本篇主要介绍关于mysql的一些非常基础的知识,为后面的sql优化做准备。
一:连接mysql
关于mysql的下载和安装我在这里就不说了,第一步我们要连接我们的mysql服务器,打开cmd命令切换到你安装MySQL Server 的bin目录下,然后输入mysql -h localhost -u root -p
其中-h 表示你的主机地址(本机就是localhost,记住不要带端口号) -u 就是连接数据库名称 -p就是连接密码。出现以下图就表示连接成功了

二:常用的sql语句
2.1:创建数据库 create database 数据库名
2.2:删除数据库 drop database 数据库名
2.3:查询系统中的数据库 show databases
2.4:使用数据库 use 数据库名
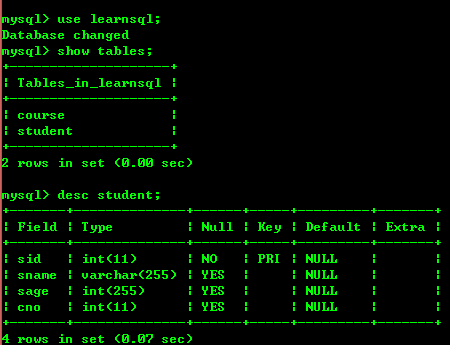
2.5:查询数据库的表 show tables
2.6:查询表结构 desc +表名
2.7:查询创建表的sql语句 show create table +表名
2.8:删除表 drop +表名
2.9:一次删除多条表记录:delete t1,t2 from t1,t2[where 条件] 如果from后面用别名那么delete后面也需要用别名
3.0:一次性更新多次表update t1,t2 ...tn set t1.field=expr1,tn.exprn=exprn;
三:查询
3.1:select普通查询
在这里我创建了一个数据放了2个表,看下图

