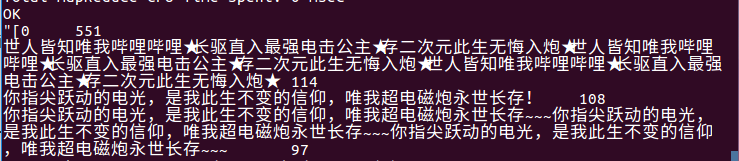
作业要求来源:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE1/homework/3363
大数据分析:
1.将爬虫大作业产生的csv文件上传到HDFS
Python爬取到的数据:
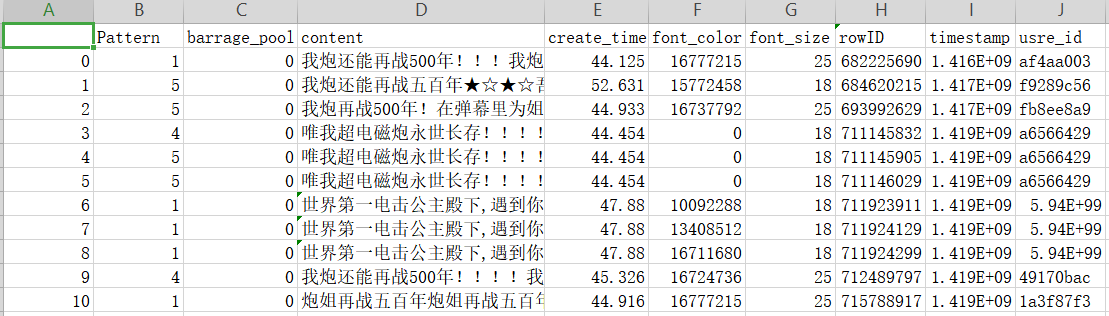
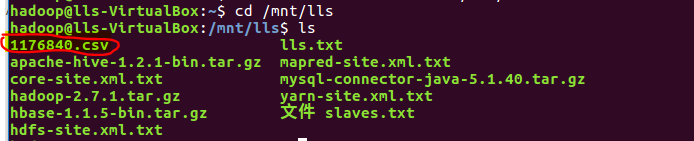
(1)首先创建一个用于运行本案例的目录bigdatacase

(2)在本地查看数据集
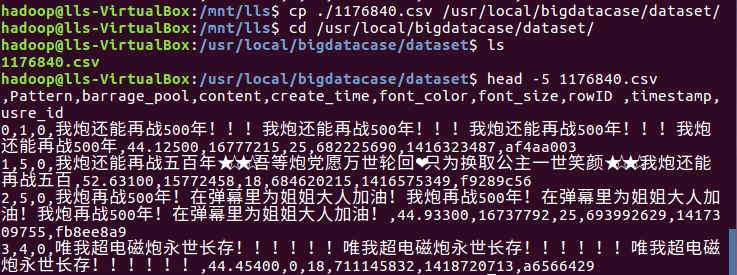
2.对CSV文件进行预处理生成无标题文本文件

3.把上传到hdfs中的文本文件最终导入到数据仓库Hive中
(1)首先通过start-all.sh命令启动进程
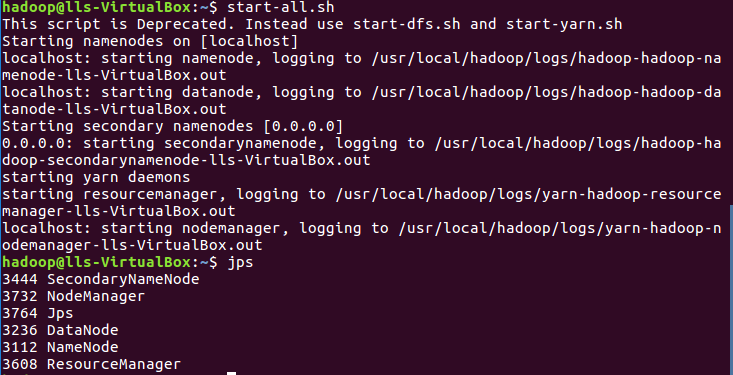
(2)上传并查看文件


