课程:《程序设计与数据结构》
班级: 1723
姓名: 王禹涵
学号:20172323
实验教师:王志强
实验日期:2018年11月11日
必修/选修: 必修
1.实验内容
1-实现二叉树
参考教材p212,完成链树LinkedBinaryTree的实现(getRight,contains,toString,preorder,postorder)
用JUnit或自己编写驱动类对自己实现的LinkedBinaryTree进行测试,提交测试代码运行截图,要全屏,包含自己的学号信息
课下把代码推送到代码托管平台
2-中序先序序列构造二叉树
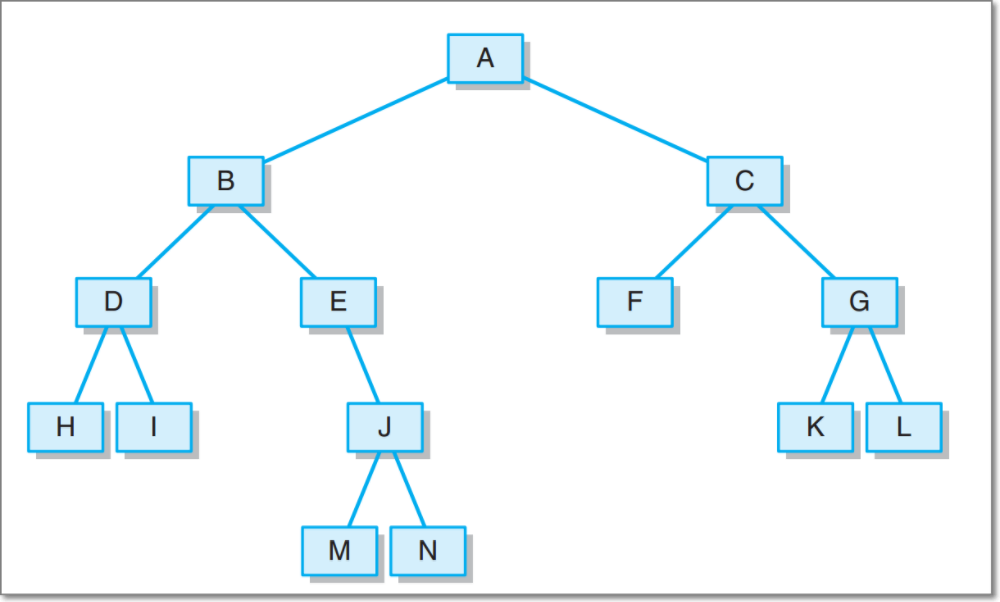
基于LinkedBinaryTree,实现基于(中序,先序)序列构造唯一一棵二㕚树的功能,比如给出中序HDIBEMJNAFCKGL和后序ABDHIEJMNCFGKL,构造出附图中的树
用JUnit或自己编写驱动类对自己实现的功能进行测试,提交测试代码运行截图,要全屏,包含自己的学号信息
课下把代码推送到代码托管平台
3-决策树
自己设计并实现一颗决策树
提交测试代码运行截图,要全屏,包含自己的学号信息
课下把代码推送到代码托管平台
4-表达式树
输入中缀表达式,使用树将中缀表达式转换为后缀表达式,并输出后缀表达式和计算结果(如果没有用树,则为0分)
