本次作业要求来自于:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE1/homework/3223
1.安装Linux
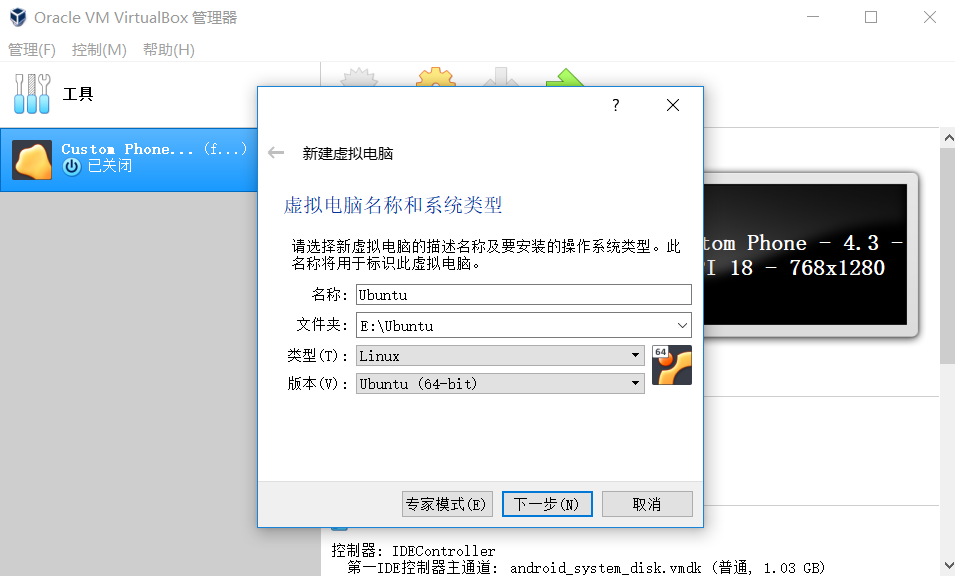
(1)虚拟机命名,选择操作系统,版本
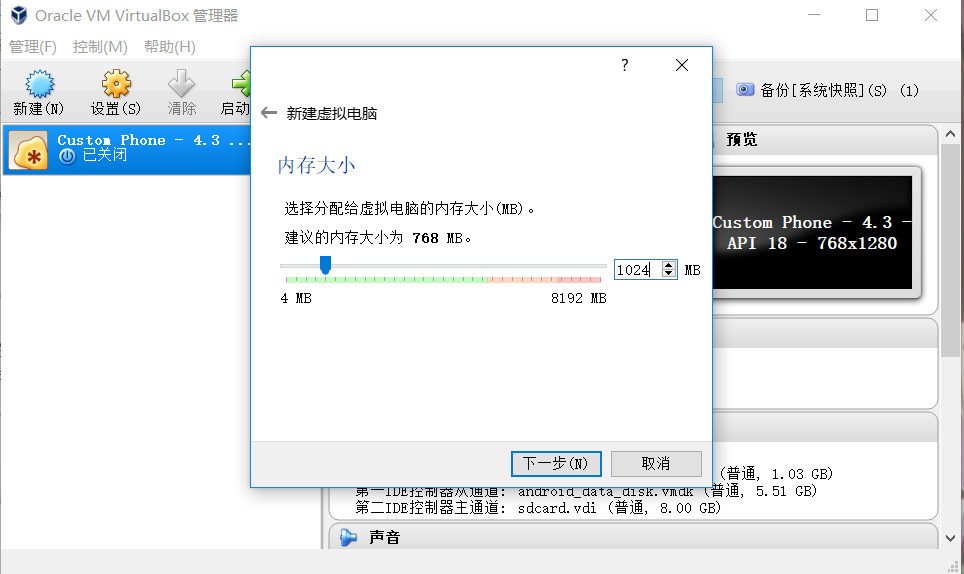
(2)选择内存大小
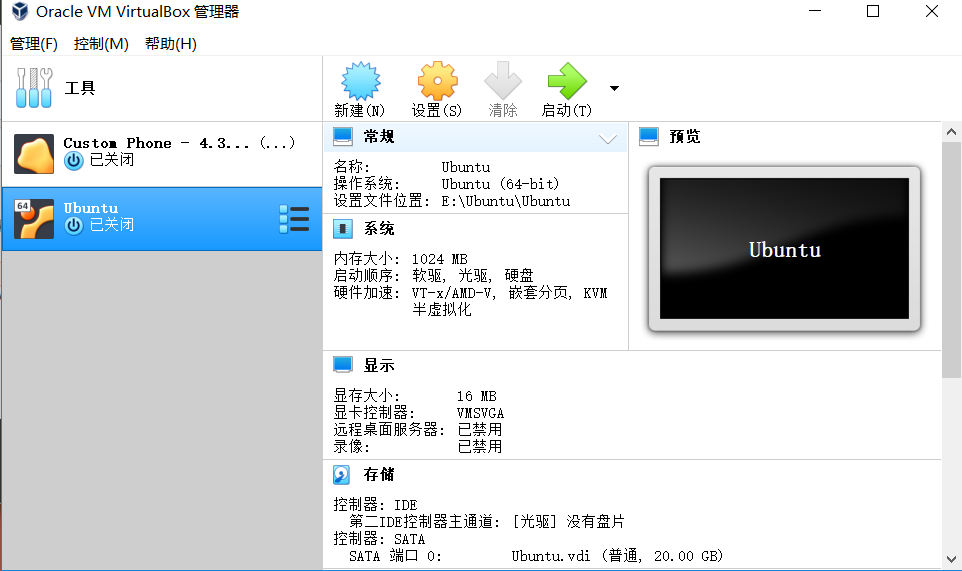
