
前文回顾
CommitLog篇 ——【RocketMQ源码分析】深入消息存储(1)
MappedFile篇 ——【RocketMQ源码分析】深入消息存储(3)
前文说完了一条消息如何被持久化到本地磁盘CommitLog,本篇就要谈谈如何从CommitLog来构建我们消息消费的核心队列结构ConsumeQueue了。
之前已经说过,CommitLog文件是消息的大杂烩,所有消息具体都被放到了这个大文件中,而ConsumeQueue则是一个逻辑上的队列,也是消息消费的核心,它存在Topic与Queue这两个概念,也就是消费者在消费时需要关心的东西。

除了ConsumeQueue目录下存在Topic与QueueId组成的两级目录,它实际存储消息的文件也是与CommitLog相似,是一个文件名代表offset的文件。
在ConsumeQueue中,每一个单元结构如下图:

CommitLog Offset : 8 Byte
Size : 4 Byte
Message Tag Hashcode : 8 Byte
第一个8Byte的CommitLog Offset代表该消息在CommitLog文件中的偏移位置。
第二个4Byte的Size代表消息的大小。
凭借CommitLog Offset与Size就可以在CommitLog中定位一条消息。
而第三个字段Message Tag Hashcode则是用来快速过滤消息。
可以发现,ConsumeQueue中每个消息占据20Byte,也就是说如果MessageStoreConfig的mappedFilesizeConsumeQueue设置为100Byte,那么每个ConsumeQueue文件只能存储5条消息。
了解完ConsumeQueue,接下来就需要知道ConsumeQueue是在什么时候构建的,在上一篇CommitLog存储消息时,我们没有看到有写入ConsumeQueue,那是因为ConsumeQueue是由一个异步线程去构建的。
异步构建流程如下,DefaultMessageStore的内部类ReputMessageService继承自ServiceThread,其run方法中每1毫秒调用一次doReput方法。