提交测试代码运行截图,要全屏,包含自己的学号信息
课下把代码推送到代码托管平台
5-二叉查找树
完成PP11.3
提交测试代码运行截图,要全屏,包含自己的学号信息
课下把代码推送到代码托管平台
6-红黑树分析
参考http://www.cnblogs.com/rocedu/p/7483915.html对Java中的红黑树(TreeMap,HashMap)进行源码分析,并在实验报告中体现分析结果。
(C:Program FilesJavajdk-11.0.1libsrcjava.basejavautil)
2. 实验过程及结果
实现二叉树
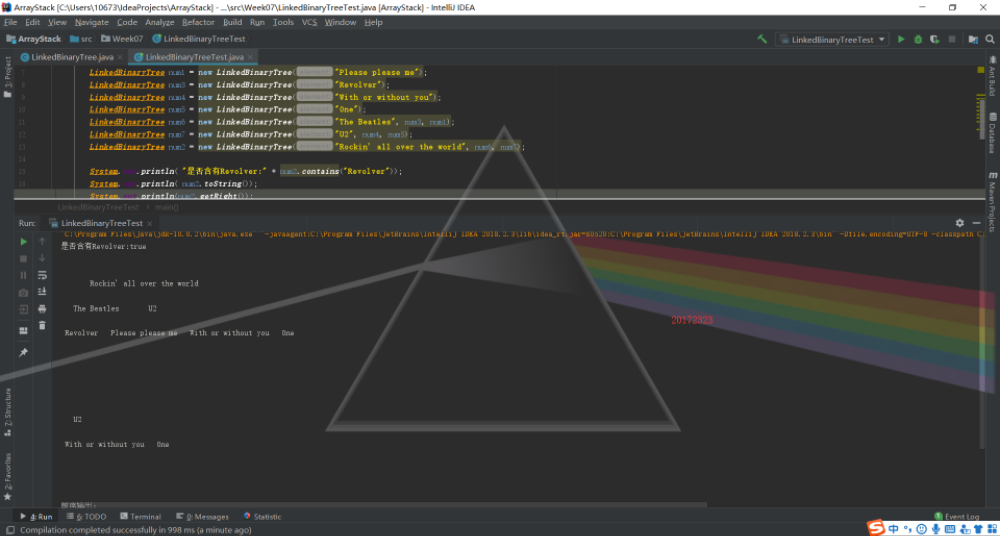
第一部分没有什么难度,要求LinkedBinaryTree类实现的各种方法教材中都已经给出,所以只需编写测试类方法进行测试就行了。实验结果如下
第一张图测试了contains、toString方法,toString使用的是表达式树中的printTree方法
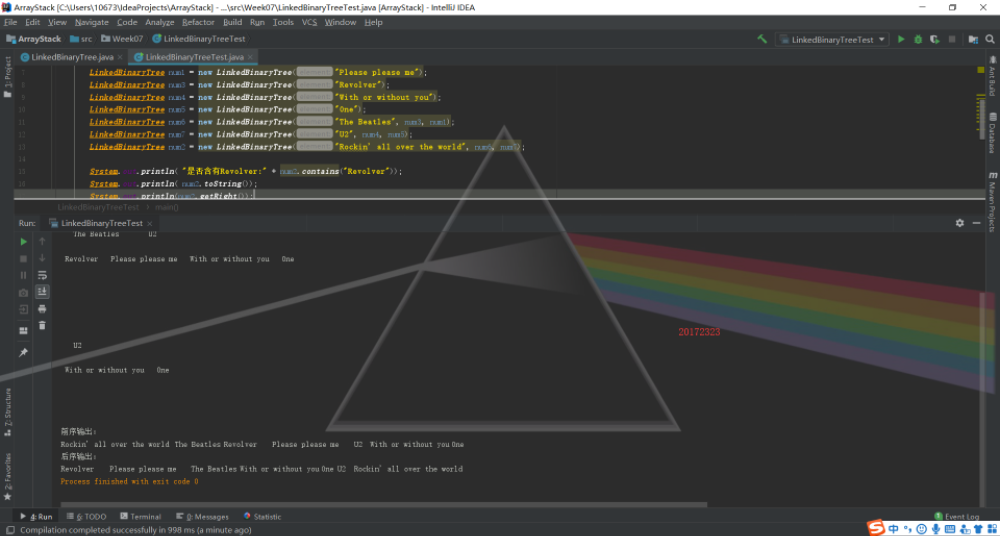
第二张图展示了getRight和前序后序输出方法的测试
中序先序序列构造二叉树
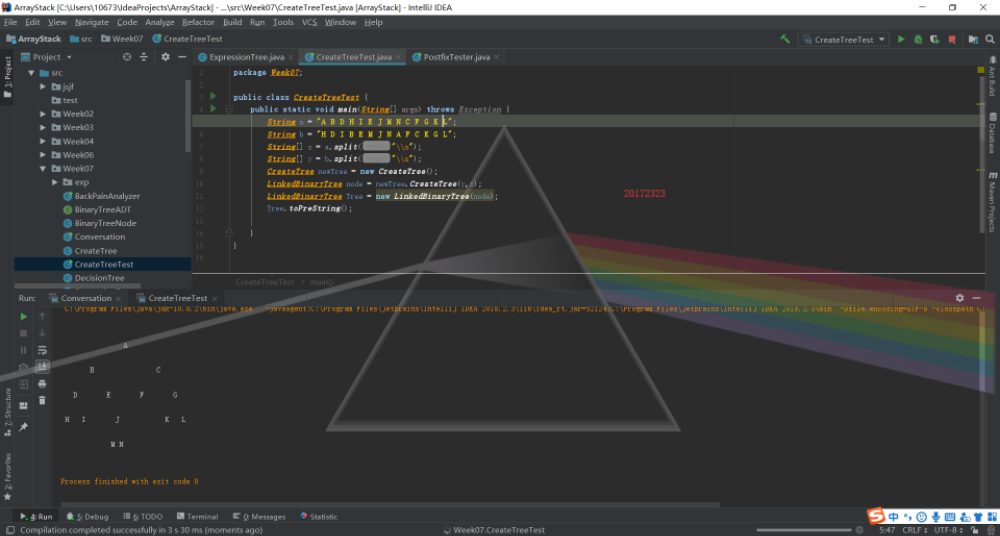
