原文出处:http://www.cnblogs.com/peida/archive/2012/12/05/2803591.html。感谢作者无私分享
性能监控和优化命令相关指令有:top,free,vmstat,isotat,lsof。。。。
top命令是Linux下常用的性能分析工具,能够实时显示系统中各个进程的资源占用状况,类似于Windows的任务管理器。下面详细介绍它的使用方法。top是一个动态显示过程,即可以通过用户按键来不断刷新当前状态.如果在前台执行该命令,它将独占前台,直到用户终止该程序为止.比较准确的说,top命令提供了实时的对系统处理器的状态监视.它将显示系统中CPU最“敏感”的任务列表.该命令可以按CPU使用.内存使用和执行时间对任务进行排序;而且该命令的很多特性都可以通过交互式命令或者在个人定制文件中进行设定.
1.命令格式:
top [参数]
2.命令功能:
显示当前系统正在执行的进程的相关信息,包括进程ID、内存占用率、CPU占用率等
3.命令参数:
-b 批处理
-c 显示完整的治命令
-I 忽略失效过程
-s 保密模式
-S 累积模式
-i<时间> 设置间隔时间
-u<用户名> 指定用户名
-p<进程号> 指定进程
-n<次数> 循环显示的次数
4.使用实例:
实例1:显示进程信息
命令:
top
输出:
[root@TG1704 log]# top
top - 14:06:23 up 70 days, 16:44, 2 users, load average: 1.25, 1.32, 1.35
Tasks: 206 total, 1 running, 205 sleeping, 0 stopped, 0 zombie
Cpu(s): 5.9%us, 3.4%sy, 0.0%ni, 90.4%id, 0.0%wa, 0.0%hi, 0.2%si, 0.0%st
Mem: 32949016k total, 14411180k used, 18537836k free, 169884k buffers
Swap: 32764556k total, 0k used, 32764556k free, 3612636k cached
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
28894 root 22 0 1501m 405m 10m S 52.2 1.3 2534:16 java
18249 root 18 0 3201m 1.9g 11m S 35.9 6.0 569:39.41 java
2808 root 25 0 3333m 1.0g 11m S 24.3 3.1 526:51.85 java
25668 root 23 0 3180m 704m 11m S 14.0 2.2 360:44.53 java
574 root 25 0 3168m 611m 10m S 12.6 1.9 556:59.63 java
1599 root 20 0 3237m 1.9g 11m S 12.3 6.2 262:01.14 java
1008 root 21 0 3147m 842m 10m S 0.3 2.6 4:31.08 java
13823 root 23 0 3031m 2.1g 10m S 0.3 6.8 176:57.34 java
28218 root 15 0 12760 1168 808 R 0.3 0.0 0:01.43 top
29062 root 20 0 1241m 227m 10m S 0.3 0.7 2:07.32 java
1 root 15 0 10368 684 572 S 0.0 0.0 1:30.85 init
2 root RT -5 0 0 0 S 0.0 0.0 0:01.01 migration/0
3 root 34 19 0 0 0 S 0.0 0.0 0:00.00 ksoftirqd/0
4 root RT -5 0 0 0 S 0.0 0.0 0:00.00 watchdog/0
5 root RT -5 0 0 0 S 0.0 0.0 0:00.80 migration/1
6 root 34 19 0 0 0 S 0.0 0.0 0:00.00 ksoftirqd/1
7 root RT -5 0 0 0 S 0.0 0.0 0:00.00 watchdog/1
8 root RT -5 0 0 0 S 0.0 0.0 0:20.59 migration/2
9 root 34 19 0 0 0 S 0.0 0.0 0:00.09 ksoftirqd/2
10 root RT -5 0 0 0 S 0.0 0.0 0:00.00 watchdog/2
11 root RT -5 0 0 0 S 0.0 0.0 0:23.66 migration/3
12 root 34 19 0 0 0 S 0.0 0.0 0:00.03 ksoftirqd/3
13 root RT -5 0 0 0 S 0.0 0.0 0:00.00 watchdog/3
14 root RT -5 0 0 0 S 0.0 0.0 0:20.29 migration/4
15 root 34 19 0 0 0 S 0.0 0.0 0:00.07 ksoftirqd/4
16 root RT -5 0 0 0 S 0.0 0.0 0:00.00 watchdog/4
17 root RT -5 0 0 0 S 0.0 0.0 0:23.07 migration/5
18 root 34 19 0 0 0 S 0.0 0.0 0:00.07 ksoftirqd/5
19 root RT -5 0 0 0 S 0.0 0.0 0:00.00 watchdog/5
20 root RT -5 0 0 0 S 0.0 0.0 0:17.16 migration/6
21 root 34 19 0 0 0 S 0.0 0.0 0:00.05 ksoftirqd/6
22 root RT -5 0 0 0 S 0.0 0.0 0:00.00 watchdog/6
23 root RT -5 0 0 0 S 0.0 0.0 0:58.28 migration/7
说明:
统计信息区:
前五行是当前系统情况整体的统计信息区。下面我们看每一行信息的具体意义。
第一行,任务队列信息,同 uptime 命令的执行结果,具体参数说明情况如下:
14:06:23 — 当前系统时间
up 70 days, 16:44 — 系统已经运行了70天16小时44分钟(在这期间系统没有重启过的吆!)
2 users — 当前有2个用户登录系统
load average: 1.15, 1.42, 1.44 — load average后面的三个数分别是1分钟、5分钟、15分钟的负载情况。
load average数据是每隔5秒钟检查一次活跃的进程数,然后按特定算法计算出的数值。如果这个数除以逻辑CPU的数量,结果高于5的时候就表明系统在超负荷运转了。
第二行,Tasks — 任务(进程),具体信息说明如下:
系统现在共有206个进程,其中处于运行中的有1个,205个在休眠(sleep),stoped状态的有0个,zombie状态(僵尸)的有0个。
第三行,cpu状态信息,具体属性说明如下:
5.9%us — 用户空间占用CPU的百分比。
3.4% sy — 内核空间占用CPU的百分比。
0.0% ni — 改变过优先级的进程占用CPU的百分比
90.4% id — 空闲CPU百分比
0.0% wa — IO等待占用CPU的百分比
0.0% hi — 硬中断(Hardware IRQ)占用CPU的百分比
0.2% si — 软中断(Software Interrupts)占用CPU的百分比
备注:在这里CPU的使用比率和windows概念不同,需要理解linux系统用户空间和内核空间的相关知识!