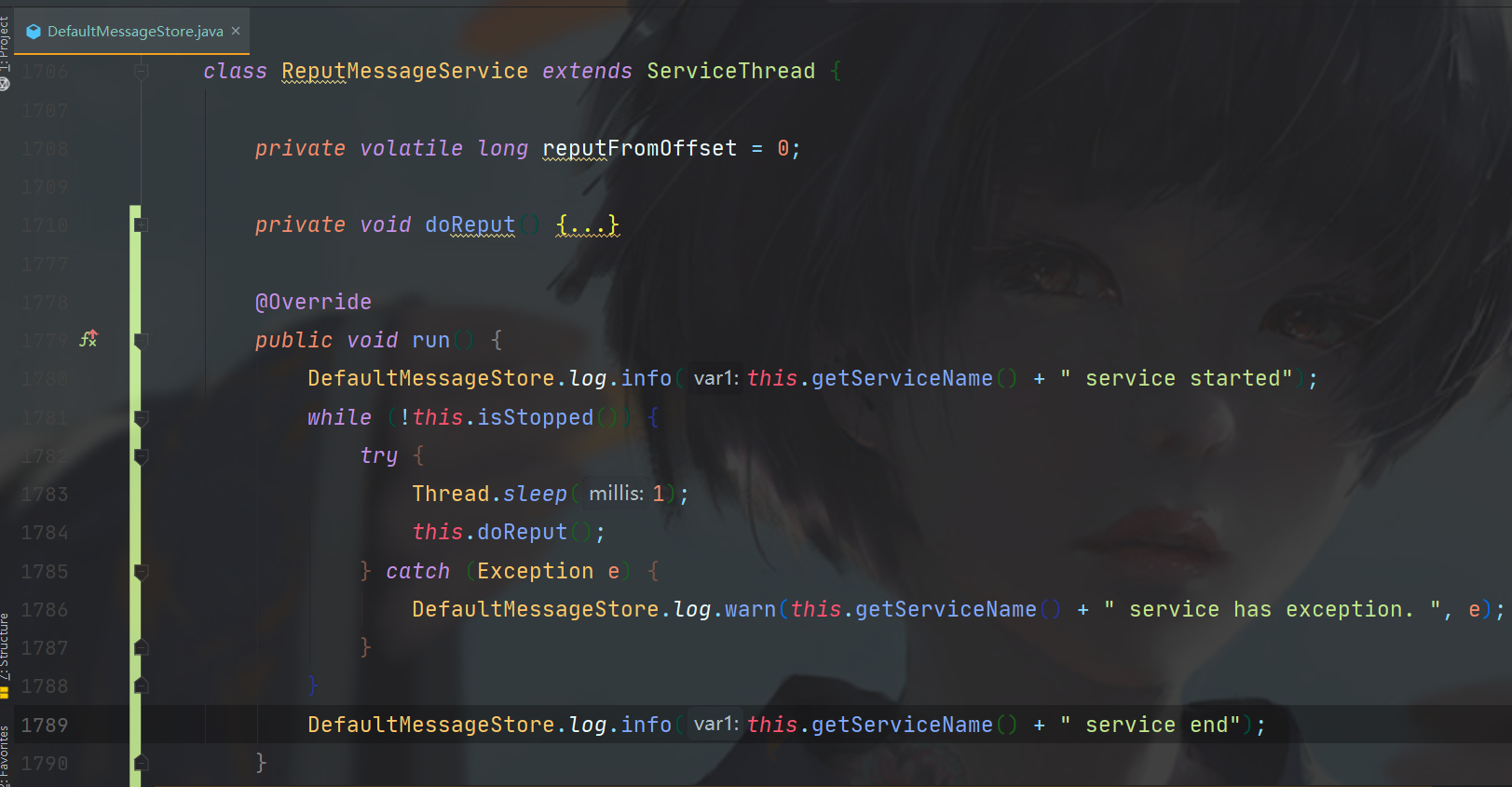
reputFromOffset是初始开始同步的偏移位置,默认为0。
在doReput方法中进行了ConsumeQueue的构建。
首先,是一个只有在异常情况下才会终止的for循环,doNext只有返回值错误的情况下才会设为false,可以理解为一个死循环。
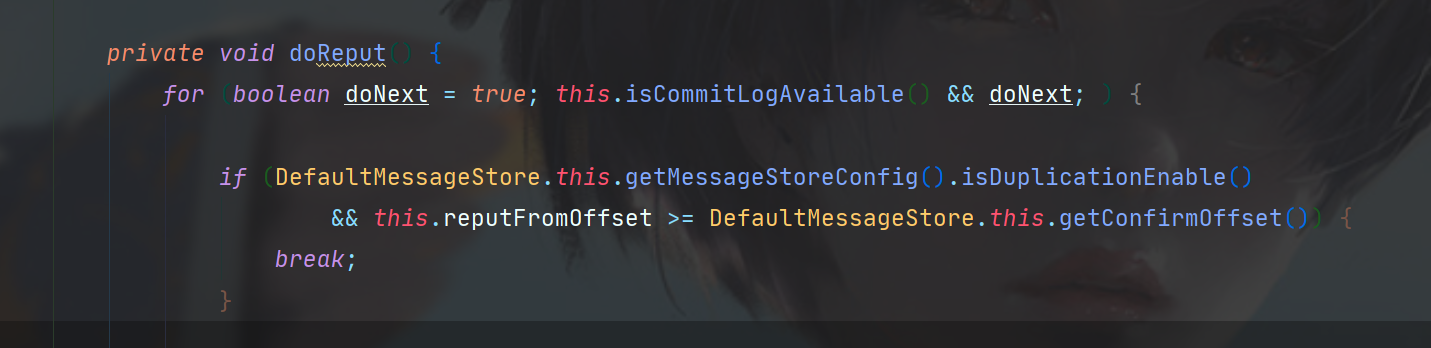
如果当前reput的偏移量大于等于已确认的,就不需要构建。

如果符合条件,就从CommitLog中读取对应位置的数据,如果返回null,就终止当前for死循环,不为null则去构建ConsumeQueue。

可以看看result返回了什么。
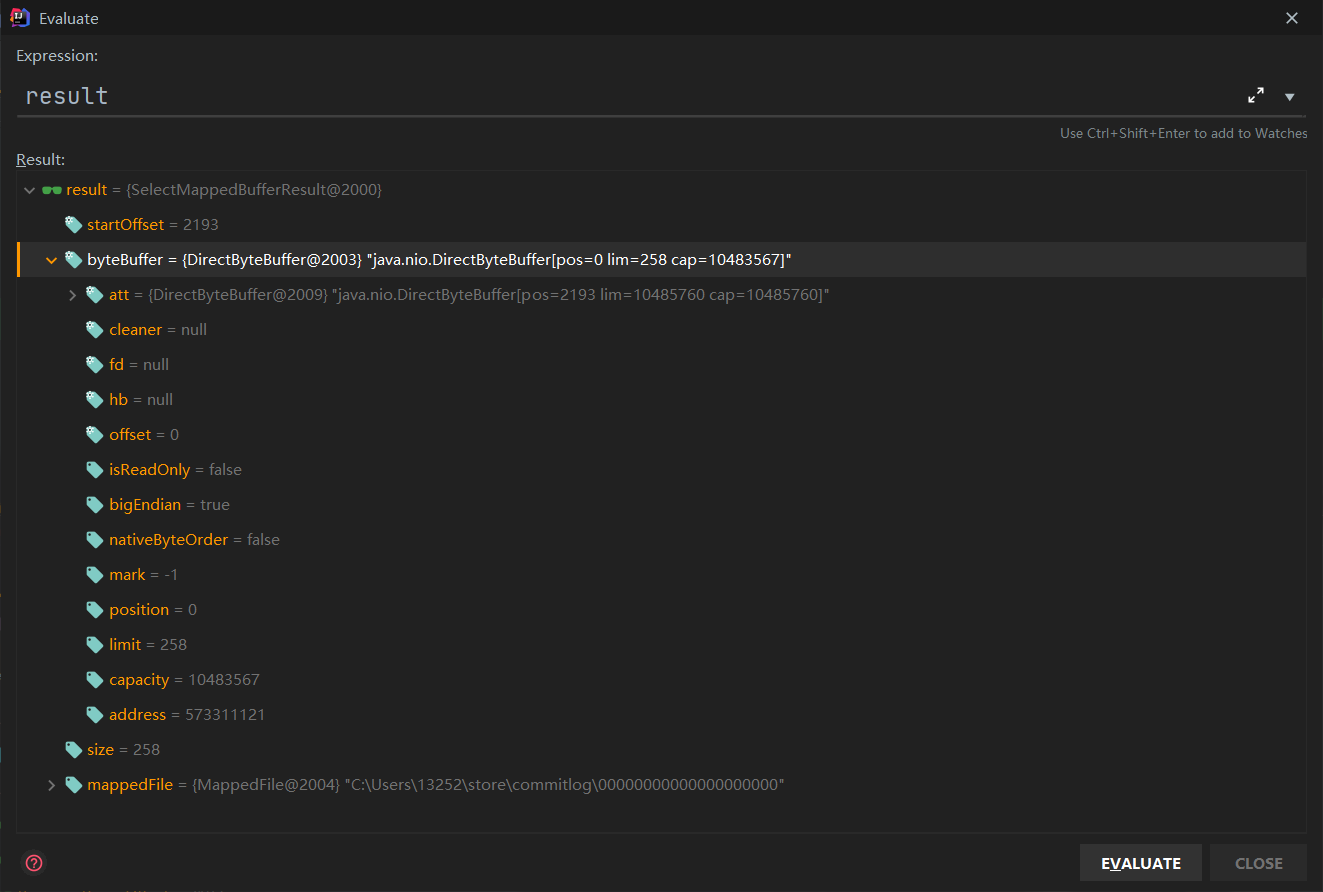
如果result不为null,获取起始偏移位置,并且设置为doReput的reputFromOffset偏移量。
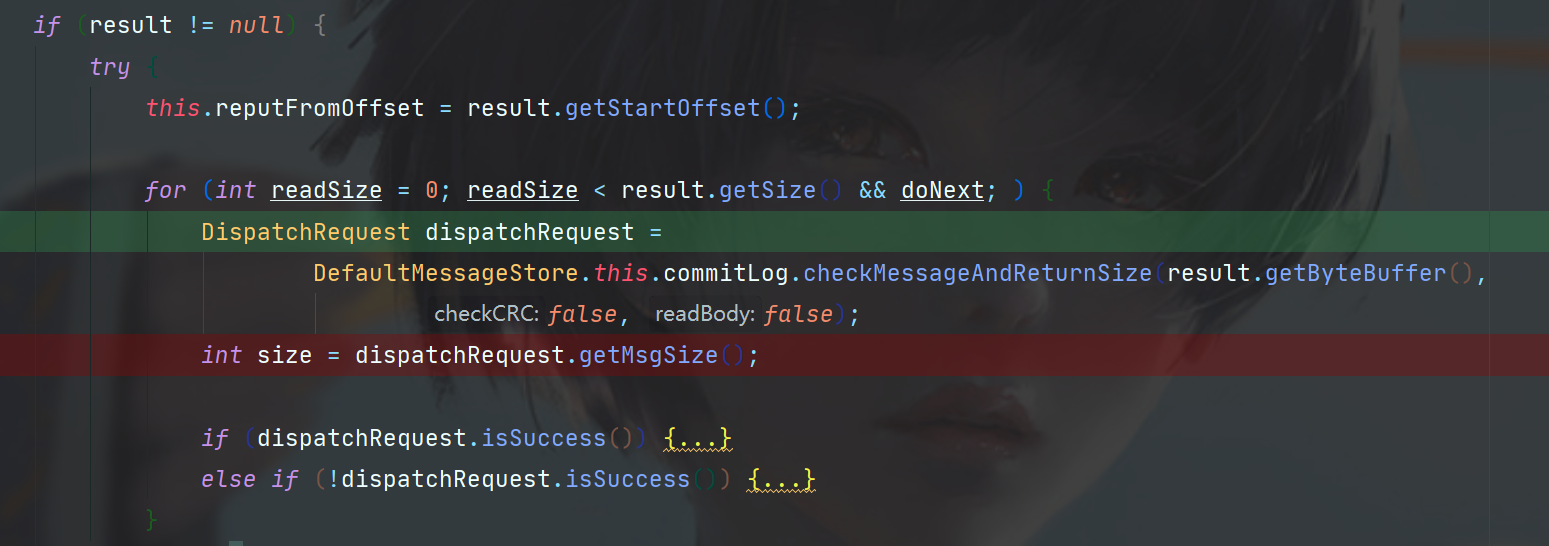