第二部分解决的关键在如何通过中序和先序数组推出树的结构。首先先序输出因为是从树的根结点开始的,所以先序数组的第一个就是整个二叉树的根结点了。然后根据这个数到中序列表中去寻找对应的,以这个值为界,前半部分就是它的左子树,后半部分就是它的右子树。重复上述步骤就可以继续划分子树的结构直到结束。
这个方法首先判断前序和中序数组是否为空或者两个长度是否相等,如果为空或者不相等就抛出异常,否则就进行构造树的操作,首先取出前序列表第一个值,与中序列表进行比对,找到对应的值的位置,然后以此为界将它的左子树的前序中序数组和右子树的前序中序数组分别存入新的数组中进行递归操作,直到最后每一个数组里只存有一个数时,调用二叉树的构造方法,就可以得到一棵二叉树。
结果如图
决策树
第三部分的内容很简单,参照书上代码背部疼痛诊断器的内容,修改其中的语句就可以了
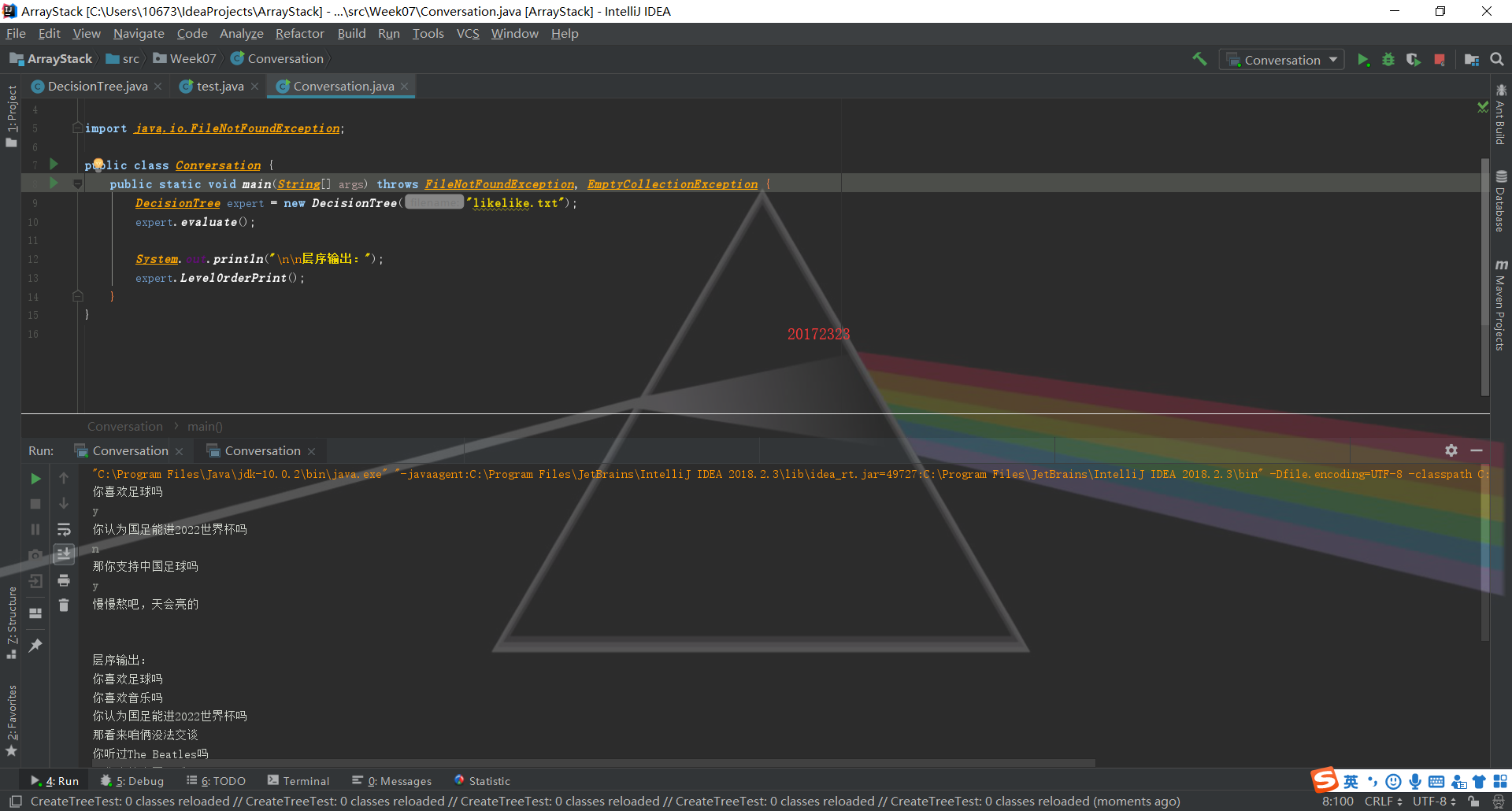
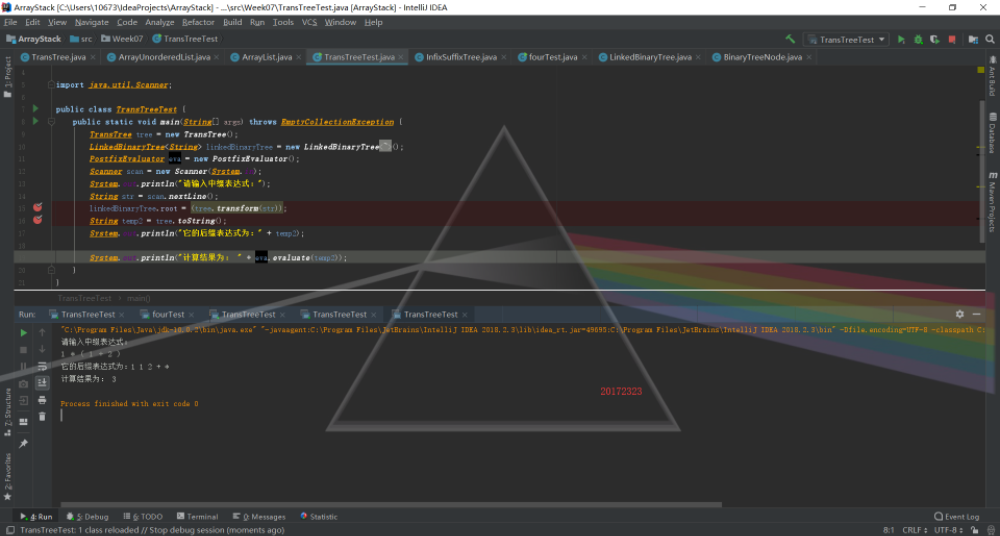
表达式树
这是实验最难的一部分。这一部分思考了很久,结合了很多资料。主要是需要解决带括号的问题,设置两个链表,一个存放String字符、一个存放树。