第四行,内存状态,具体信息如下:
32949016k total — 物理内存总量(32GB)
14411180k used — 使用中的内存总量(14GB)
18537836k free — 空闲内存总量(18GB)
169884k buffers — 缓存的内存量 (169M)
第五行,swap交换分区信息,具体信息说明如下:
32764556k total — 交换区总量(32GB)
0k used — 使用的交换区总量(0K)
32764556k free — 空闲交换区总量(32GB)
3612636k cached — 缓冲的交换区总量(3.6GB)
备注:
第四行中使用中的内存总量(used)指的是现在系统内核控制的内存数,空闲内存总量(free)是内核还未纳入其管控范围的数量。纳入内核管理的内存不见得都在使用中,还包括过去使用过的现在可以被重复利用的内存,内核并不把这些可被重新使用的内存交还到free中去,因此在linux上free内存会越来越少,但不用为此担心。
如果出于习惯去计算可用内存数,这里有个近似的计算公式:第四行的free + 第四行的buffers + 第五行的cached,按这个公式此台服务器的可用内存:18537836k +169884k +3612636k = 22GB左右。
对于内存监控,在top里我们要时刻监控第五行swap交换分区的used,如果这个数值在不断的变化,说明内核在不断进行内存和swap的数据交换,这是真正的内存不够用了。
第六行,空行。
第七行以下:各进程(任务)的状态监控,项目列信息说明如下:
PID — 进程id
USER — 进程所有者
PR — 进程优先级
NI — nice值。负值表示高优先级,正值表示低优先级
VIRT — 进程使用的虚拟内存总量,单位kb。VIRT=SWAP+RES
RES — 进程使用的、未被换出的物理内存大小,单位kb。RES=CODE+DATA
SHR — 共享内存大小,单位kb
S — 进程状态。D=不可中断的睡眠状态 R=运行 S=睡眠 T=跟踪/停止 Z=僵尸进程
%CPU — 上次更新到现在的CPU时间占用百分比
%MEM — 进程使用的物理内存百分比
TIME+ — 进程使用的CPU时间总计,单位1/100秒
COMMAND — 进程名称(命令名/命令行)
其他使用技巧:
1.多U多核CPU监控
在top基本视图中,按键盘数字“1”,可监控每个逻辑CPU的状况:
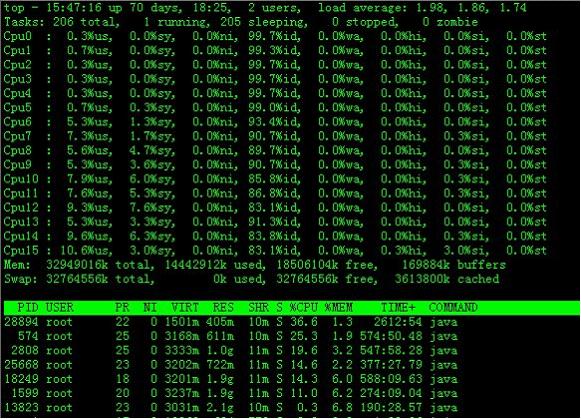
观察上图,服务器有16个逻辑CPU,实际上是4个物理CPU。再按数字键1,就会返回到top基本视图界面。
2.高亮显示当前运行进程
敲击键盘“b”(打开/关闭加亮效果),top的视图变化如下:
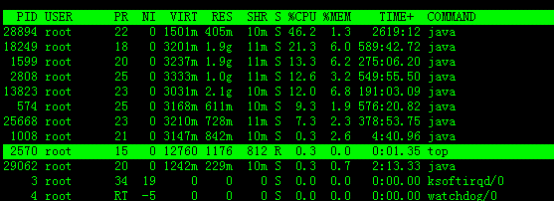
我们发现进程id为2570的“top”进程被加亮了,top进程就是视图第二行显示的唯一的运行态(runing)的那个进程,可以通过敲击“y”键关闭或打开运行态进程的加亮效果。
3.进程字段排序
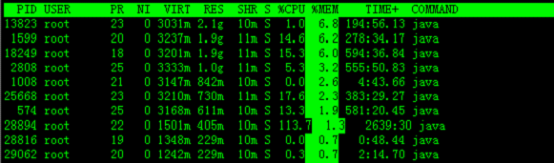
默认进入top时,各进程是按照CPU的占用量来排序的,在下图中进程ID为28894的java进程排在第一(cpu占用142%),进程ID为574的java进程排在第二(cpu占用16%)。
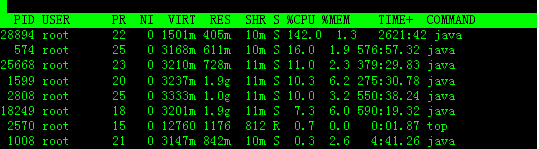
敲击键盘“x”(打开/关闭排序列的加亮效果),top的视图变化如下:
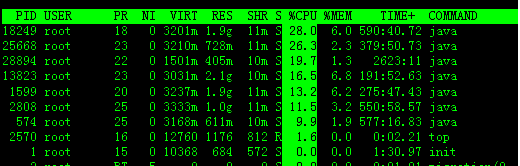
可以看到,top默认的排序列是“%CPU”。
4. 通过”shift + >”或”shift + <”可以向右或左改变排序列
下图是按一次”shift + >”的效果图,视图现在已经按照%MEM来排序。
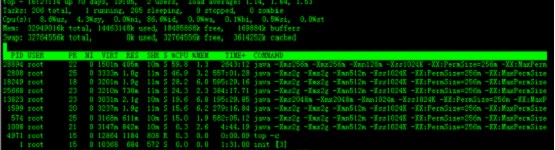
实例2:显示 完整命令
命令:
top -c
输出:
说明:
实例3:以批处理模式显示程序信息
命令:
top -b
输出:
说明:
实例4:以累积模式显示程序信息
命令:
top -S
输出:
说明:
实例5:设置信息更新次数
命令:
top -n 2
输出:
说明:
表示更新两次后终止更新显示
实例6:设置信息更新时间
命令:
top -d 3
输出:
说明:
表示更新周期为3秒
实例7:显示指定的进程信息
命令:
top -p 574
输出:
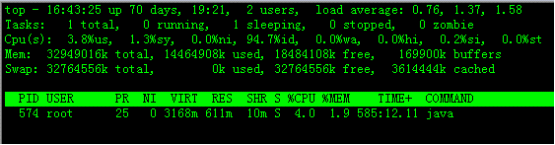
说明:
5.top交互命令
在top 命令执行过程中可以使用的一些交互命令。这些命令都是单字母的,如果在命令行中使用了s 选项, 其中一些命令可能会被屏蔽。
h 显示帮助画面,给出一些简短的命令总结说明
k 终止一个进程。
i 忽略闲置和僵死进程。这是一个开关式命令。
q 退出程序
r 重新安排一个进程的优先级别
S 切换到累计模式
s 改变两次刷新之间的延迟时间(单位为s),如果有小数,就换算成m s。输入0值则系统将不断刷新,默认值是5 s
f或者F 从当前显示中添加或者删除项目
o或者O 改变显示项目的顺序
l 切换显示平均负载和启动时间信息
m 切换显示内存信息
t 切换显示进程和CPU状态信息
c 切换显示命令名称和完整命令行
M 根据驻留内存大小进行排序
P 根据CPU使用百分比大小进行排序
T 根据时间/累计时间进行排序
W 将当前设置写入~/.toprc文件中
free命令可以显示Linux系统中空闲的、已用的物理内存及swap内存,及被内核使用的buffer。在Linux系统监控的工具中,free命令是最经常使用的命令之一。
1.命令格式:
free [参数]
2.命令功能:
free 命令显示系统使用和空闲的内存情况,包括物理内存、交互区内存(swap)和内核缓冲区内存。共享内存将被忽略
3.命令参数:
-b 以Byte为单位显示内存使用情况。
-k 以KB为单位显示内存使用情况。
-m 以MB为单位显示内存使用情况。
-g 以GB为单位显示内存使用情况。
-o 不显示缓冲区调节列。
-s<间隔秒数> 持续观察内存使用状况。
-t 显示内存总和列。
-V 显示版本信息。
4.使用实例:
实例1:显示内存使用情况
命令:
free
free -g
free -m
输出:
[root@SF1150 service]# free
total used free shared buffers cached
Mem: 32940112 30841684 2098428 0 4545340 11363424
-/+ buffers/cache: 14932920 18007192
Swap: 32764556 1944984 30819572
[root@SF1150 service]# free -g
total used free shared buffers cached
Mem: 31 29 2 0 4 10
-/+ buffers/cache: 14 17
Swap: 31 1 29
[root@SF1150 service]# free -m
total used free shared buffers cached
Mem: 32168 30119 2048 0 4438 11097
-/+ buffers/cache: 14583 17584
Swap: 31996 1899 30097
说明:
下面是对这些数值的解释:
total:总计物理内存的大小。
used:已使用多大。
free:可用有多少。
Shared:多个进程共享的内存总额。
Buffers/cached:磁盘缓存的大小。
第三行(-/+ buffers/cached):
used:已使用多大。
free:可用有多少。
第四行是交换分区SWAP的,也就是我们通常所说的虚拟内存。
区别:第二行(mem)的used/free与第三行(-/+ buffers/cache) used/free的区别。 这两个的区别在于使用的角度来看,第一行是从OS的角度来看,因为对于OS,buffers/cached 都是属于被使用,所以他的可用内存是2098428KB,已用内存是30841684KB,其中包括,内核(OS)使用+Application(X, oracle,etc)使用的+buffers+cached.