之后进入checkMessageAndReturnSize方法,该方法就是从result变量的buffer中读取消息的具体数据了,一堆buffer.get操作,此处不列出了,感兴趣可以看CommitLog#checkMessageAndReturnSize方法。
方法最后包装了一个DispatchRequest对象返回。

可以看看此处Debug拿到的DispatchRequest,主要有Topic名称,在CommitLog中的偏移位置,以及消息大小,如果你还记得上一篇CommitLog在最后判断CommitLog文件能不能存下这条消息时,可以看到当时就是一个121字节加8字节魔术大小的消息,在此处成功读取到了。
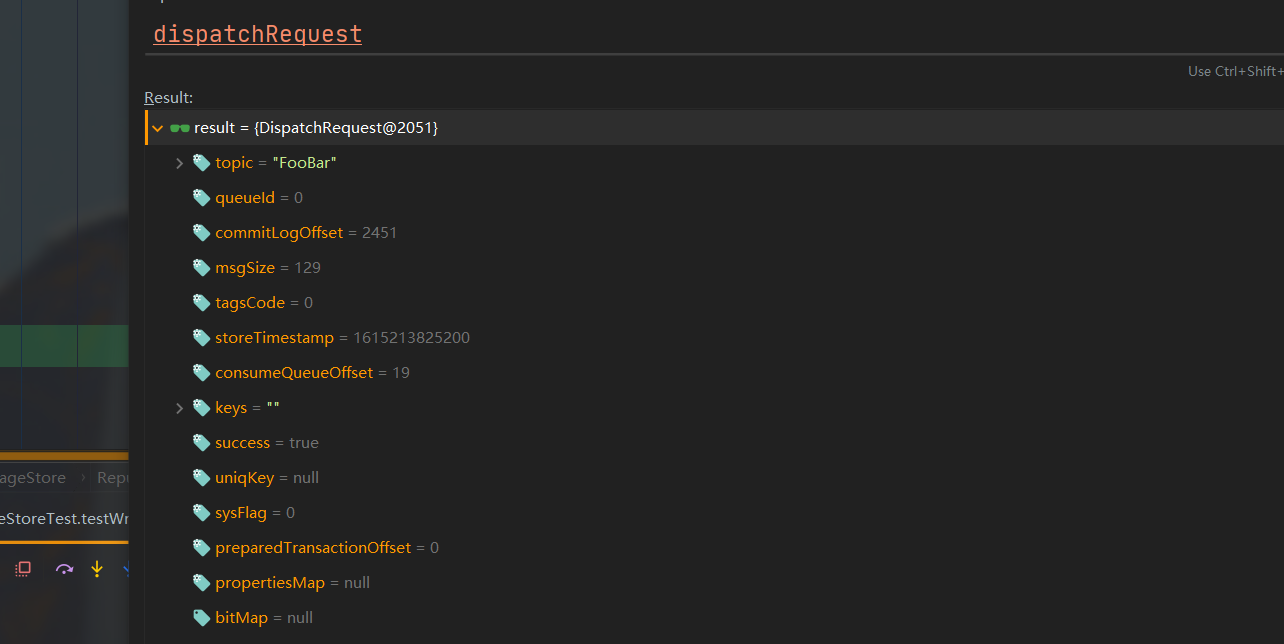
读取成功之后,就要构建ConsumeQueue了。
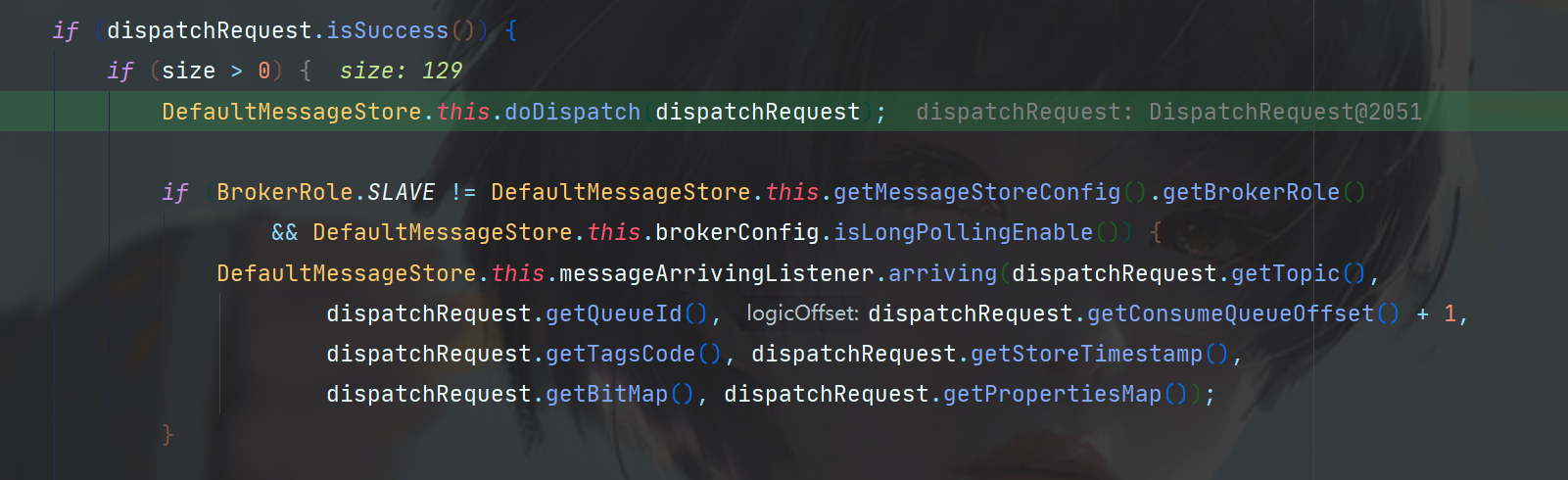