通过split方法将中缀式断开,判断每一个字符,如果是加减运算符,就把它存到String链表的末尾,如果是乘除运算符,就判断下一个字符是否是“(”,如果是的话,将括号里的运算式提出来,运用递归算法先将这一串小式子转换成二叉树,放入树的链表中,如果不是的话,就以当前字符的下一个作为新树的子树,当前字符为根结点,从树的链表中取出最末一位树作为左子树,形成一颗新树再存回树的链表中。如果是左括号,需要一直遍历接下来的符号,直到找到右括号,把中间的式子提出来单独构造新树。如果是数字,那么就直接放在树的数组中,当作只有根结点的树。最后通过迭代器的方法进行输出
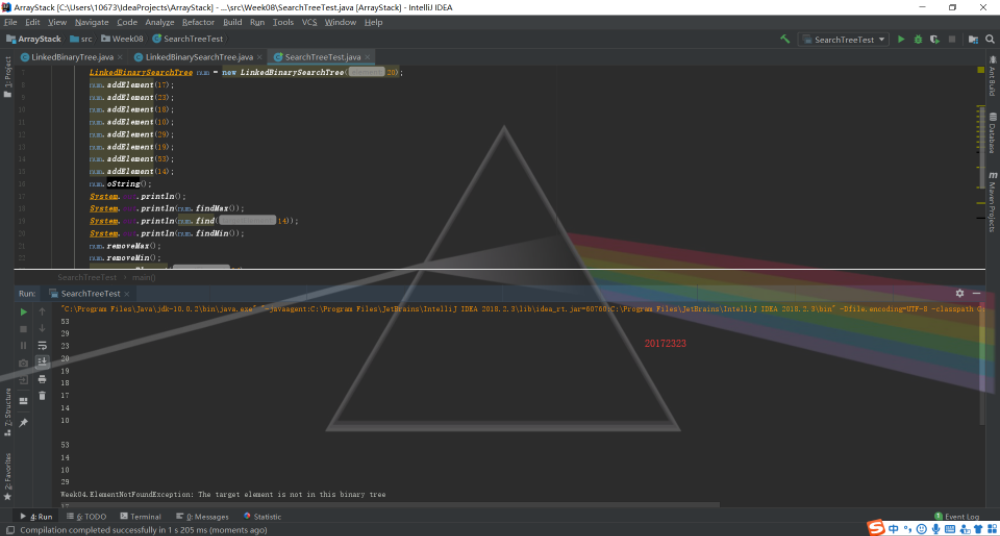
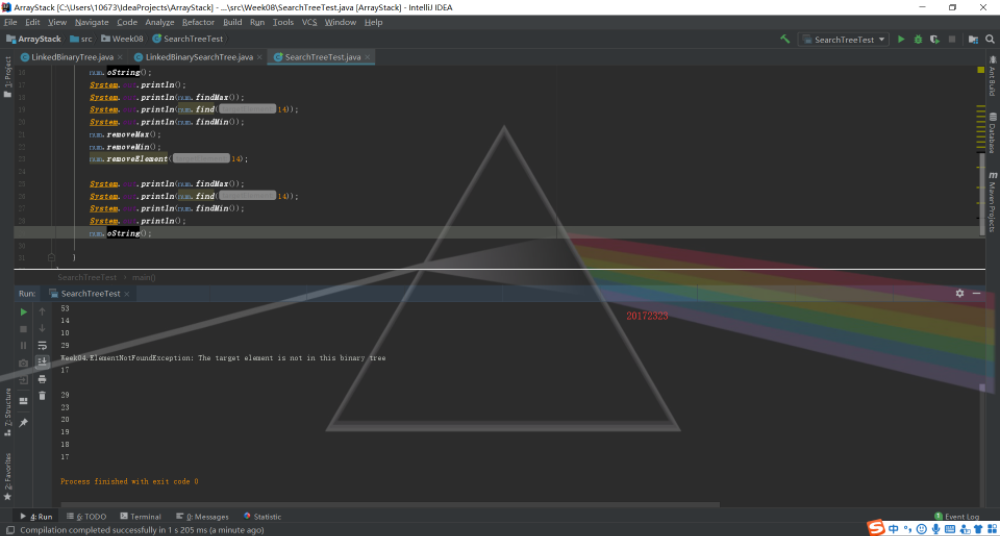
二叉查找树
这一部分内容就是运行PP11.3,没有什么可以记录的
红黑树分析
红黑树
- 每个节点都只能是红色或者黑色
- 根节点是黑色
- 每个叶子节点是黑色的
- 如果一个节点是红色的,则它的两个子节点都是黑色的
- 从任意一个节点到每个叶子节点的所有路径都包含相同数目的黑色节点
TreeMap
首先是TreeMap是基于红黑树实现的,是一个有序的Key-value集合,继承了AbstractMap,所以是一个Map即Key-value集合。它的基本操作包括了containsKey、get、put和remove方法