第三行所指的是从应用程序角度来看,对于应用程序来说,buffers/cached 是等于可用的,因为buffer/cached是为了提高文件读取的性能,当应用程序需在用到内存的时候,buffer/cached会很快地被回收。
所以从应用程序的角度来说,可用内存=系统free memory+buffers+cached。
如本机情况的可用内存为:
18007156=2098428KB+4545340KB+11363424KB
接下来解释什么时候内存会被交换,以及按什么方交换。
当可用内存少于额定值的时候,就会开会进行交换.如何看额定值:
命令:
cat /proc/meminfo
输出:
[root@SF1150 service]# cat /proc/meminfo
MemTotal: 32940112 kB
MemFree: 2096700 kB
Buffers: 4545340 kB
Cached: 11364056 kB
SwapCached: 1896080 kB
Active: 22739776 kB
Inactive: 7427836 kB
HighTotal: 0 kB
HighFree: 0 kB
LowTotal: 32940112 kB
LowFree: 2096700 kB
SwapTotal: 32764556 kB
SwapFree: 30819572 kB
Dirty: 164 kB
Writeback: 0 kB
AnonPages: 14153592 kB
Mapped: 20748 kB
Slab: 590232 kB
PageTables: 34200 kB
NFS_Unstable: 0 kB
Bounce: 0 kB
CommitLimit: 49234612 kB
Committed_AS: 23247544 kB
VmallocTotal: 34359738367 kB
VmallocUsed: 278840 kB
VmallocChunk: 34359459371 kB
HugePages_Total: 0HugePages_Free: 0HugePages_Rsvd: 0Hugepagesize: 2048 kB
交换将通过三个途径来减少系统中使用的物理页面的个数:
1.减少缓冲与页面cache的大小,
2.将系统V类型的内存页面交换出去,
3.换出或者丢弃页面。(Application 占用的内存页,也就是物理内存不足)。
事实上,少量地使用swap是不是影响到系统性能的。
那buffers和cached都是缓存,两者有什么区别呢?
为了提高磁盘存取效率, Linux做了一些精心的设计, 除了对dentry进行缓存(用于VFS,加速文件路径名到inode的转换), 还采取了两种主要Cache方式:Buffer Cache和Page Cache。前者针对磁盘块的读写,后者针对文件inode的读写。这些Cache有效缩短了 I/O系统调用(比如read,write,getdents)的时间。
磁盘的操作有逻辑级(文件系统)和物理级(磁盘块),这两种Cache就是分别缓存逻辑和物理级数据的。
Page cache实际上是针对文件系统的,是文件的缓存,在文件层面上的数据会缓存到page cache。文件的逻辑层需要映射到实际的物理磁盘,这种映射关系由文件系统来完成。当page cache的数据需要刷新时,page cache中的数据交给buffer cache,因为Buffer Cache就是缓存磁盘块的。但是这种处理在2.6版本的内核之后就变的很简单了,没有真正意义上的cache操作。
Buffer cache是针对磁盘块的缓存,也就是在没有文件系统的情况下,直接对磁盘进行操作的数据会缓存到buffer cache中,例如,文件系统的元数据都会缓存到buffer cache中。
简单说来,page cache用来缓存文件数据,buffer cache用来缓存磁盘数据。在有文件系统的情况下,对文件操作,那么数据会缓存到page cache,如果直接采用dd等工具对磁盘进行读写,那么数据会缓存到buffer cache。
所以我们看linux,只要不用swap的交换空间,就不用担心自己的内存太少.如果常常swap用很多,可能你就要考虑加物理内存了.这也是linux看内存是否够用的标准.
如果是应用服务器的话,一般只看第二行,+buffers/cache,即对应用程序来说free的内存太少了,也是该考虑优化程序或加内存了。
实例2:以总和的形式显示内存的使用信息
命令:
free -t
输出:
[root@SF1150 service]# free -t
total used free shared buffers cached
Mem: 32940112 30845024 2095088 0 4545340 11364324
-/+ buffers/cache: 14935360 18004752Swap: 32764556 1944984 30819572Total: 65704668 32790008 32914660[root@SF1150 service]#
说明:
实例3:周期性的查询内存使用信息
命令:
free -s 10
输出:
[root@SF1150 service]# free -s 10
total used free shared buffers cached
Mem: 32940112 30844528 2095584 0 4545340 11364380
-/+ buffers/cache: 14934808 18005304Swap: 32764556 1944984 30819572
total used free shared buffers cached
Mem: 32940112 30843932 2096180 0 4545340 11364388
-/+ buffers/cache: 14934204 18005908Swap: 32764556 1944984 30819572
说明:
每10s 执行一次命令
vmstat是Virtual Meomory Statistics(虚拟内存统计)的缩写,可对操作系统的虚拟内存、进程、CPU活动进行监控。他是对系统的整体情况进行统计,不足之处是无法对某个进程进行深入分析。vmstat 工具提供了一种低开销的系统性能观察方式。因为 vmstat 本身就是低开销工具,在非常高负荷的服务器上,你需要查看并监控系统的健康情况,在控制窗口还是能够使用vmstat 输出结果。在学习vmstat命令前,我们先了解一下Linux系统中关于物理内存和虚拟内存相关信息。
物理内存和虚拟内存区别:
我们知道,直接从物理内存读写数据要比从硬盘读写数据要快的多,因此,我们希望所有数据的读取和写入都在内存完成,而内存是有限的,这样就引出了物理内存与虚拟内存的概念。
物理内存就是系统硬件提供的内存大小,是真正的内存,相对于物理内存,在linux下还有一个虚拟内存的概念,虚拟内存就是为了满足物理内存的不足而提出的策略,它是利用磁盘空间虚拟出的一块逻辑内存,用作虚拟内存的磁盘空间被称为交换空间(Swap Space)。
作为物理内存的扩展,linux会在物理内存不足时,使用交换分区的虚拟内存,更详细的说,就是内核会将暂时不用的内存块信息写到交换空间,这样以来,物理内存得到了释放,这块内存就可以用于其它目的,当需要用到原始的内容时,这些信息会被重新从交换空间读入物理内存。
linux的内存管理采取的是分页存取机制,为了保证物理内存能得到充分的利用,内核会在适当的时候将物理内存中不经常使用的数据块自动交换到虚拟内存中,而将经常使用的信息保留到物理内存。
要深入了解linux内存运行机制,需要知道下面提到的几个方面:
首先,Linux系统会不时的进行页面交换操作,以保持尽可能多的空闲物理内存,即使并没有什么事情需要内存,Linux也会交换出暂时不用的内存页面。这可以避免等待交换所需的时间。
其次,linux进行页面交换是有条件的,不是所有页面在不用时都交换到虚拟内存,linux内核根据”最近最经常使用“算法,仅仅将一些不经常使用的页面文件交换到虚拟内存,有时我们会看到这么一个现象:linux物理内存还有很多,但是交换空间也使用了很多。其实,这并不奇怪,例如,一个占用很大内存的进程运行时,需要耗费很多内存资源,此时就会有一些不常用页面文件被交换到虚拟内存中,但后来这个占用很多内存资源的进程结束并释放了很多内存时,刚才被交换出去的页面文件并不会自动的交换进物理内存,除非有这个必要,那么此刻系统物理内存就会空闲很多,同时交换空间也在被使用,就出现了刚才所说的现象了。关于这点,不用担心什么,只要知道是怎么一回事就可以了。
最后,交换空间的页面在使用时会首先被交换到物理内存,如果此时没有足够的物理内存来容纳这些页面,它们又会被马上交换出去,如此以来,虚拟内存中可能没有足够空间来存储这些交换页面,最终会导致linux出现假死机、服务异常等问题,linux虽然可以在一段时间内自行恢复,但是恢复后的系统已经基本不可用了。
因此,合理规划和设计linux内存的使用,是非常重要的。
虚拟内存原理:
在系统中运行的每个进程都需要使用到内存,但不是每个进程都需要每时每刻使用系统分配的内存空间。当系统运行所需内存超过实际的物理内存,内核会释放某些进程所占用但未使用的部分或所有物理内存,将这部分资料存储在磁盘上直到进程下一次调用,并将释放出的内存提供给有需要的进程使用。
在Linux内存管理中,主要是通过“调页Paging”和“交换Swapping”来完成上述的内存调度。调页算法是将内存中最近不常使用的页面换到磁盘上,把活动页面保留在内存中供进程使用。交换技术是将整个进程,而不是部分页面,全部交换到磁盘上。