(3)启动Ubuntu
(4)添加镜像文件
(5)开始安装Ubuntu
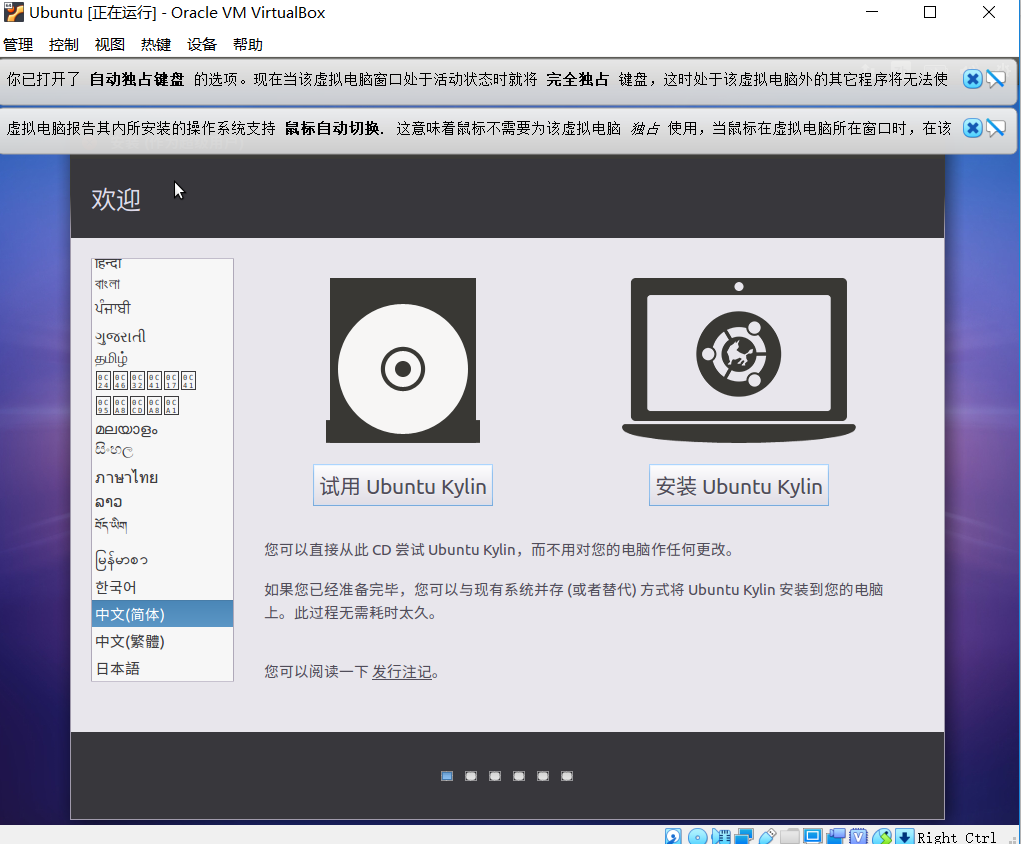
(6)新建分区表
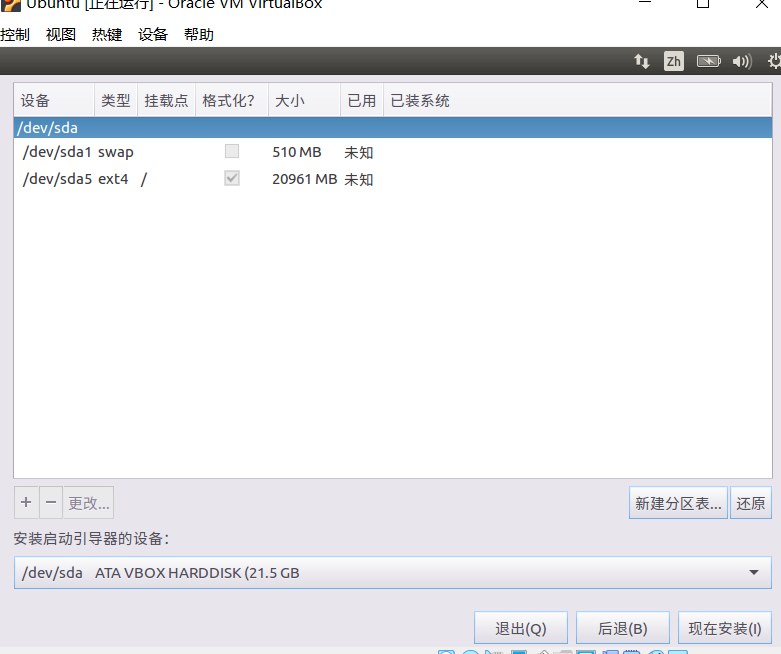
(7)设置用户名和密码
(8)用户登录
2.安装MySql
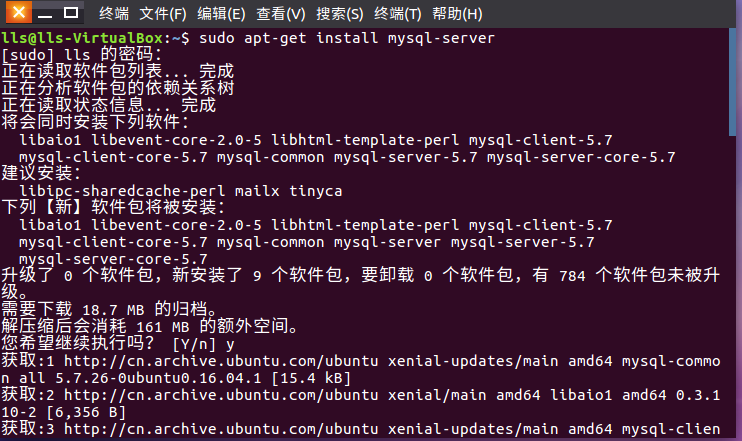
(1)开始安装mysql
