PageRank源码简析
1 package org.apache.spark.graphx.lib.PageRank
PageRank的实现类
pageRank在spark中基于pregel思想做了并行化实现
def runWithOptions[VD: ClassTag, ED: ClassTag](
graph: Graph[VD, ED], numIter: Int, resetProb: Double = 0.15,
srcId: Option[VertexId] = None): Graph[Double, Double]
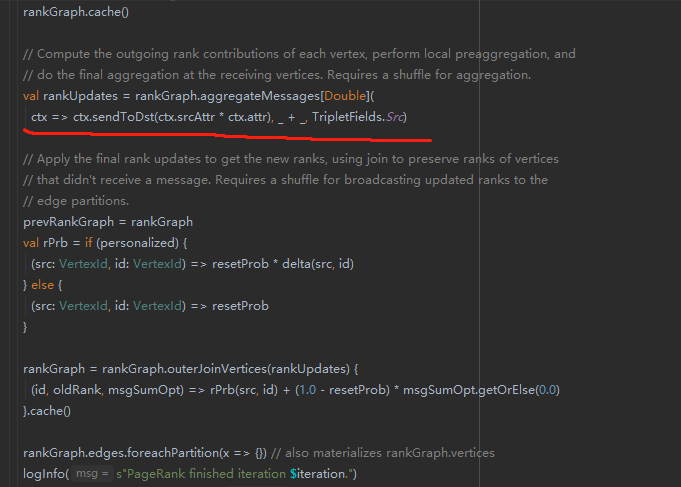
该方法作为主要执行入口,执行多次pr值迭代结算。而迭代计算的核心逻辑如下
红线部分完成了整个图的pr值更新,
可以看到 是Graph类实现了pregel的计算逻辑。
因此我们继续深挖Graph类,实现类 GraphImpl实现了 aggregateMessagesWithActiveSet方法
该方法是核心实现类,定义如下
private[graphx] def aggregateMessagesWithActiveSet[A: ClassTag](
sendMsg: EdgeContext[VD, ED, A] => Unit,
mergeMsg: (A, A) => A,
tripletFields: TripletFields,
activeSetOpt: Option[(VertexRDD[_], EdgeDirection)])
: VertexRDD[A]

在其实现中,可以看到真正实现这个方法的是 EdgePartiion类。

其实现如下。我们发现,EdgeParition,顺序地(sync)执行了sendMsg操作。
在sendMsg中,完成了pagerank 的sendMsg ,以及meger方法 的函数式调用。
/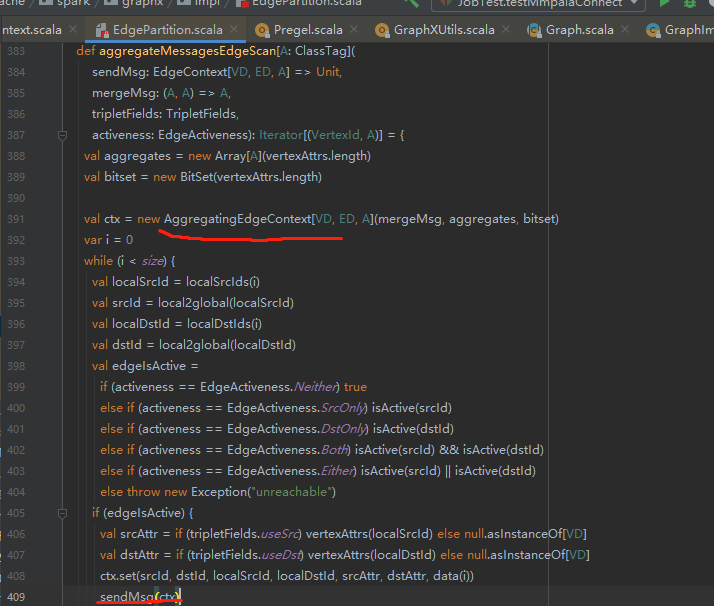
核心思想:
基于EdgePartiion来执行 compute以及 combine,并利用rdd分区的并行化特性,来实现大同步栅栏。
主要实现逻辑:
预定义了 sendMsg方法以及 combine函数,实现权重转移操作。同时包含了active点的优化(减少计算量,这个部分不做详细分析)
最终的计算结果与原始数值做join操作,计算新的pr结果。
在上文的pageRank调用入口中,可以窥见官方利用sparkRDD来实现pregrel的最佳实践。都是通过lambda表达式来定义compute和combine逻辑。
在PageRank类中的runUntilConvergenceWithOptions方法中,直接使用了org.apache.spark.graphx.Pregel 类来完成其计算。显示地定义了compute方法与conbine方法。
org.apache.spark.graphx.Pregel类中 ,该类封装了一整套完整的pregel计算逻辑(可以),其最终仍是调用graphImpl类来实现相关的计算,因此不做特别的说明
def runUntilConvergenceWithOptions[VD: ClassTag, ED: ClassTag](
graph: Graph[VD, ED], tol: Double, resetProb: Double = 0.15,
srcId: Option[VertexId] = None): Graph[Double, Double]
我们可以看到 在该方法中,