进入doDispatch方法,可以看到要构建的目标是有一个list,是CommitLogDispatcher的子类做了实现。
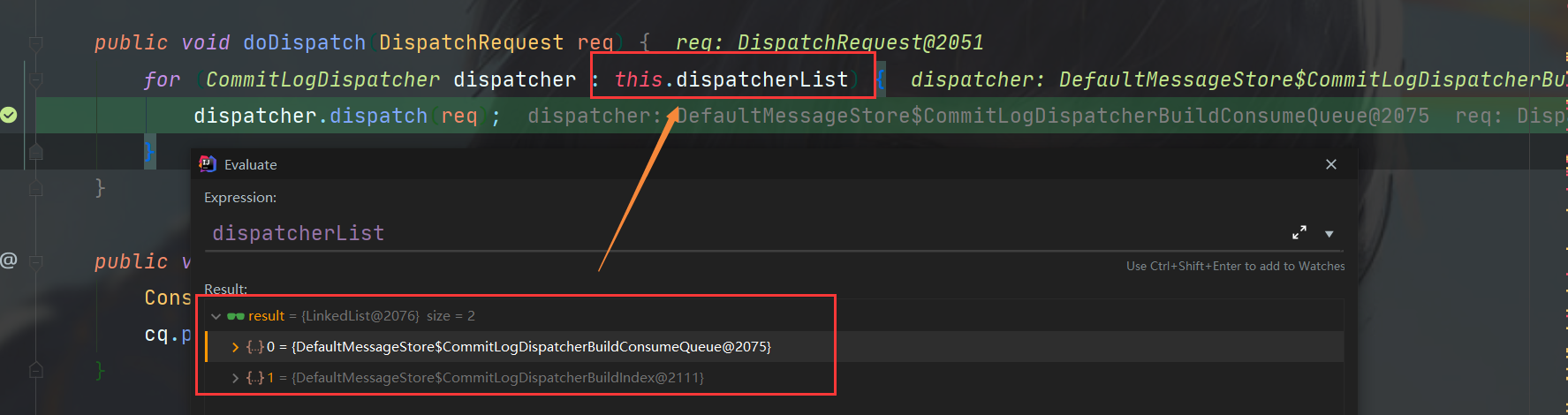
可以看到下图,实现有ConsumeQueue和Index两个,也就是说ConsumeQueue和Index文件的异步构建都是在此处,两个类都位于DefaultMessageStore中。
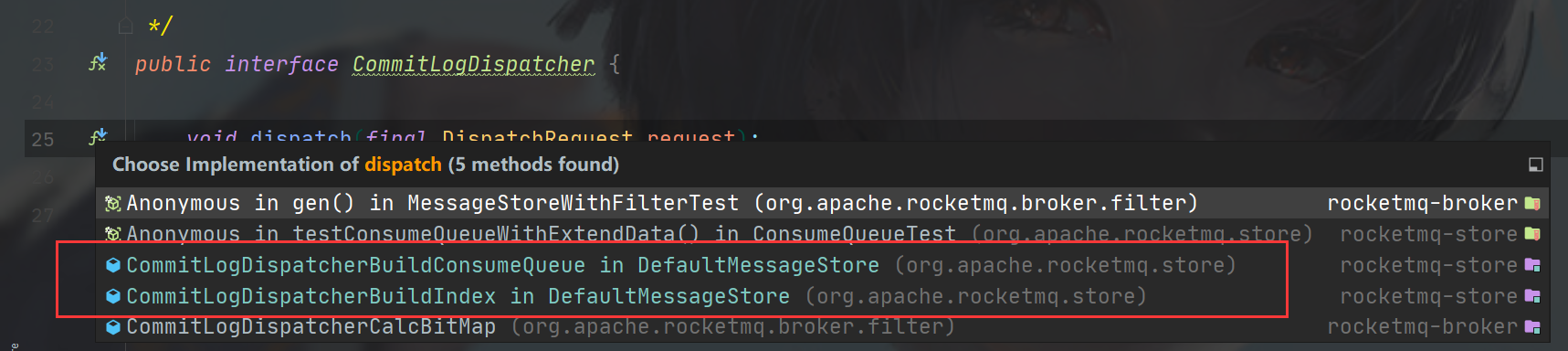
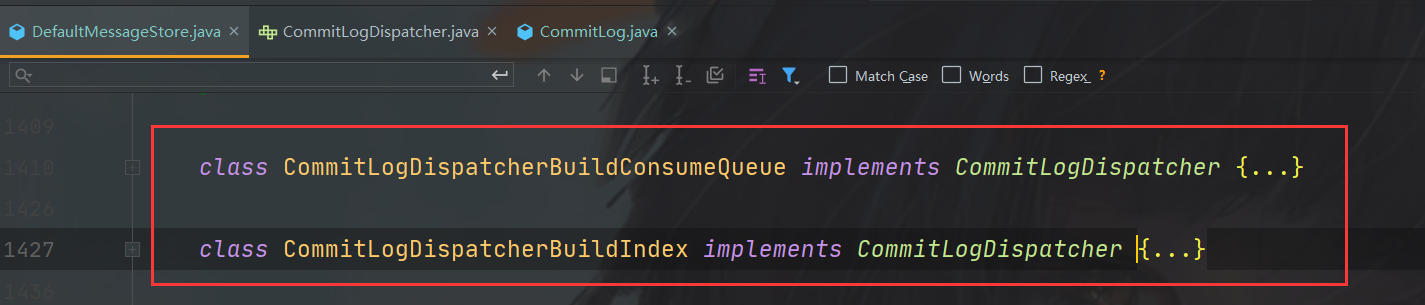
ConsumeQueue是逻辑消息队列,Index则是消息索引文件,存储了消息的存储时间,哈希,偏移量等信息,本篇主要看ConsumeQueue,所以走到CommitLogDispatcherBuildConsumeQueue的实现即可。
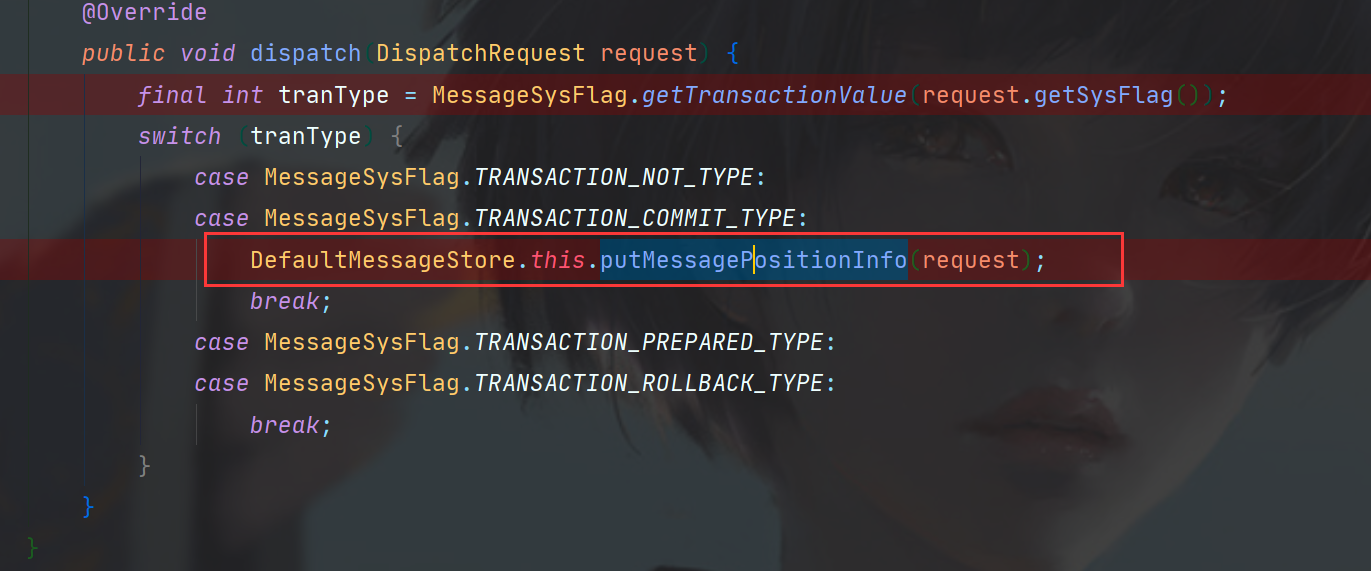
首先获取了消息类型,进入putMessagePositionInfo方法。