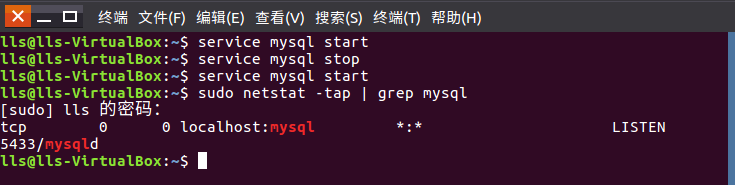
(2)启动与关闭mysql数据库,检查是否启动成功
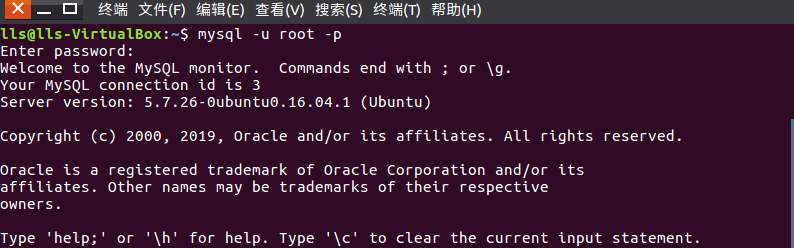
(3)进入mysql
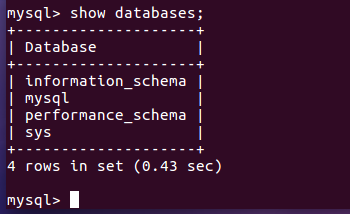
(4)显示数据库
3.windows 与 虚拟机互传文件
(1)在本机系统设置一个共享文件夹,用于与Ubuntu交互的区域空间。