分页(Page)写入磁盘的过程被称作Page-Out,分页(Page)从磁盘重新回到内存的过程被称作Page-In。当内核需要一个分页时,但发现此分页不在物理内存中(因为已经被Page-Out了),此时就发生了分页错误(Page Fault)。
当系统内核发现可运行内存变少时,就会通过Page-Out来释放一部分物理内存。经管Page-Out不是经常发生,但是如果Page-out频繁不断的发生,直到当内核管理分页的时间超过运行程式的时间时,系统效能会急剧下降。这时的系统已经运行非常慢或进入暂停状态,这种状态亦被称作thrashing(颠簸)。
1.命令格式:
vmstat [-a] [-n] [-S unit] [delay [ count]]
vmstat [-s] [-n] [-S unit]
vmstat [-m] [-n] [delay [ count]]
vmstat [-d] [-n] [delay [ count]]
vmstat [-p disk partition] [-n] [delay [ count]]
vmstat [-f]
vmstat [-V]
2.命令功能:
用来显示虚拟内存的信息
3.命令参数:
-a:显示活跃和非活跃内存
-f:显示从系统启动至今的fork数量 。
-m:显示slabinfo
-n:只在开始时显示一次各字段名称。
-s:显示内存相关统计信息及多种系统活动数量。
delay:刷新时间间隔。如果不指定,只显示一条结果。
count:刷新次数。如果不指定刷新次数,但指定了刷新时间间隔,这时刷新次数为无穷。
-d:显示磁盘相关统计信息。
-p:显示指定磁盘分区统计信息
-S:使用指定单位显示。参数有 k 、K 、m 、M ,分别代表1000、1024、1000000、1048576字节(byte)。默认单位为K(1024 bytes)
-V:显示vmstat版本信息。
4.使用实例:
实例1:显示虚拟内存使用情况
命令:
vmstat
输出:

procs -----------memory---------- ---swap-- -----io---- --system-- -----cpu------
r b swpd free buff cache si so bi bo in cs us sy id wa st
0 0 0 3029876 199616 690980 0 0 0 2 3 2 0 0 100 0 0
0 0 0 3029752 199616 690980 0 0 0 41 1009 39 0 0 100 0 0
0 0 0 3029752 199616 690980 0 0 0 3 1004 36 0 0 100 0 0
0 0 0 3029752 199616 690980 0 0 0 4 1004 36 0 0 100 0 0
0 0 0 3029752 199616 690980 0 0 0 6 1003 33 0 0 100 0 0
0 0 0 3029752 199616 690980 0 0 0 5 1003 33 0 0 100 0 0
说明:
字段说明:
Procs(进程):
r: 运行队列中进程数量
b: 等待IO的进程数量
Memory(内存):
swpd: 使用虚拟内存大小
free: 可用内存大小
buff: 用作缓冲的内存大小
cache: 用作缓存的内存大小
Swap:
si: 每秒从交换区写到内存的大小
so: 每秒写入交换区的内存大小
IO:(现在的Linux版本块的大小为1024bytes)
bi: 每秒读取的块数
bo: 每秒写入的块数
系统:
in: 每秒中断数,包括时钟中断。
cs: 每秒上下文切换数。
CPU(以百分比表示):
us: 用户进程执行时间(user time)
sy: 系统进程执行时间(system time)
id: 空闲时间(包括IO等待时间),中央处理器的空闲时间 。以百分比表示。
wa: 等待IO时间
备注: 如果 r经常大于 4 ,且id经常少于40,表示cpu的负荷很重。如果pi,po 长期不等于0,表示内存不足。如果disk 经常不等于0, 且在 b中的队列 大于3, 表示 io性能不好。Linux在具有高稳定性、可靠性的同时,具有很好的可伸缩性和扩展性,能够针对不同的应用和硬件环境调整,优化出满足当前应用需要的最佳性能。因此企业在维护Linux系统、进行系统调优时,了解系统性能分析工具是至关重要的。
命令:
vmstat 5 5
表示在5秒时间内进行5次采样。将得到一个数据汇总他能够反映真正的系统情况。
实例2:显示活跃和非活跃内存
命令:
vmstat -a 2 5
输出:
procs -----------memory---------- ---swap-- -----io---- --system-- -----cpu------
r b swpd free inact active si so bi bo in cs us sy id wa st
0 0 0 3029752 387728 513008 0 0 0 2 3 2 0 0 100 0 0
0 0 0 3029752 387728 513076 0 0 0 0 1005 34 0 0 100 0 0
0 0 0 3029752 387728 513076 0 0 0 22 1004 36 0 0 100 0 0
0 0 0 3029752 387728 513076 0 0 0 0 1004 33 0 0 100 0 0
0 0 0 3029752 387728 513076 0 0 0 0 1003 32 0 0 100 0 0
[root@localhost ~]#
说明:
使用-a选项显示活跃和非活跃内存时,所显示的内容除增加inact和active外,其他显示内容与例子1相同。
字段说明:
Memory(内存):
inact: 非活跃内存大小(当使用-a选项时显示)
active: 活跃的内存大小(当使用-a选项时显示)
实例3:查看系统已经fork了多少次
命令:
vmstat -f
输出:
[root@SCF1129 ~]# vmstat -f
12744849 forks
[root@SCF1129 ~]#
说明:
这个数据是从/proc/stat中的processes字段里取得的
实例4:查看内存使用的详细信息
命令:
vmstat -s
输出:
4043760 total memory
1013884 used memory
513012 active memory
387728 inactive memory
3029876 free memory
199616 buffer memory
690980 swap cache
6096656 total swap
0 used swap
6096656 free swap
83587 non-nice user cpu ticks
132 nice user cpu ticks
278599 system cpu ticks
913344692 idle cpu ticks
814550 IO-wait cpu ticks
10547 IRQ cpu ticks
21261 softirq cpu ticks
0 stolen cpu ticks
310215 pages paged in
14254652 pages paged out
0 pages swapped in
0 pages swapped out
288374745 interrupts
146680577 CPU context switches
1351868832 boot time
367291 forks
说明:
这些信息的分别来自于/proc/meminfo,/proc/stat和/proc/vmstat。
实例5:查看磁盘的读/写
命令:
vmstat -d
输出:
disk- ------------reads------------ ------------writes----------- -----IO------
total merged sectors ms total merged sectors ms cur sec
ram0 0 0 0 0 0 0 0 0 0 0
ram1 0 0 0 0 0 0 0 0 0 0
ram2 0 0 0 0 0 0 0 0 0 0
ram3 0 0 0 0 0 0 0 0 0 0
ram4 0 0 0 0 0 0 0 0 0 0
ram5 0 0 0 0 0 0 0 0 0 0
ram6 0 0 0 0 0 0 0 0 0 0
ram7 0 0 0 0 0 0 0 0 0 0
ram8 0 0 0 0 0 0 0 0 0 0
ram9 0 0 0 0 0 0 0 0 0 0
ram10 0 0 0 0 0 0 0 0 0 0
ram11 0 0 0 0 0 0 0 0 0 0
ram12 0 0 0 0 0 0 0 0 0 0
ram13 0 0 0 0 0 0 0 0 0 0
ram14 0 0 0 0 0 0 0 0 0 0
ram15 0 0 0 0 0 0 0 0 0 0
sda 33381 6455 615407 63224 2068111 1495416 28508288 15990289 0 10491
hdc 0 0 0 0 0 0 0 0 0 0
fd0 0 0 0 0 0 0 0 0 0 0
md0 0 0 0 0 0 0 0 0 0 0
[root@localhost ~]#
说明:
这些信息主要来自于/proc/diskstats.
merged:表示一次来自于合并的写/读请求,一般系统会把多个连接/邻近的读/写请求合并到一起来操作.