putMessagePositionInfo中分为两步,首先拿到ConsumeQueue对象,然后放入请求。
第一步的findConsumeQueue,可以根据topic和queueId来定位一个ConsumeQueue,正如我们之前看到了目录结构,这个获取的流程是先查找map,这个没有就新建。
步骤如下图,首先从table中拿到ConsumeQueue,如果没有拿到,就新建一个key是指定topic的结构,添加进table。
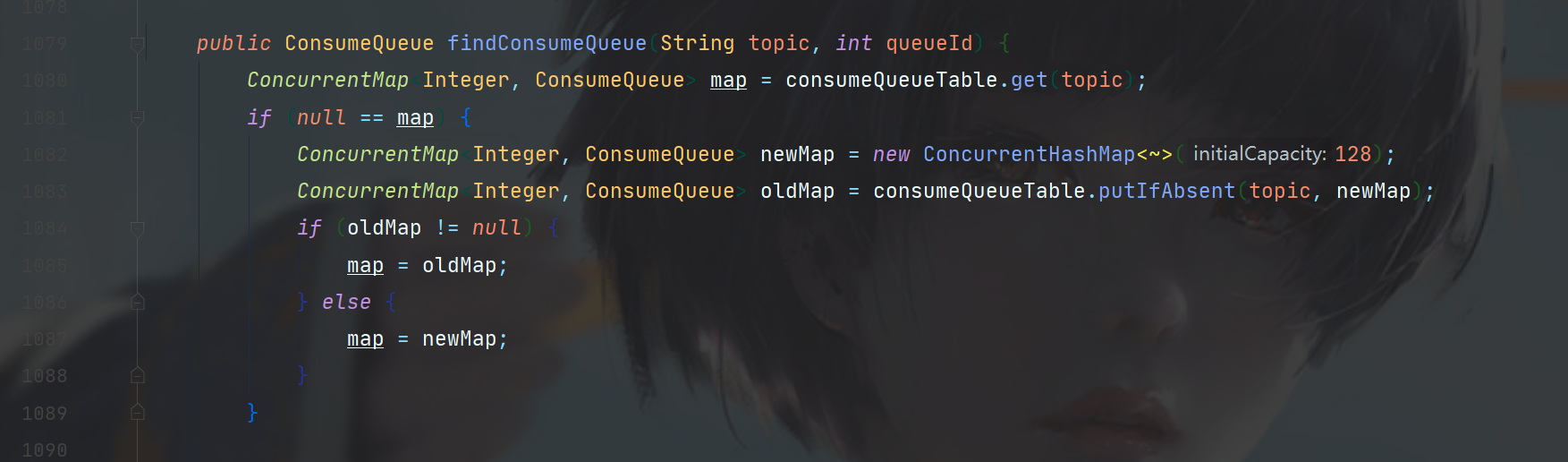
consumeQueueTable结构如下,是一个ConcurrentMap<String, ConcurrentMap<Integer,ConsumeQueue>>。
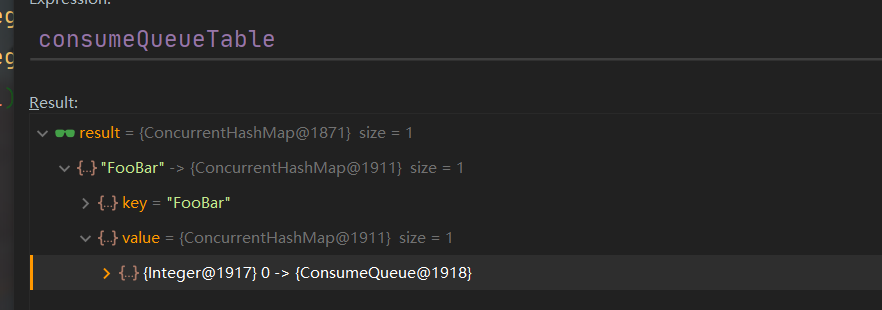
拿到consumeQueueTable内置的map之后,就可以根据QueueId拿到目标ConsumeQueue了。
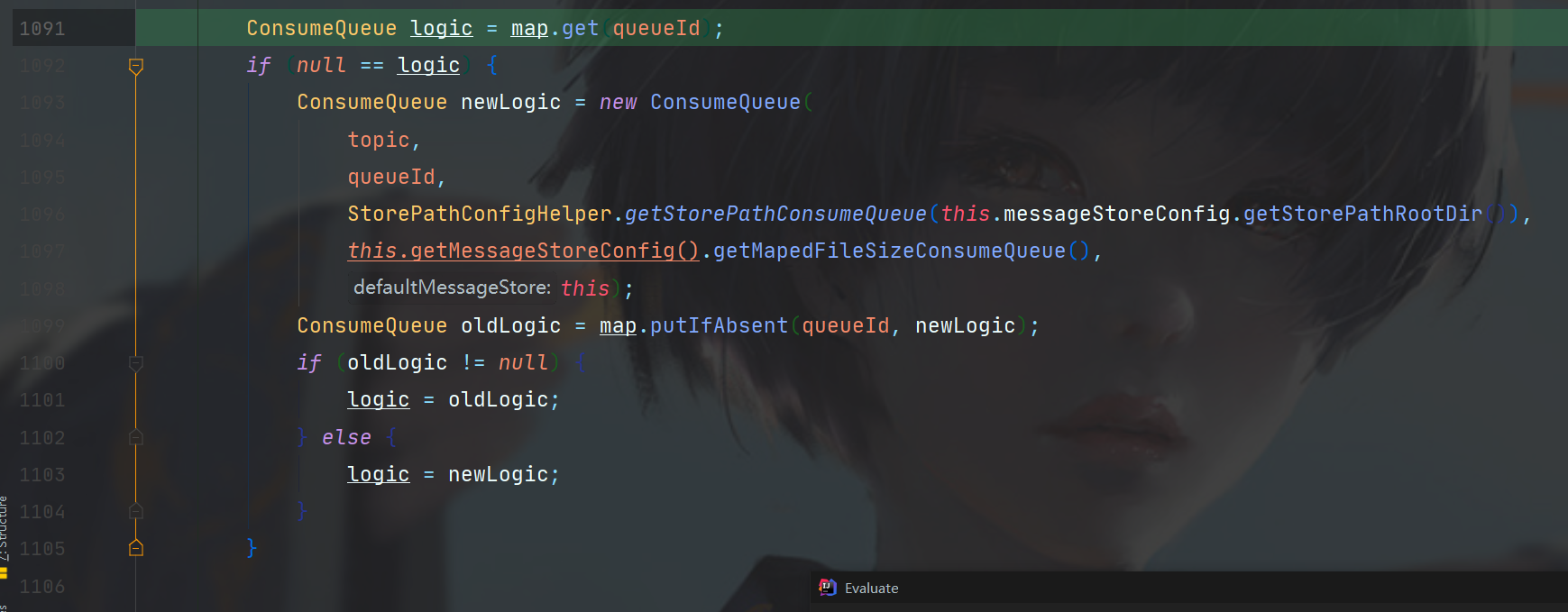