(2)设置共享配置
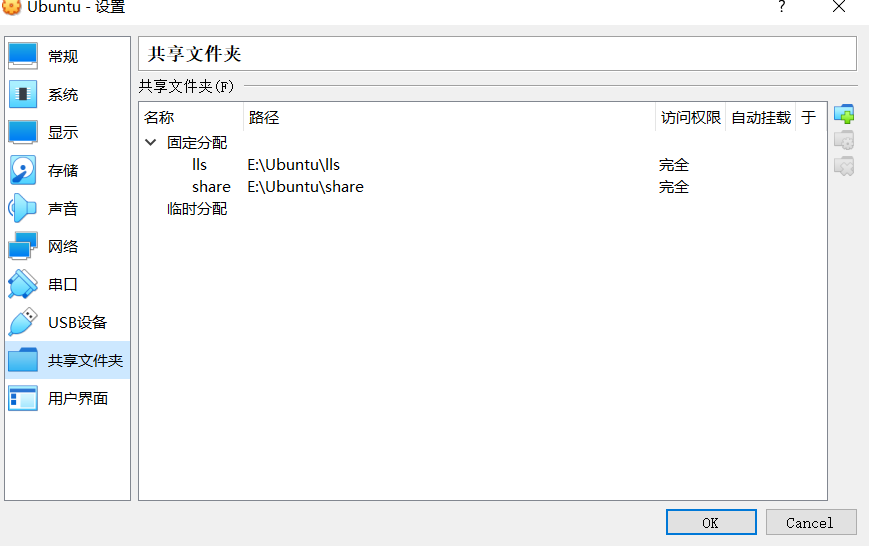
(3)共享成功

4.安装Hadoop
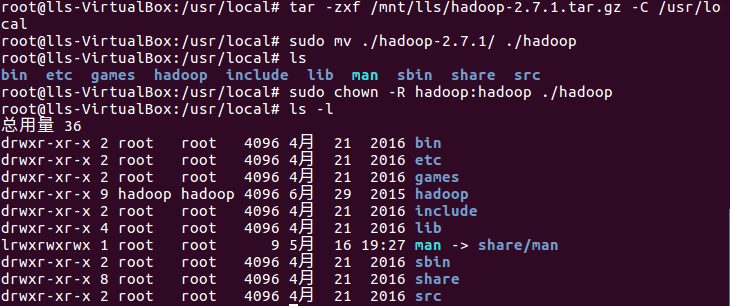
(1)解压hadoop-2.7.1到/usr/local 重命名为hadoop并修改Hadoop权限
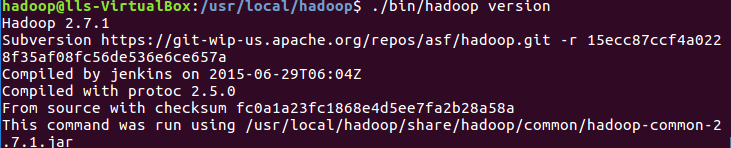
检查Hadoop是否可用
(2)创建hadoop用户,设置用户名和密码,最后添加管理员权限