实例6:查看/dev/sda1磁盘的读/写
命令:
输出:
[root@SCF1129 ~]# df
文件系统 1K-块 已用 可用 已用% 挂载点
/dev/sda3 1119336548 27642068 1034835500 3% /tmpfs 32978376 0 32978376 0% /dev/shm
/dev/sda1 1032088 59604 920056 7% /boot
[root@SCF1129 ~]# vmstat -p /dev/sda1
sda1 reads read sectors writes requested writes
18607 4249978 6 48[root@SCF1129 ~]# vmstat -p /dev/sda3
sda3 reads read sectors writes requested writes
429350 35176268 28998789 980301488[root@SCF1129 ~]#
说明:
这些信息主要来自于/proc/diskstats。
reads:来自于这个分区的读的次数。
read sectors:来自于这个分区的读扇区的次数。
writes:来自于这个分区的写的次数。
requested writes:来自于这个分区的写请求次数。
实例7:查看系统的slab信息
命令:
vmstat -m
输出:
Cache Num Total Size Pages
ip_conntrack_expect 0 0 136 28
ip_conntrack 3 13 304 13
ip_fib_alias 11 59 64 59
ip_fib_hash 11 59 64 59
AF_VMCI 0 0 960 4
bio_map_info 100 105 1064 7
dm_mpath 0 0 1064 7
jbd_4k 0 0 4096 1
dm_uevent 0 0 2608 3
dm_tio 0 0 24 144
dm_io 0 0 48 77
scsi_cmd_cache 10 10 384 10
sgpool-128 32 32 4096 1
sgpool-64 32 32 2048 2
sgpool-32 32 32 1024 4
sgpool-16 32 32 512 8
sgpool-8 45 45 256 15
scsi_io_context 0 0 112 34
ext3_inode_cache 51080 51105 760 5
ext3_xattr 36 88 88 44
journal_handle 18 144 24 144
journal_head 56 80 96 40
revoke_table 4 202 16 202
revoke_record 0 0 32 112
uhci_urb_priv 0 0 56 67
UNIX 13 33 704 11
flow_cache 0 0 128 30
msi_cache 33 59 64 59
cfq_ioc_pool 14 90 128 30
cfq_pool 12 90 216 18
crq_pool 16 96 80 48
deadline_drq 0 0 80 48
as_arq 0 0 96 40
mqueue_inode_cache 1 4 896 4
isofs_inode_cache 0 0 608 6
hugetlbfs_inode_cache 1 7 576 7
Cache Num Total Size Pages
ext2_inode_cache 0 0 720 5
ext2_xattr 0 0 88 44
dnotify_cache 0 0 40 92
dquot 0 0 256 15
eventpoll_pwq 3 53 72 53
eventpoll_epi 3 20 192 20
inotify_event_cache 0 0 40 92
inotify_watch_cache 1 53 72 53
kioctx 0 0 320 12
kiocb 0 0 256 15
fasync_cache 0 0 24 144
shmem_inode_cache 254 290 768 5
posix_timers_cache 0 0 128 30
uid_cache 0 0 128 30
ip_mrt_cache 0 0 128 30
tcp_bind_bucket 3 112 32 112
inet_peer_cache 0 0 128 30
secpath_cache 0 0 64 59
xfrm_dst_cache 0 0 384 10
ip_dst_cache 5 10 384 10
arp_cache 1 15 256 15
RAW 3 5 768 5
UDP 5 10 768 5
tw_sock_TCP 0 0 192 20
request_sock_TCP 0 0 128 30
TCP 4 5 1600 5
blkdev_ioc 14 118 64 59
blkdev_queue 20 30 1576 5
blkdev_requests 13 42 272 14
biovec-256 7 7 4096 1
biovec-128 7 8 2048 2
biovec-64 7 8 1024 4
biovec-16 7 15 256 15
biovec-4 7 59 64 59
biovec-1 23 202 16 202
bio 270 270 128 30
utrace_engine_cache 0 0 64 59
Cache Num Total Size Pages
utrace_cache 0 0 64 59
sock_inode_cache 33 48 640 6
skbuff_fclone_cache 7 7 512 7
skbuff_head_cache 319 390 256 15
file_lock_cache 1 22 176 22
Acpi-Operand 4136 4248 64 59
Acpi-ParseExt 0 0 64 59
Acpi-Parse 0 0 40 92
Acpi-State 0 0 80 48
Acpi-Namespace 2871 2912 32 112
delayacct_cache 81 295 64 59
taskstats_cache 4 53 72 53
proc_inode_cache 1427 1440 592 6
sigqueue 0 0 160 24
radix_tree_node 13166 13188 536 7
bdev_cache 23 24 832 4
sysfs_dir_cache 5370 5412 88 44
mnt_cache 26 30 256 15
inode_cache 2009 2009 560 7
dentry_cache 60952 61020 216 18
filp 479 1305 256 15
names_cache 3 3 4096 1
avc_node 14 53 72 53
selinux_inode_security 994 1200 80 48
key_jar 2 20 192 20
idr_layer_cache 74 77 528 7
buffer_head 164045 164800 96 40
mm_struct 51 56 896 4
vm_area_struct 1142 1958 176 22
fs_cache 35 177 64 59
files_cache 36 55 768 5
signal_cache 72 162 832 9
sighand_cache 68 84 2112 3
task_struct 76 80 1888 2
anon_vma 458 864 24 144
pid 83 295 64 59
shared_policy_node 0 0 48 77
Cache Num Total Size Pages
numa_policy 37 144 24 144
size-131072(DMA) 0 0 131072 1
size-131072 0 0 131072 1
size-65536(DMA) 0 0 65536 1
size-65536 1 1 65536 1
size-32768(DMA) 0 0 32768 1
size-32768 2 2 32768 1
size-16384(DMA) 0 0 16384 1
size-16384 5 5 16384 1
size-8192(DMA) 0 0 8192 1
size-8192 7 7 8192 1
size-4096(DMA) 0 0 4096 1
size-4096 110 111 4096 1
size-2048(DMA) 0 0 2048 2
size-2048 602 602 2048 2
size-1024(DMA) 0 0 1024 4
size-1024 344 352 1024 4
size-512(DMA) 0 0 512 8
size-512 433 480 512 8
size-256(DMA) 0 0 256 15
size-256 1139 1155 256 15
size-128(DMA) 0 0 128 30
size-64(DMA) 0 0 64 59
size-64 5639 5782 64 59
size-32(DMA) 0 0 32 112
size-128 801 930 128 30
size-32 3005 3024 32 112
kmem_cache 137 137 2688 1
这组信息来自于/proc/slabinfo。
slab:由于内核会有许多小对象,这些对象构造销毁十分频繁,比如i-node,dentry,这些对象如果每次构建的时候就向内存要一个页(4kb),而其实只有几个字节,这样就会非常浪费,为了解决这个问题,就引入了一种新的机制来处理在同一个页框中如何分配小存储区,而slab可以对小对象进行分配,这样就不用为每一个对象分配页框,从而节省了空间,内核对一些小对象创建析构很频繁,slab对这些小对象进行缓冲,可以重复利用,减少内存分配次数。
Linux系统中的 iostat是I/O statistics(输入/输出统计)的缩写,iostat工具将对系统的磁盘操作活动进行监视。它的特点是汇报磁盘活动统计情况,同时也会汇报出CPU使用情况。同vmstat一样,iostat也有一个弱点,就是它不能对某个进程进行深入分析,仅对系统的整体情况进行分析。iostat属于sysstat软件包。可以用yum install sysstat 直接安装。
1.命令格式:
iostat[参数][时间][次数]
2.命令功能:
通过iostat方便查看CPU、网卡、tty设备、磁盘、CD-ROM 等等设备的活动情况, 负载信息。
3.命令参数:
-C 显示CPU使用情况
-d 显示磁盘使用情况
-k 以 KB 为单位显示
-m 以 M 为单位显示
-N 显示磁盘阵列(LVM) 信息
-n 显示NFS 使用情况
-p[磁盘] 显示磁盘和分区的情况
-t 显示终端和CPU的信息
-x 显示详细信息
-V 显示版本信息
4.使用实例:
实例1:显示所有设备负载情况
命令:
iostat
输出:
Linux 2.6.18-128.el5 (CT1186) 2012年12月28日
avg-cpu: %user %nice %system %iowait %steal %idle
8.30 0.02 5.07 0.17 0.00 86.44
Device: tps Blk_read/s Blk_wrtn/s Blk_read Blk_wrtn
sda 22.73 43.70 487.42 674035705 7517941952
sda1 0.00 0.00 0.00 2658 536
sda2 0.11 3.74 3.51 57721595 54202216
sda3 0.98 0.61 17.51 9454172 270023368
sda4 0.00 0.00 0.00 6 0
sda5 6.95 0.12 108.73 1924834 1677123536