如果有,直接返回,如果没有,就说明需要初始化该ConsumeQueue了,初始化完成之后放入consumeQueueTable,并且返回该ConsumeQueue。

拿到ConsumeQueue就可以对请求进行构建了,进入putMessagePositionInfoWrapper方法。
首先获取了当前Store状态是否可写,如果可写,会在for循环内尝试maxRetries次构建,该值是30次。
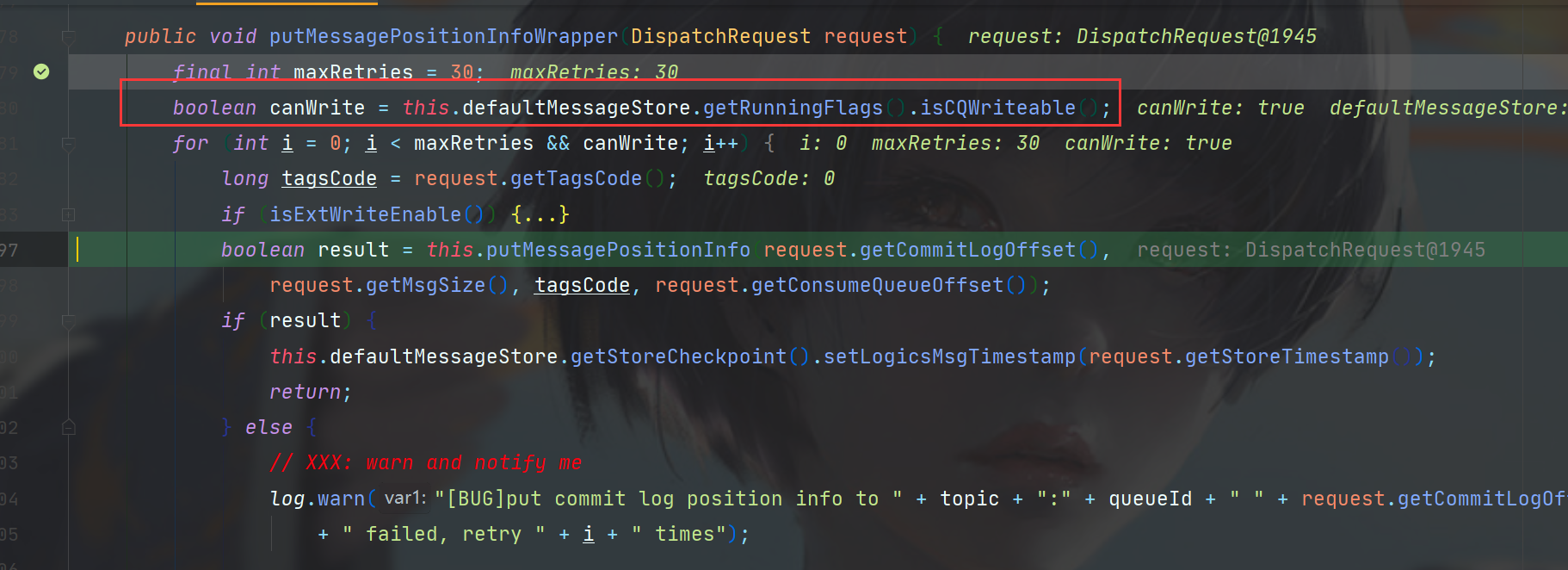
在for循环内,首先拿到了tag,然后在isExtWriteEnable处判断配置是否启用了写入扩展信息,如果开启,会在一个ConsumeQueueExt的结构中写入存储时间、Tag、bitMap等信息,此处先跳过。
此时调用了putMessagePositionInfo方法写入,如果返回result成功的话,直接return,否则休眠一秒钟,然后继续for循环,根据maxRetries的值,可以有30次机会。