(3)安装ssh,实现无密码登录
1)执行 ssh localhost 命令,需要密码登录

2)利用 ssh-keygen 生成秘钥,并将秘钥加入授权
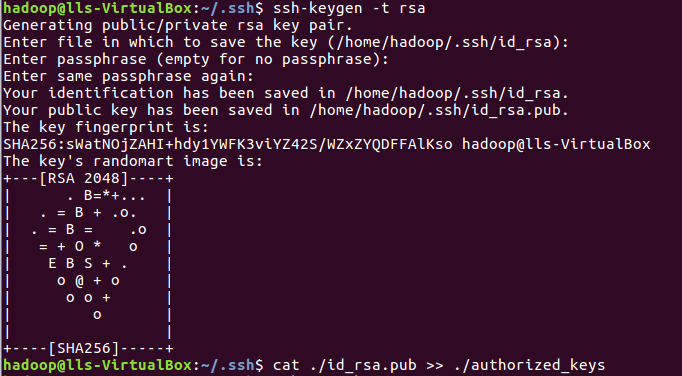
3)再用执行ssh localhost 命令,实现无密登陆

(4)配置java环境
1)安装java环境

2)使用命令 gedit ~/.bashrc 配置环境变量

3)添加 export JAVA_HOME

4)使用 source ~/.bashrc 命令使环境变量生效,并检查配置是否正确

(5)运行Hadoop单机模式
1)创建输入文件

2)运行grep例子
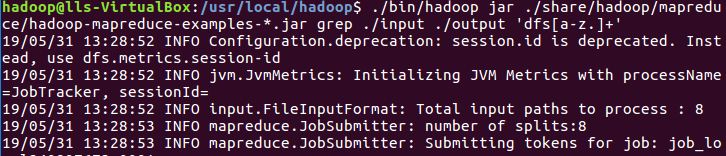
3)查看运行结果

4)Hadoop默认不会覆盖结果文件,再次运行上面实例会提示错误,现将 ./output 删除

(6)Hadoop伪分布式配置
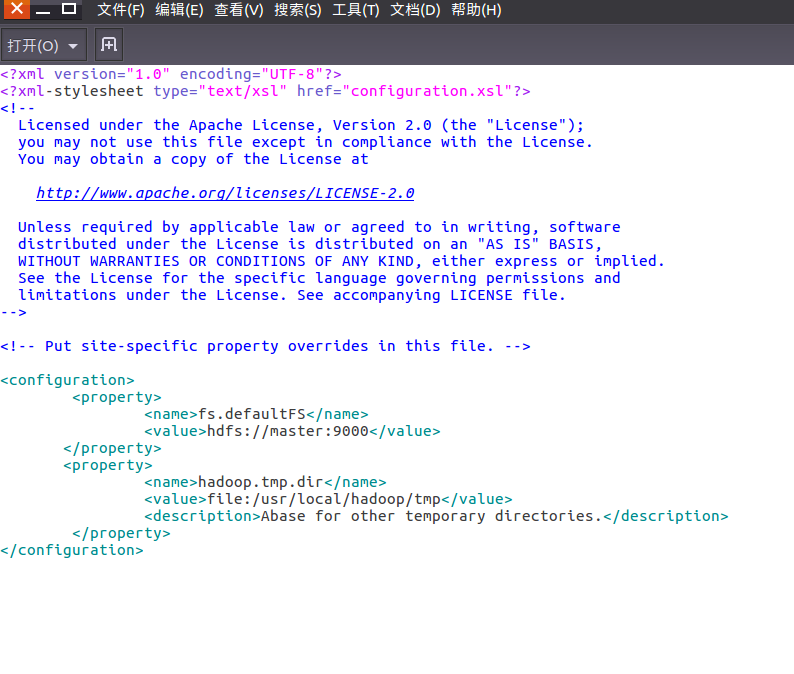
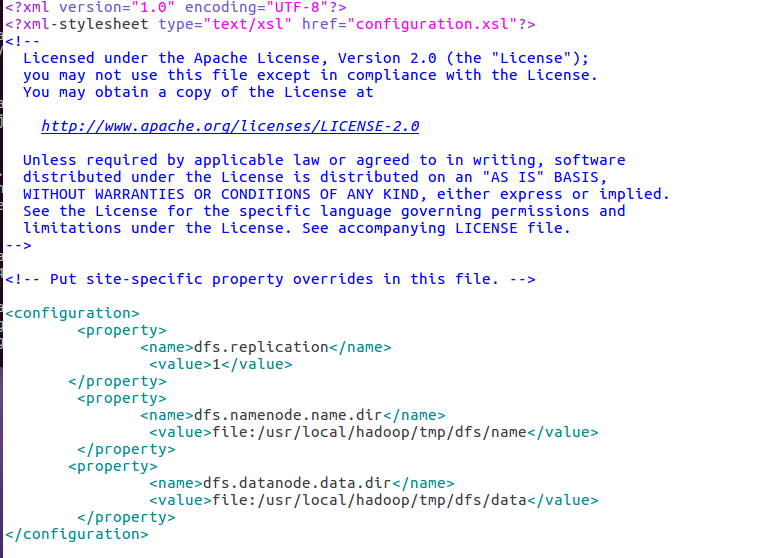
Hadoop配置文件位于 /usr/local/hadoop/etc/hadoop/ 中,伪分布式需要修改配置文件有 core-site.xml 和 hdfs-site.xml
