Jieba库实例
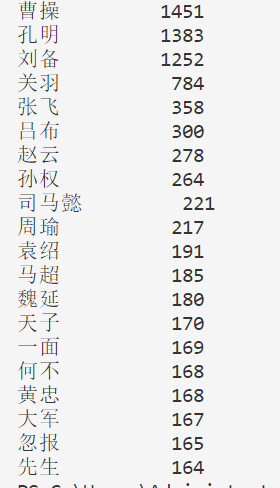
(1)、运用Jieba库分析三国演义, 得到词频统计, 并对词频进行排序。
(2)、 根据得到的关键词, 做一个词云图。
代码如下:


1 import jieba 2 import wordcloud as wc 3 import matplotlib.pyplot as plt 4 import numpy as np 5 from PIL import Image 6 7 txt = open("三国演义.txt", "r", encoding = "utf-8").read() 8 excludes = {"将军","却说","荆州","二人","不可","不能","如此","主公","商议","如何","军士","左右","军马" 9 ,"引兵","次日","大喜","天下","东吴","于是","今日","不敢","魏兵","陛下","一人","都督","人马","不知" 10 ,"汉中","只见","众将","后主","蜀兵","上马","大叫","太守","此人","夫人","先主","后人","背后","城中"} 11 counts = {} 12 words = jieba.lcut(txt) 13 for word in words: 14 if len(word) == 1: 15 continue 16 elif word == "诸葛亮" or word == "孔明曰": 17 rword = "孔明" 18 elif word == "关公" or word == "云长": 19 rword = "关羽" 20 elif word == "玄德" or word == "玄德曰": 21 rword = "刘备" 22 elif word == "孟德" or word == "丞相": 23 rword = "曹操" 24 else: 25 rword = word 26 counts[rword] = counts.get(rword, 0) + 1 27 for word in excludes: 28 del counts[word] 29 items = list(counts.items()) 30 items.sort(key = lambda x:x[1], reverse = True) 31 text = '' 32 for w in range(200): 33 text += items[w][0] + ' ' 34 35 for i in range(20): 36 word, count = items[i] 37 print('{:<10}{:>5}'.format(word, count)) 38 39 font = "C:\WINDOWS\FONTS\MSYHL.TTC" #该处应写所需字体的路径 40 bg_pic = np.array(Image.open('C:\Users\Administrator\Desktop\tree.jpg')) 41 #同样这里写的是背景图片的路径 42 43 cloud = wc.WordCloud(font_path=font,#设置字体 44 background_color="white", #背景颜色 45 max_words=2000,# 词云显示的最大词数 46 mask=bg_pic,#设置背景图片 47 max_font_size=100, #字体最大值 48 random_state=42) 49 mywc = cloud.generate(text) 50 plt.imshow(mywc) 51 plt.axis('off') 52 plt.show() 53 mywc.to_file('mywc.png')
这里只是出现次数在前20的词, 没有完全删除不必要的词语 这边就是词云图