sda6 2.20 0.18 31.22 2837260 481488056
sda7 12.48 39.04 326.45 602094508 5035104240
说明:
cpu属性值说明:
%user:CPU处在用户模式下的时间百分比。
%nice:CPU处在带NICE值的用户模式下的时间百分比。
%system:CPU处在系统模式下的时间百分比。
%iowait:CPU等待输入输出完成时间的百分比。
%steal:管理程序维护另一个虚拟处理器时,虚拟CPU的无意识等待时间百分比。
%idle:CPU空闲时间百分比。
备注:如果%iowait的值过高,表示硬盘存在I/O瓶颈,%idle值高,表示CPU较空闲,如果%idle值高但系统响应慢时,有可能是CPU等待分配内存,此时应加大内存容量。%idle值如果持续低于10,那么系统的CPU处理能力相对较低,表明系统中最需要解决的资源是CPU。
disk属性值说明:
rrqm/s: 每秒进行 merge 的读操作数目。即 rmerge/s
wrqm/s: 每秒进行 merge 的写操作数目。即 wmerge/s
r/s: 每秒完成的读 I/O 设备次数。即 rio/s
w/s: 每秒完成的写 I/O 设备次数。即 wio/s
rsec/s: 每秒读扇区数。即 rsect/s
wsec/s: 每秒写扇区数。即 wsect/s
rkB/s: 每秒读K字节数。是 rsect/s 的一半,因为每扇区大小为512字节。
wkB/s: 每秒写K字节数。是 wsect/s 的一半。
avgrq-sz: 平均每次设备I/O操作的数据大小 (扇区)。
avgqu-sz: 平均I/O队列长度。
await: 平均每次设备I/O操作的等待时间 (毫秒)。
svctm: 平均每次设备I/O操作的服务时间 (毫秒)。
%util: 一秒中有百分之多少的时间用于 I/O 操作,即被io消耗的cpu百分比
备注:如果 %util 接近 100%,说明产生的I/O请求太多,I/O系统已经满负荷,该磁盘可能存在瓶颈。如果 svctm 比较接近 await,说明 I/O 几乎没有等待时间;如果 await 远大于 svctm,说明I/O 队列太长,io响应太慢,则需要进行必要优化。如果avgqu-sz比较大,也表示有当量io在等待。
实例2:定时显示所有信息
命令:
iostat 2 3
输出:
Linux 2.6.18-128.el5 (CT1186) 2012年12月28日
avg-cpu: %user %nice %system %iowait %steal %idle
8.30 0.02 5.07 0.17 0.00 86.44
Device: tps Blk_read/s Blk_wrtn/s Blk_read Blk_wrtn
sda 22.73 43.70 487.42 674035705 7517947296
sda1 0.00 0.00 0.00 2658 536
sda2 0.11 3.74 3.51 57721595 54202216
sda3 0.98 0.61 17.51 9454172 270023608
sda4 0.00 0.00 0.00 6 0
sda5 6.95 0.12 108.73 1924834 1677125640
sda6 2.20 0.18 31.22 2837260 481488152
sda7 12.48 39.04 326.44 602094508 5035107144
avg-cpu: %user %nice %system %iowait %steal %idle
8.88 0.00 7.94 0.19 0.00 83.00
Device: tps Blk_read/s Blk_wrtn/s Blk_read Blk_wrtn
sda 6.00 0.00 124.00 0 248
sda1 0.00 0.00 0.00 0 0
sda2 0.00 0.00 0.00 0 0
sda3 0.00 0.00 0.00 0 0
sda4 0.00 0.00 0.00 0 0
sda5 0.00 0.00 0.00 0 0
sda6 0.00 0.00 0.00 0 0
sda7 6.00 0.00 124.00 0 248
avg-cpu: %user %nice %system %iowait %steal %idle
9.12 0.00 7.81 0.00 0.00 83.07
Device: tps Blk_read/s Blk_wrtn/s Blk_read Blk_wrtn
sda 4.00 0.00 84.00 0 168
sda1 0.00 0.00 0.00 0 0
sda2 0.00 0.00 0.00 0 0
sda3 0.00 0.00 0.00 0 0
sda4 0.00 0.00 0.00 0 0
sda5 0.00 0.00 0.00 0 0
sda6 4.00 0.00 84.00 0 168
sda7 0.00 0.00 0.00 0 0
说明:
每隔 2秒刷新显示,且显示3次
实例3:显示指定磁盘信息
命令:
iostat -d sda1
输出:
Linux 2.6.18-128.el5 (CT1186) 2012年12月28日
Device: tps Blk_read/s Blk_wrtn/s Blk_read Blk_wrtn
sda1 0.00 0.00 0.00 2658 536
说明:
实例4:显示tty和Cpu信息
命令:
iostat -t
输出:
Linux 2.6.18-128.el5 (CT1186) 2012年12月28日
Time: 14时58分35秒
avg-cpu: %user %nice %system %iowait %steal %idle
8.30 0.02 5.07 0.17 0.00 86.44
Device: tps Blk_read/s Blk_wrtn/s Blk_read Blk_wrtn
sda 22.73 43.70 487.41 674035705 7517957864
sda1 0.00 0.00 0.00 2658 536
sda2 0.11 3.74 3.51 57721595 54202216
sda3 0.98 0.61 17.51 9454172 270024344
sda4 0.00 0.00 0.00 6 0
sda5 6.95 0.12 108.73 1924834 1677128808
sda6 2.20 0.18 31.22 2837260 481488712
sda7 12.48 39.04 326.44 602094508 5035113248
说明:
实例5:以M为单位显示所有信息
命令:
iostat -m
输出:
Linux 2.6.18-128.el5 (CT1186) 2012年12月28日
avg-cpu: %user %nice %system %iowait %steal %idle
8.30 0.02 5.07 0.17 0.00 86.44
Device: tps MB_read/s MB_wrtn/s MB_read MB_wrtn
sda 22.72 0.02 0.24 329119 3670881
sda1 0.00 0.00 0.00 1 0
sda2 0.11 0.00 0.00 28184 26465
sda3 0.98 0.00 0.01 4616 131848
sda4 0.00 0.00 0.00 0 0
sda5 6.95 0.00 0.05 939 818911
sda6 2.20 0.00 0.02 1385 235102
sda7 12.48 0.02 0.16 293991 2458553
说明:
实例6:查看TPS和吞吐量信息
命令:
iostat -d -k 1 1
输出:
Linux 2.6.18-128.el5 (CT1186) 2012年12月28日
Device: tps kB_read/s kB_wrtn/s kB_read kB_wrtn
sda 22.72 21.85 243.71 337017916 3758984340
sda1 0.00 0.00 0.00 1329 268
sda2 0.11 1.87 1.76 28860797 27101108
sda3 0.98 0.31 8.75 4727086 135012508
sda4 0.00 0.00 0.00 3 0
sda5 6.95 0.06 54.37 962481 838566148
sda6 2.20 0.09 15.61 1418630 240744712
sda7 12.48 19.52 163.22 301047254 2517559596
说明:
tps:该设备每秒的传输次数(Indicate the number of transfers per second that were issued to the device.)。“一次传输”意思是“一次I/O请求”。多个逻辑请求可能会被合并为“一次I/O请求”。“一次传输”请求的大小是未知的。
kB_read/s:每秒从设备(drive expressed)读取的数据量;
kB_wrtn/s:每秒向设备(drive expressed)写入的数据量;
kB_read:读取的总数据量;kB_wrtn:写入的总数量数据量;
这些单位都为Kilobytes。
上面的例子中,我们可以看到磁盘sda以及它的各个分区的统计数据,当时统计的磁盘总TPS是22.73,下面是各个分区的TPS。(因为是瞬间值,所以总TPS并不严格等于各个分区TPS的总和)
实例7:查看设备使用率(%util)、响应时间(await)
命令:
iostat -d -x -k 1 1
输出:
Linux 2.6.18-128.el5 (CT1186) 2012年12月28日
Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await svctm %util
sda 0.44 38.59 0.40 22.32 21.85 243.71 23.37 0.04 1.78 4.20 9.54
sda1 0.00 0.00 0.00 0.00 0.00 0.00 18.90 0.00 8.26 6.46 0.00
sda2 0.36 0.43 0.11 0.01 1.87 1.76 63.57 0.01 63.75 1.94 0.02
sda3 0.00 1.24 0.04 0.95 0.31 8.75 18.42 0.04 39.77 8.73 0.86
sda4 0.00 0.00 0.00 0.00 0.00 0.00 2.00 0.00 19.67 19.67 0.00
sda5 0.00 6.65 0.00 6.94 0.06 54.37 15.67 0.26 36.81 4.48 3.11
sda6 0.00 1.71 0.01 2.19 0.09 15.61 14.29 0.03 12.40 5.84 1.28
sda7 0.08 28.56 0.25 12.24 19.52 163.22 29.28 0.27 21.46 5.00 6.25
说明:
rrqm/s: 每秒进行 merge 的读操作数目.即 delta(rmerge)/s
wrqm/s: 每秒进行 merge 的写操作数目.即 delta(wmerge)/s
r/s: 每秒完成的读 I/O 设备次数.即 delta(rio)/s
w/s: 每秒完成的写 I/O 设备次数.即 delta(wio)/s
rsec/s: 每秒读扇区数.即 delta(rsect)/s
wsec/s: 每秒写扇区数.即 delta(wsect)/s
rkB/s: 每秒读K字节数.是 rsect/s 的一半,因为每扇区大小为512字节.(需要计算)
wkB/s: 每秒写K字节数.是 wsect/s 的一半.(需要计算)
avgrq-sz:平均每次设备I/O操作的数据大小 (扇区).delta(rsect+wsect)/delta(rio+wio)
avgqu-sz:平均I/O队列长度.即 delta(aveq)/s/1000 (因为aveq的单位为毫秒).