1)修改配置文件 core-site.xml

2)修改配置文件 hdfs-site.xml

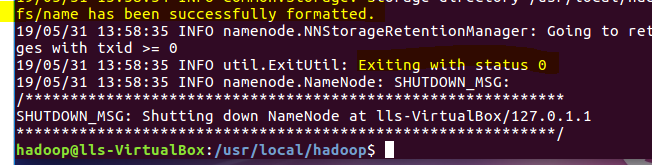
3)文件配置完成后,执行NameNode格式化

成功的话会有successfully formatted和Exiting with status 0 的提示,若为Exiting with status 1则出错
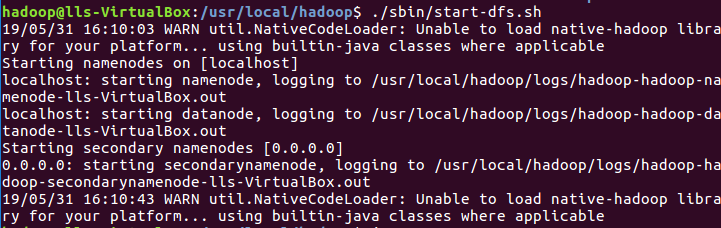
4)开启NameNode和DataNode的守护进程,若出现SSH提示,输入yes即可
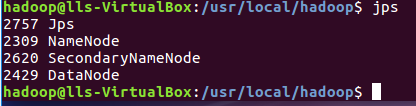
5)通过jps命令来判断是否启动成功(若成功启动则会列出如下进程: “NameNode”、”DataNode” 和 “SecondaryNameNode”,如果 SecondaryNameNode 没有启动,请运行 sbin/stop-dfs.sh 关闭进程,然后再次尝试启动尝试。如果没有 NameNode 或 DataNode ,那就是配置不成功,请仔细检查之前步骤,或通过查看启动日志排查原因。)。如果DataNode无法启动,先删除hadoop.tmp.dir(路径为 /usr/local/hadoop/tmp目录, 再执行hadoop namenode -format