1.给小表弟汇总一个院校列表,想来想去可以写一个小爬虫爬下来方便些,所以就看了看怎么用python写,到了基本能用的程度,没有什么特别的技巧,大多都是百度搜的,遇事不决问百度啦
2.基本流程就是:
用request爬取一个页面之后用BeautifulSoup4对爬到的页面进行处理,
然后需要的东西进行预处理之后存到桌面上的.txt文件里,
之后再对.txt文件里的字符串进行分割,
最后把数据存到excel表里
3.准备:需要下载安装requests库,以及BeautifulSoup4的库,还有xlsxwriter库,相关安装方法网上一大堆
4.爬取页面的网页源代码:

5.将爬取的数据存到.txt文件中:
from bs4 import BeautifulSoup
import requests
import os
def get_soup():
r = requests.get("http://www.eol.cn/html/g/gxmd/bj/", timeout=30)
# 判断网络链接的状态,连接错误将产生一个异常
#print(r.status_code)
r.encoding = r.apparent_encoding
soup = BeautifulSoup(r.text,features="html.parser")
return soup;
#删除前几个元素
def del_previous_ele(full_list):
for i in range(8):
full_list.remove(full_list[0])
return full_list;
#获取学校名称,学校编号,主管部门,办学层次
def select_school_ele(full_list):
school_list = []
for i in range(full_list.__len__()):
//这里是对获取的所有学校列表进行遍历,取出需要的数据
if (i % 7) == 1 or (i % 7) == 2 or (i % 7) == 3 or (i%7) == 5 :
school_list.append(full_list[i].string+" ")
//获取到一个学校完整的信息之后就在后面换行
if (i%7) == 5:
school_list.append("
")
else:
pass
return school_list;
#将数据写入文件
def createFile(txt):
file = open('C:\Users\XXXXXXXXXXXXXXX\Desktop\school.txt', 'w')
file.writelines(txt)
file.close();
print("写入成功")
if __name__ == "__main__":
soup = get_soup()
full_list = del_previous_ele(soup.find_all(align="center"))
school_list = select_school_ele(full_list)
createFile(school_list)
6.对school.txt文件进行处理,处理完了存到excel文件里
import os
import xlsxwriter
def get_file(path,mode_):
list = "";
file = open(path,mode_)
list = file.read()
file.close()
return list
def write_excel(list):
workbook = xlsxwriter.Workbook("C:\Users\XXXXXXXXXXXXXXXXX\Desktop\school.xlsx")
worksheet = workbook.add_worksheet("school")
#5个属性为一组
list_5_item = list.split("
")
# print(len(list_5_item))
for i in range(len(list_5_item)):
specific_school = list_5_item[i].split(" ")
print(len(specific_school))
for j in range(len(specific_school)):
worksheet.write( i , j , specific_school[j])
if __name__ == "__main__":
list = get_file('C:\Users\XXXXXXXXXXXXXXXXXXXXXXXXXXXx\Desktop\new.txt', 'r')
write_excel(list)
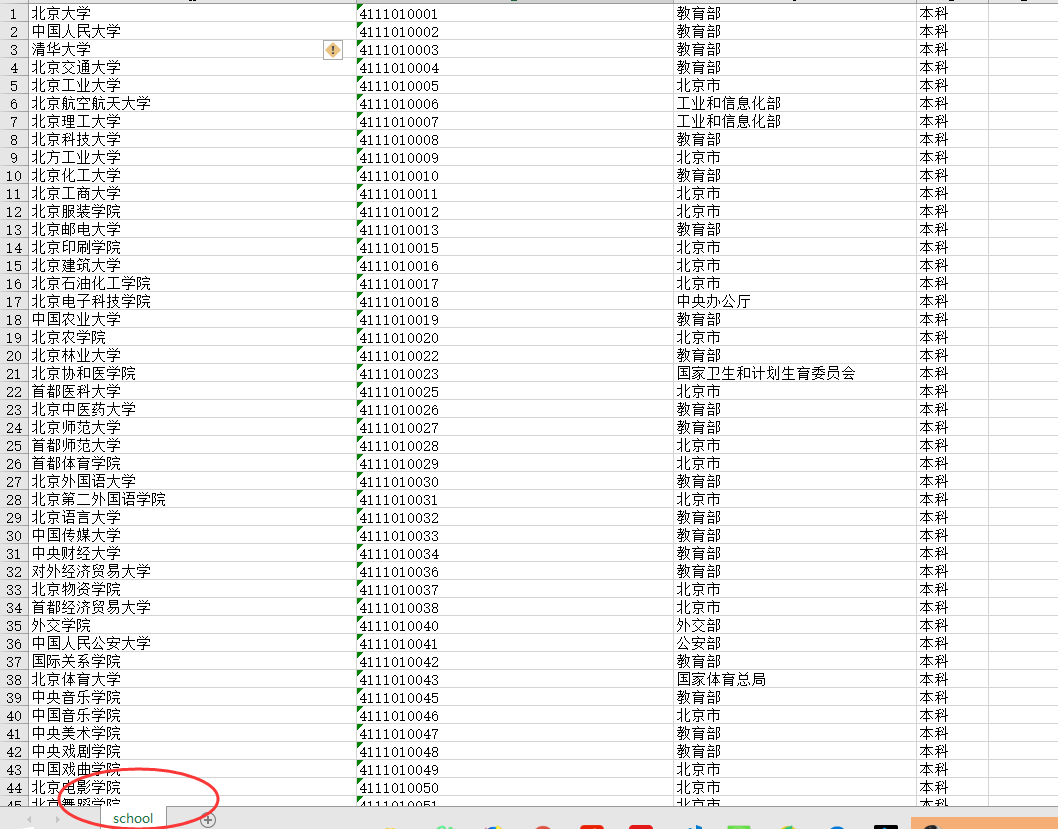
7.完成结果:
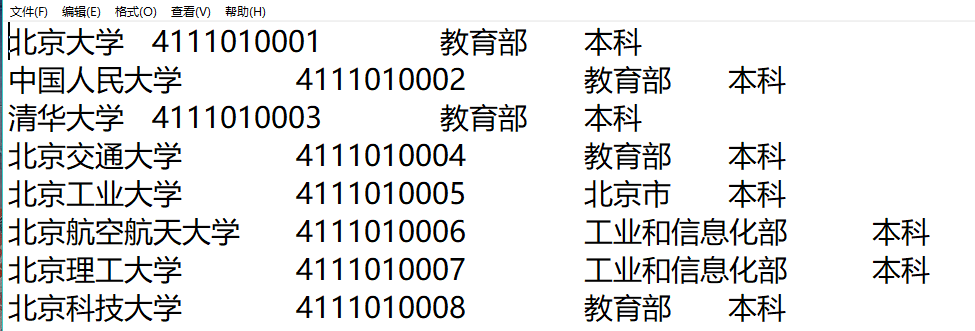
文本文件:
school.xlsx文件:
8.到这里就结束啦,因为刚接触写爬虫,所以有些地方难免写的不好,不喜勿喷啦