await: 平均每次设备I/O操作的等待时间 (毫秒).即 delta(ruse+wuse)/delta(rio+wio)
svctm: 平均每次设备I/O操作的服务时间 (毫秒).即 delta(use)/delta(rio+wio)
%util: 一秒中有百分之多少的时间用于 I/O 操作,或者说一秒中有多少时间 I/O 队列是非空的,即 delta(use)/s/1000 (因为use的单位为毫秒)
如果 %util 接近 100%,说明产生的I/O请求太多,I/O系统已经满负荷,该磁盘可能存在瓶颈。
idle小于70% IO压力就较大了,一般读取速度有较多的wait。
同时可以结合vmstat 查看查看b参数(等待资源的进程数)和wa参数(IO等待所占用的CPU时间的百分比,高过30%时IO压力高)。
另外 await 的参数也要多和 svctm 来参考。差的过高就一定有 IO 的问题。
avgqu-sz 也是个做 IO 调优时需要注意的地方,这个就是直接每次操作的数据的大小,如果次数多,但数据拿的小的话,其实 IO 也会很小。如果数据拿的大,才IO 的数据会高。也可以通过 avgqu-sz × ( r/s or w/s ) = rsec/s or wsec/s。也就是讲,读定速度是这个来决定的。
svctm 一般要小于 await (因为同时等待的请求的等待时间被重复计算了),svctm 的大小一般和磁盘性能有关,CPU/内存的负荷也会对其有影响,请求过多也会间接导致 svctm 的增加。await 的大小一般取决于服务时间(svctm) 以及 I/O 队列的长度和 I/O 请求的发出模式。如果 svctm 比较接近 await,说明 I/O 几乎没有等待时间;如果 await 远大于 svctm,说明 I/O 队列太长,应用得到的响应时间变慢,如果响应时间超过了用户可以容许的范围,这时可以考虑更换更快的磁盘,调整内核 elevator 算法,优化应用,或者升级 CPU。
队列长度(avgqu-sz)也可作为衡量系统 I/O 负荷的指标,但由于 avgqu-sz 是按照单位时间的平均值,所以不能反映瞬间的 I/O 洪水。
形象的比喻:
r/s+w/s 类似于交款人的总数
平均队列长度(avgqu-sz)类似于单位时间里平均排队人的个数
平均服务时间(svctm)类似于收银员的收款速度
平均等待时间(await)类似于平均每人的等待时间
平均I/O数据(avgrq-sz)类似于平均每人所买的东西多少
I/O 操作率 (%util)类似于收款台前有人排队的时间比例
设备IO操作:总IO(io)/s = r/s(读) +w/s(写) =1.46 + 25.28=26.74
平均每次设备I/O操作只需要0.36毫秒完成,现在却需要10.57毫秒完成,因为发出的
请求太多(每秒26.74个),假如请求时同时发出的,可以这样计算平均等待时间:
平均等待时间=单个I/O服务器时间*(1+2+...+请求总数-1)/请求总数
每秒发出的I/0请求很多,但是平均队列就4,表示这些请求比较均匀,大部分处理还是比较及时。
实例8:查看cpu状态
命令:
iostat -c 1 3
输出:
Linux 2.6.18-128.el5 (CT1186) 2012年12月28日
avg-cpu: %user %nice %system %iowait %steal %idle
8.30 0.02 5.07 0.17 0.00 86.44
avg-cpu: %user %nice %system %iowait %steal %idle
8.64 0.00 5.38 0.00 0.00 85.98
avg-cpu: %user %nice %system %iowait %steal %idle
7.62 0.00 5.12 0.50 0.00 86.75
说明:
lsof(list open files)是一个列出当前系统打开文件的工具。在linux环境下,任何事物都以文件的形式存在,通过文件不仅仅可以访问常规数据,还可以访问网络连接和硬件。所以如传输控制协议 (TCP) 和用户数据报协议 (UDP) 套接字等,系统在后台都为该应用程序分配了一个文件描述符,无论这个文件的本质如何,该文件描述符为应用程序与基础操作系统之间的交互提供了通用接口。因为应用程序打开文件的描述符列表提供了大量关于这个应用程序本身的信息,因此通过lsof工具能够查看这个列表对系统监测以及排错将是很有帮助的。
1.命令格式:
lsof [参数][文件]
2.命令功能:
用于查看你进程开打的文件,打开文件的进程,进程打开的端口(TCP、UDP)。找回/恢复删除的文件。是十分方便的系统监视工具,因为 lsof 需要访问核心内存和各种文件,所以需要root用户执行。
lsof打开的文件可以是:
1.普通文件
2.目录
3.网络文件系统的文件
4.字符或设备文件
5.(函数)共享库
6.管道,命名管道
7.符号链接
8.网络文件(例如:NFS file、网络socket,unix域名socket)
9.还有其它类型的文件,等等
3.命令参数:
-a 列出打开文件存在的进程
-c<进程名> 列出指定进程所打开的文件
-g 列出GID号进程详情
-d<文件号> 列出占用该文件号的进程
+d<目录> 列出目录下被打开的文件
+D<目录> 递归列出目录下被打开的文件
-n<目录> 列出使用NFS的文件
-i<条件> 列出符合条件的进程。(4、6、协议、:端口、 @ip )
-p<进程号> 列出指定进程号所打开的文件
-u 列出UID号进程详情
-h 显示帮助信息
-v 显示版本信息
4.使用实例:
实例1:无任何参数
命令:
lsof
输出:
[root@localhost ~]# lsof
init 1 root cwd DIR 8,2 4096 2 /
init 1 root rtd DIR 8,2 4096 2 /
init 1 root txt REG 8,2 43496 6121706 /sbin/init
init 1 root mem REG 8,2 143600 7823908 /lib64/ld-2.5.so
init 1 root mem REG 8,2 1722304 7823915 /lib64/libc-2.5.so
init 1 root mem REG 8,2 23360 7823919 /lib64/libdl-2.5.so
init 1 root mem REG 8,2 95464 7824116 /lib64/libselinux.so.1
init 1 root mem REG 8,2 247496 7823947 /lib64/libsepol.so.1
init 1 root 10u FIFO 0,17 1233 /dev/initctl
migration 2 root cwd DIR 8,2 4096 2 /
migration 2 root rtd DIR 8,2 4096 2 /
migration 2 root txt unknown /proc/2/exe
ksoftirqd 3 root cwd DIR 8,2 4096 2 /
ksoftirqd 3 root rtd DIR 8,2 4096 2 /
ksoftirqd 3 root txt unknown /proc/3/exe
migration 4 root cwd DIR 8,2 4096 2 /
migration 4 root rtd DIR 8,2 4096 2 /
migration 4 root txt unknown /proc/4/exe
ksoftirqd 5 root cwd DIR 8,2 4096 2 /
ksoftirqd 5 root rtd DIR 8,2 4096 2 /
ksoftirqd 5 root txt unknown /proc/5/exe
events/0 6 root cwd DIR 8,2 4096 2 /
events/0 6 root rtd DIR 8,2 4096 2 /
events/0 6 root txt unknown /proc/6/exe
events/1 7 root cwd DIR 8,2 4096 2 /
说明:
lsof输出各列信息的意义如下:
COMMAND:进程的名称
PID:进程标识符
PPID:父进程标识符(需要指定-R参数)
USER:进程所有者
PGID:进程所属组
FD:文件描述符,应用程序通过文件描述符识别该文件。如cwd、txt等
(1)cwd:表示current work dirctory,即:应用程序的当前工作目录,这是该应用程序启动的目录,除非它本身对这个目录进行更改
(2)txt :该类型的文件是程序代码,如应用程序二进制文件本身或共享库,如上列表中显示的 /sbin/init 程序
(3)lnn:library references (AIX);
(4)er:FD information error (see NAME column);
(5)jld:jail directory (FreeBSD);
(6)ltx:shared library text (code and data);
(7)mxx :hex memory-mapped type number xx.
