 边界渐变性
但是上述的这些特性,当面对的是网络安全中的各类文本的时候,几乎全都不适用。所以,在实际工程中使用最多的是RNN及其变体的长序列依赖模型,很多文本问题都可以转化为序列问题来建模和解释。
Relevant Link:
https://www.cnblogs.com/LittleHann/p/11266085.html#_lab2_2_0