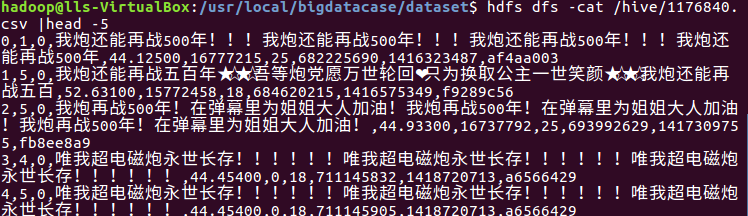
4.在Hive中查看并分析数据
(1)创建表comment

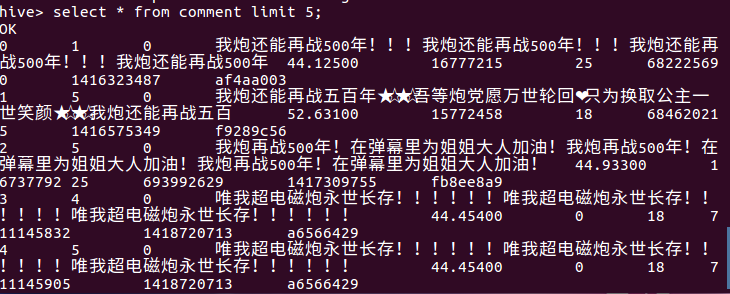
(2)查看前comment表前10行数据
5.用Hive对爬虫大作业产生的进行数据分析,写一篇博客描述你的分析过程和分析结果。(10条以上的查询分析)
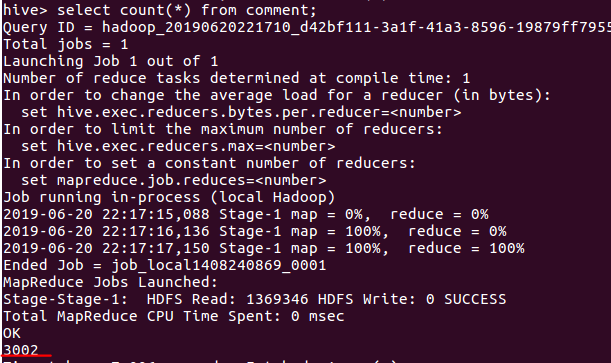
(1)查询数据总数目
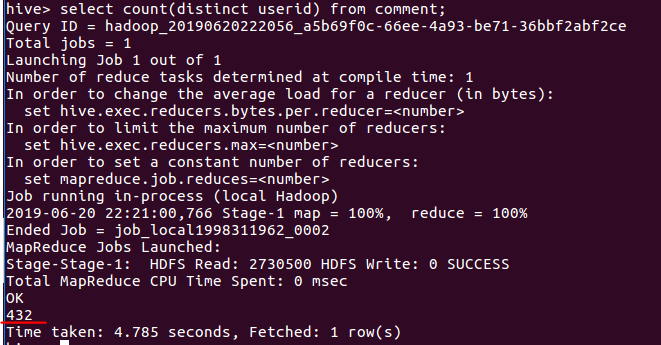
(2)查询userid(用户id)不重复的数据数目
(3)查询content(弹幕内容)不重复的数据数目

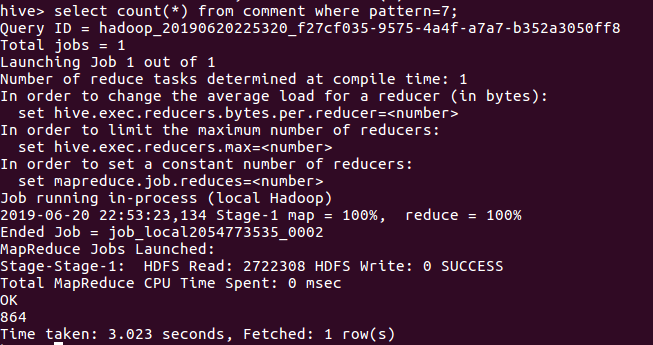
(4)查询pattern值为7的数据数目(弹幕的模式:1..3 滚动弹幕 4底端弹幕 5顶端弹幕 6.逆向弹幕 7精准定位 8高级弹幕)
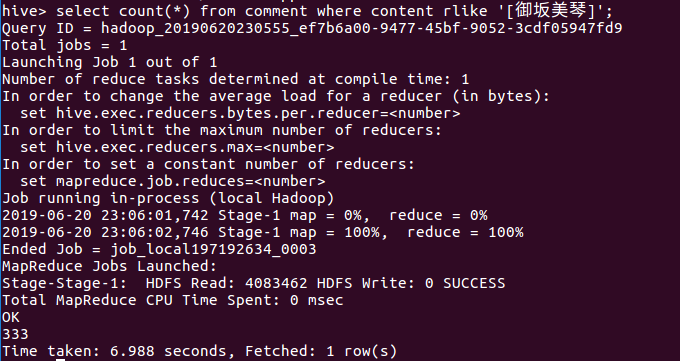
(5)查询content(弹幕内容)包含'御坂美琴'的数据数目
(6)查询pattern(弹幕模式:1..3 滚动弹幕 4底端弹幕 5顶端弹幕 6.逆向弹幕 7精准定位 8高级弹幕)各个模式的数目(降序)


(7)查询content(弹幕内容)出现频率最高top4