(8)m86:DOS Merge mapped file;
(9)mem:memory-mapped file;
(10)mmap:memory-mapped device;
(11)pd:parent directory;
(12)rtd:root directory;
(13)tr:kernel trace file (OpenBSD);
(14)v86 VP/ix mapped file;
(15)0:表示标准输出
(16)1:表示标准输入
(17)2:表示标准错误
一般在标准输出、标准错误、标准输入后还跟着文件状态模式:r、w、u等
(1)u:表示该文件被打开并处于读取/写入模式
(2)r:表示该文件被打开并处于只读模式
(3)w:表示该文件被打开并处于
(4)空格:表示该文件的状态模式为unknow,且没有锁定
(5)-:表示该文件的状态模式为unknow,且被锁定
同时在文件状态模式后面,还跟着相关的锁
(1)N:for a Solaris NFS lock of unknown type;
(2)r:for read lock on part of the file;
(3)R:for a read lock on the entire file;
(4)w:for a write lock on part of the file;(文件的部分写锁)
(5)W:for a write lock on the entire file;(整个文件的写锁)
(6)u:for a read and write lock of any length;
(7)U:for a lock of unknown type;
(8)x:for an SCO OpenServer Xenix lock on part of the file;
(9)X:for an SCO OpenServer Xenix lock on the entire file;
(10)space:if there is no lock.
TYPE:文件类型,如DIR、REG等,常见的文件类型
(1)DIR:表示目录
(2)CHR:表示字符类型
(3)BLK:块设备类型
(4)UNIX: UNIX 域套接字
(5)FIFO:先进先出 (FIFO) 队列
(6)IPv4:网际协议 (IP) 套接字
DEVICE:指定磁盘的名称
SIZE:文件的大小
NODE:索引节点(文件在磁盘上的标识)
NAME:打开文件的确切名称
实例2:查看谁正在使用某个文件,也就是说查找某个文件相关的进程
命令:
lsof /bin/bash
输出:
COMMAND PID USER FD TYPE DEVICE SIZE NODE NAME
bash 24159 root txt REG 8,2 801528 5368780 /bin/bash
bash 24909 root txt REG 8,2 801528 5368780 /bin/bash
bash 24941 root txt REG 8,2 801528 5368780 /bin/bash
[root@localhost ~]#
说明:
实例3:递归查看某个目录的文件信息
命令:
lsof test/test3
输出:
[root@localhost soft]# lsof test/test3
COMMAND PID USER FD TYPE DEVICE SIZE NODE NAME
bash 24941 root cwd DIR 8,2 4096 2258872 test/test3
vi 24976 root cwd DIR 8,2 4096 2258872 test/test3
[root@localhost soft]#
说明:
使用了+D,对应目录下的所有子目录和文件都会被列出
实例4:不使用+D选项,遍历查看某个目录的所有文件信息的方法
命令:
lsof |grep 'test/test3'
输出:
[root@localhost soft]# lsof |grep 'test/test3'
vi 24976 root cwd DIR 8,2 4096 2258872 /opt/soft/test/test3
vi 24976 root 4u REG 8,2 12288 2258882 /opt/soft/test/test3/.log2013.log.swp
[root@localhost soft]#
说明:
实例5:列出某个用户打开的文件信息
命令:
lsof -u username
说明:
-u 选项,u其实是user的缩写
实例6:列出某个程序进程所打开的文件信息
命令:
lsof -c mysql
说明:
-c 选项将会列出所有以mysql这个进程开头的程序的文件,其实你也可以写成 lsof | grep mysql, 但是第一种方法明显比第二种方法要少打几个字符了
实例7:列出多个进程多个打开的文件信息
命令:
lsof -c mysql -c apache
实例8:列出某个用户以及某个进程所打开的文件信息
命令:
lsof -u test -c mysql
说明:
用户与进程可相关,也可以不相关
实例9:列出除了某个用户外的被打开的文件信息
命令:
lsof -u ^root
说明:
^这个符号在用户名之前,将会把是root用户打开的进程不让显示
实例10:通过某个进程号显示该进行打开的文件
命令:
lsof -p 1
实例11:列出多个进程号对应的文件信息
命令:
lsof -p 1,2,3
实例12:列出除了某个进程号,其他进程号所打开的文件信息
命令:
lsof -p ^1
实例13:列出所有的网络连接
命令:
lsof -i
实例14:列出所有tcp 网络连接信息
命令:
lsof -i tcp
实例15:列出所有udp网络连接信息
命令:
lsof -i udp
实例16:列出谁在使用某个端口
命令:
lsof -i :3306
实例17:列出谁在使用某个特定的udp端口
命令:
lsof -i udp:55
或者:特定的tcp端口
命令:
lsof -i tcp:80
实例18:列出某个用户的所有活跃的网络端口
命令:
lsof -a -u test -i
实例19:列出所有网络文件系统
命令:
lsof -N
实例20:域名socket文件
命令:
lsof -u
实例21:某个用户组所打开的文件信息
命令:
lsof -g 5555
实例22:根据文件描述列出对应的文件信息
命令:
lsof -d description(like 2)
例如:lsof -d txt
例如:lsof -d 1
例如:lsof -d 2
说明:
0表示标准输入,1表示标准输出,2表示标准错误,从而可知:所以大多数应用程序所打开的文件的 FD 都是从 3 开始
实例23:根据文件描述范围列出文件信息
命令:
lsof -d 2-3
实例24:列出COMMAND列中包含字符串" sshd",且文件描符的类型为txt的文件信息
命令:
lsof -c sshd -a -d txt
输出:
COMMAND PID USER FD TYPE DEVICE SIZE NODE NAME
sshd 2756 root txt REG 8,2 409488 1027867 /usr/sbin/sshd
sshd 24155 root txt REG 8,2 409488 1027867 /usr/sbin/sshd
sshd 24905 root txt REG 8,2 409488 1027867 /usr/sbin/sshd
sshd 24937 root txt REG 8,2 409488 1027867 /usr/sbin/sshd
[root@localhost soft]#
[root@localhost soft]#
实例25:列出被进程号为1234的进程所打开的所有IPV4 network files
命令:
lsof -i 4 -a -p 1234
实例26:列出目前连接主机peida.linux上端口为:20,21,22,25,53,80相关的所有文件信息,且每隔3秒不断的执行lsof指令
命令:
lsof -i @peida.linux:20,21,22,25,53,80 -r 3