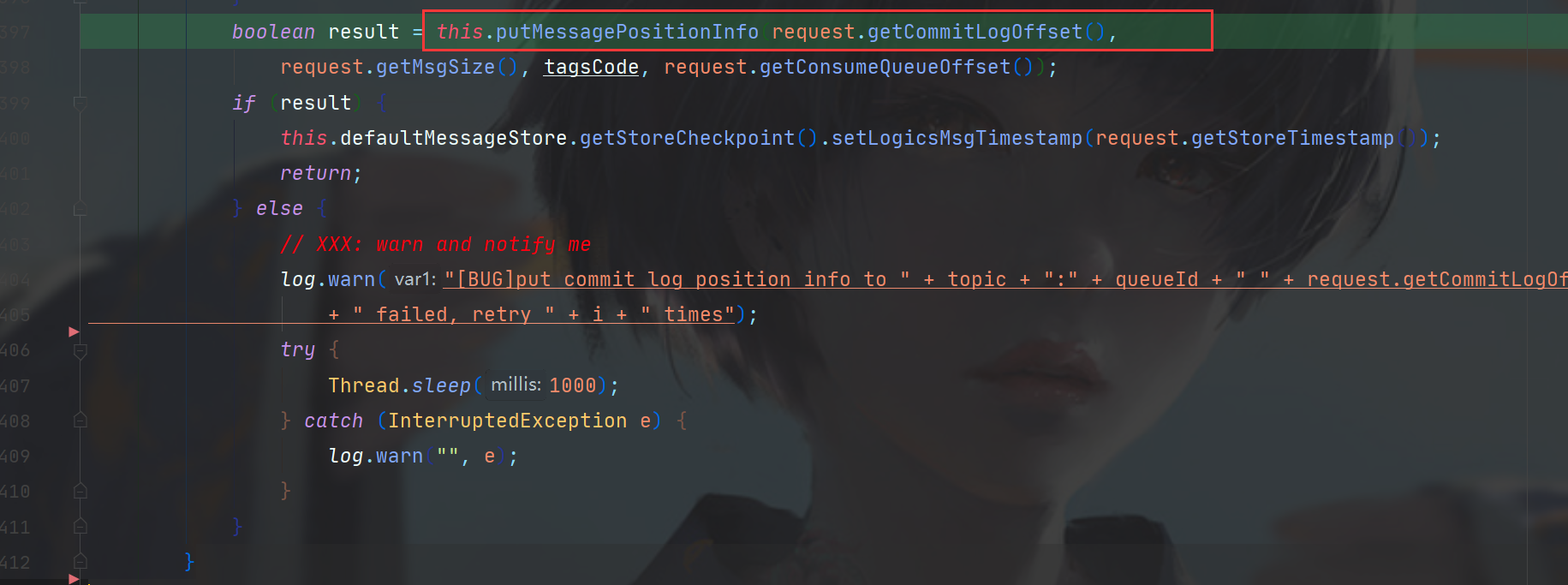
进入putMessagePositionInfo方法,可以看到向ConsumeQueue的byteBufferIndex中put了数据,该buffer是何时初始化的呢?
ConsumeQueue的构造函数中,就对byteBufferIndex进行了初始化

public static final int CQ_STORE_UNIT_SIZE = 20;
可以看到buffer的大小只有20字节,符合我们之前说的每个消息在ConsumeQueue中的大小。
而putMessagePositionInfo中首先也对byteBufferIndex进行了flip操作,也就是读写模式的切换,此处切换到了写模式,并且将目标数据放入buffer中。
之后就是熟悉的MappedFile操作,可以参考上一篇CommitLog中讲述的MappedFile。
最后appendMessage将消息写入文件channel中,等待刷盘时持久化。

以上就是ConsumeQueue的构建流程了。

