连续属性变换成分类属性,即连续属性离散化
等宽法 / 等频法
等宽法 → 将数据均匀划分成n等份,每份的间距相等
cut方法
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
% matplotlib inline
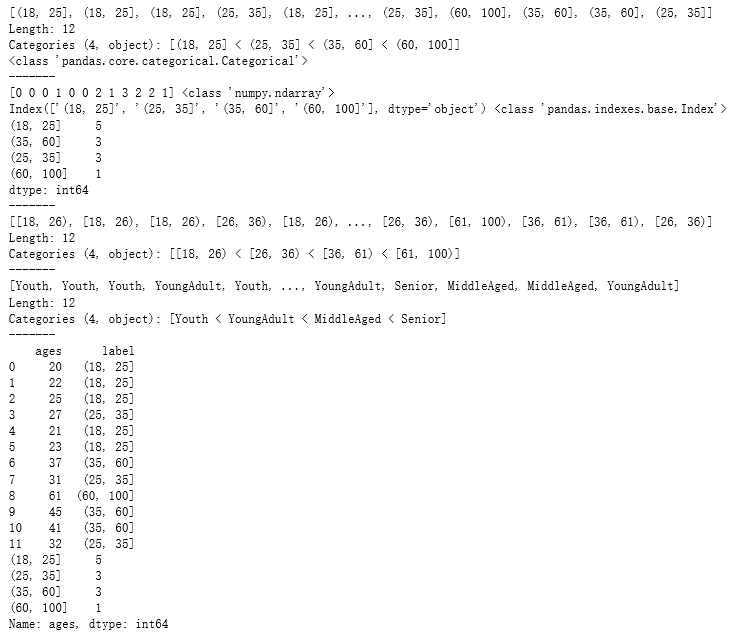
ages=[20,22,25,27,21,23,37,31,61,45,41,32]
# 有一组人员年龄数据,希望将这些数据划分为“18到25”,“26到35”,“36到60”,“60以上”几个面元
bins = [18,25,35,60,100]
cats = pd.cut(ages,bins)
print(cats)
print(type(cats))
print('-------')
# 返回的是一个特殊的Categorical对象 → 一组表示面元名称的字符串
print(cats.codes, type(cats.codes)) # 0-3对应分组后的四个区间,用代号来注释数据对应区间,结果为ndarray
print(cats.categories, type(cats.categories)) # 四个区间,结果为index
print(pd.value_counts(cats)) # 按照区间计数
print('-------')
# cut结果含有一个表示不同分类名称的层级数组以及一个年龄数据进行标号的代号属性
print(pd.cut(ages,[18,26,36,61,100],right=False))
print('-------')
# 通过right函数修改闭端,默认为True
group_names=['Youth','YoungAdult','MiddleAged','Senior']
print(pd.cut(ages,bins,labels=group_names))
print('-------')
# 可以设置自己的区间名称,用labels参数
df = pd.DataFrame({'ages':ages})
group_names=['Youth','YoungAdult','MiddleAged','Senior']
s = pd.cut(df['ages'],bins) # 也可以 pd.cut(df['ages'],5),将数据等分为5份
df['label'] = s
cut_counts = s.value_counts(sort=False)
print(df)
print(cut_counts)
# 对一个Dataframe数据进行离散化,并计算各个区间的数据计数
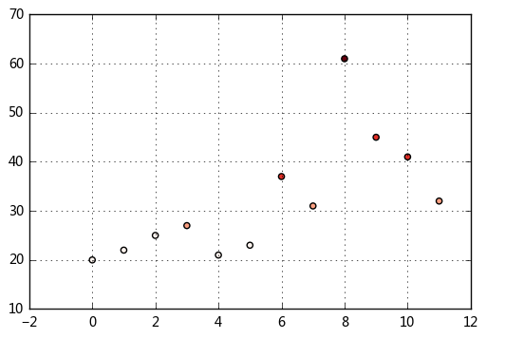
plt.scatter(df.index,df['ages'],cmap = 'Reds',c = cats.codes)
plt.grid()
# 用散点图表示,其中颜色按照codes分类
# 注意codes是来自于Categorical对象
等频法 → 以相同数量的记录放进每个区间
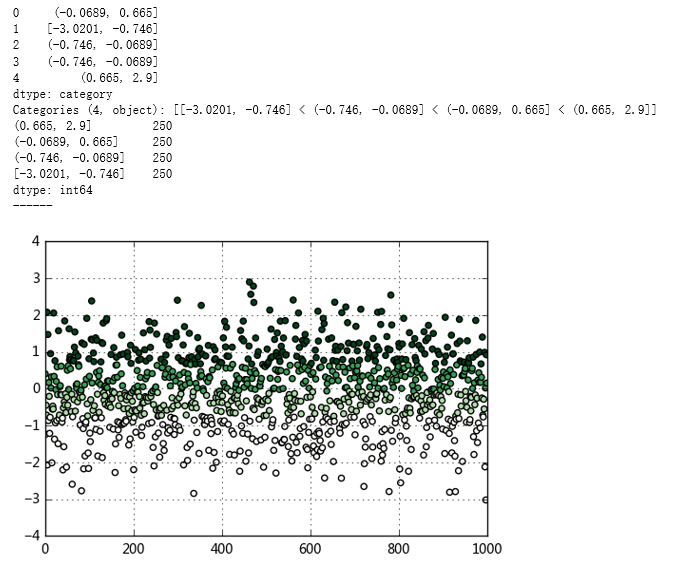
data = np.random.randn(1000)
s = pd.Series(data)
cats = pd.qcut(s,4) # 按四分位数进行切割,可以试试 pd.qcut(data,10)
print(cats.head())
print(pd.value_counts(cats))
print('------')
# qcut → 根据样本分位数对数据进行面元划分,得到大小基本相等的面元,但并不能保证每个面元含有相同数据个数
# 也可以设置自定义的分位数(0到1之间的数值,包含端点) → pd.qcut(data1,[0,0.1,0.5,0.9,1])
plt.scatter(s.index,s,cmap = 'Greens',c = pd.qcut(data,4).codes)
plt.xlim([0,1000])
plt.grid()
# 用散点图表示,其中颜色按照codes分类
# 注意codes是来自于Categorical对象