3.2:查询不重复记录
用关键字distinct如下图

3.3:排序和限制
用关键字order by进行排序desc降序asc升序,limit关键字进行限制输出

order by后面跟字段(order by只写一次即可先排第一个字段然后第二个以此类推,limit 后面第一个数是索性,第二个是输出的个数)。
四:聚合操作
很多情况下,用户都需要进行一些统计,比如统计整个公司的人数或者部门的人数,这时就会用到聚合操作。聚合操作语法入戏下
select 【field1,field2...fieldn】fun_name from 表名
where 条件
group by field1,field2...fieldn
with rollup
having 条件
fun_name叫做聚合函数或者聚合操作,常见的有sum(求和)、 count(*)记录数、 max(最大值)、min(最小值)。
group by 表示要分类聚合的字段,比如按照部门分类统计的员工数量,部门就应该写在group by后面
with rollup 是可选语法,表示是否对分类聚合后的结合在进行汇总
having 表示对分类后的结果在次进行筛选
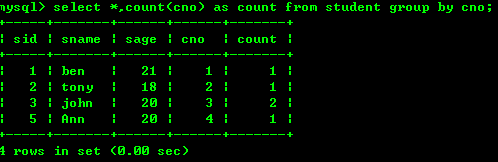
4.1:按照课程号进行统计班级的人数
4.2:按年级统计人数,并统计总人数
rollup就是进行人数汇总的,从图中我们可以看出。
4.3:统计年龄不小于20的人数
having和where的区别:having是对聚合后的结果进行筛选,而where是在聚合钱就对记录进行筛选,如果逻辑允许,尽可能使用where先过滤记录,这样将减少结果集,对聚合的效率大大的提高,然后在根据having进行过滤。
五:表连接
如果需要同时显示多个表中的字段的时候,就可以使用表连接来实现这样的功能。从大类上可以分为内连接和外连接,他们的主要区别是:内连接仅仅筛选出2个表互相匹配的记录,而外连接会筛选出其他不匹配的记录,我们经常使用的是内连接。
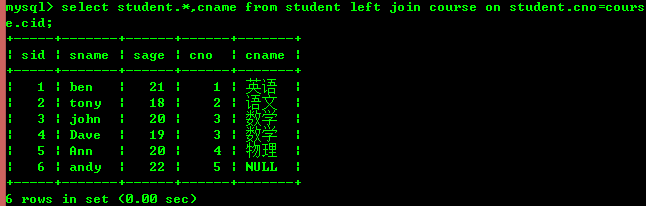
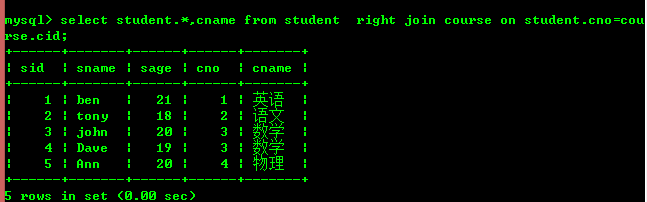
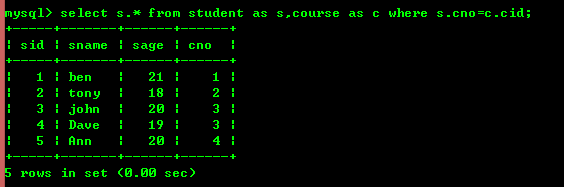
5.1:查询学生所选择的课程
外连接又分为左连接和右连接。
左连接(包含所有左边表中的记录甚至右边表中没有和它匹配的记录)
右连接(包含所有右边表中的记录甚至左边表中没有和它匹配的记录)
从中可以看出左连接是以左边的表为主,右连接是以右边的表为主。
六:子查询
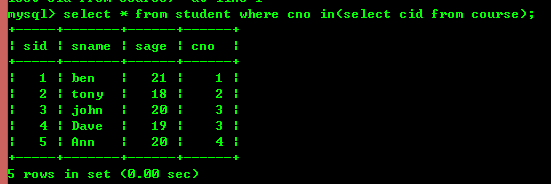
某些情况下,当进行查询的时候,需要的条件是另外一个select语句的结果,这个时候就用到了子查询,用于子查询的关键字主要包括in、not in、=、!=、exist、not exist等
如使用in进行查询
但是使用内连接同样能达到以上的效果
但是内连接的效率在很多情况下都是高于子查询的,所以如果不影响业务逻辑的前提下优先考虑内联。
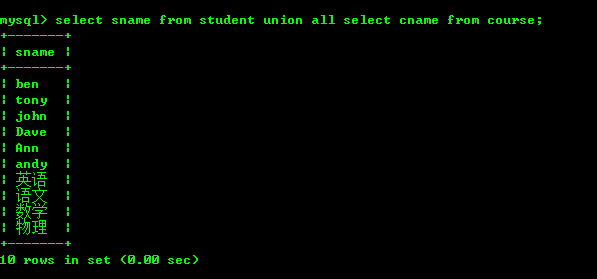
七:联合
将2个表的数据按照一定规则下查询出来,将结果合并一起显示出来。这个时候我们就可以使用union或者union all。具体语法如下
select * from t1 unionunion all select * from t2 unionunion all select * from tn;
union和union all的区别在于union是在筛选的结果集去除重复的记录。
切记不可以2个表不匹配就进行联合,如下
如果我们每个表都查询2个字段
八:常见的函数
8.1:concat
cancat函数:把传入的参数连成一个字符串,任何字符串和null进行拼接的结果都是null,如下图
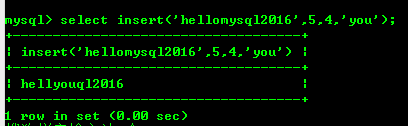
8.2:insert(str,x,y,instr)函数,将字符串str从第X个位置开始,y个字符长的字符串替换成instr下面把字符串hellomysql2016的第5个字符后面的4个字符替换成you
8.3:Lower(Str)和Upper(Str)把字符串转换成小写或者大写。

8.4:left(str,x)和right(str,x)分别返回字符串最左边的x个字符和最右边的x个字符,如果第二个参数为null,不返回任何字符
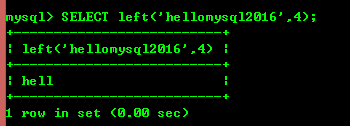
8.5:ltrim(str)和rtrim(str)去掉字符串左边或者右边的字符
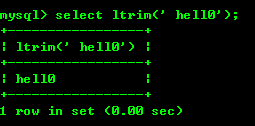
8.6:repeat(str,x):返回str重复x次的结果
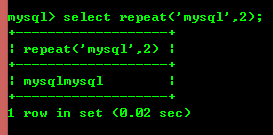
8.7:replace(str,a,b)用字符串b替换字符串str中所有出现字符串a。
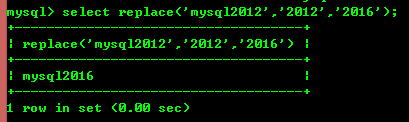
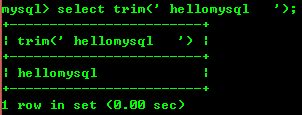
8.8:trim(str)去掉开头和结尾的空格
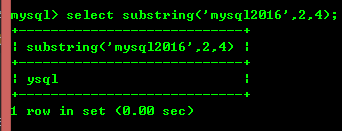
8.9:substring(str,x,y):返回从字符串str中的第x个位置起y个字符串长度的字符串。
参考的资料是深入浅出的mysql。