TreeMap基于红黑树(Red-Black tree)实现。该映射根据其键的自然顺序进行排序,或者根据创建映射时提供的 Comparator 进行排序,具体取决于使用的构造方法。
红黑树包含了六个基本组成部分:key(键)、value(值)、left(左孩子)、right(右孩子)、parent(父节点)、color(颜色)。Entry节点根据key进行排序,Entry节点包含的内容为value。
TreeMap的构造函数
// 默认构造函数。使用该构造函数,TreeMap中的元素按照自然排序进行排列。
TreeMap()
// 创建的TreeMap包含Map
TreeMap(Map<? extends K, ? extends V> copyFrom)
// 指定Tree的比较器
TreeMap(Comparator<? super K> comparator)
// 创建的TreeSet包含copyFrom
TreeMap(SortedMap<K, ? extends V> copyFrom)
设置结点的颜色
private static final boolean RED = false;
private static final boolean BLACK = true;
Entry相关函数
public Map.Entry<K,V> firstEntry() {
return exportEntry(getFirstEntry());
}
final Entry<K,V> getFirstEntry() {
Entry<K,V> p = root;
if (p != null)
while (p.left != null)
p = p.left;
return p;
}
FirstEntry和getFirstEntry都用于获取第一个结点,firstEntry是对外的,getFirstEntry是对内的。这样做是为了防止用户修改返回的Entry,同时,getFirstEntry返回的对象除了可以进行getKey、getValue的操作之外,还可以通过setValue修改图。
Key相关函数
ceilingKey(K key)的作用是“返回大于/等于key的最小的键值对所对应的KEY,没有的话返回null”
public K ceilingKey(K key) {
return keyOrNull(getCeilingEntry(key));
}
ceilingKey()是通过getCeilingEntry()实现的。keyOrNull()是获取节点的key,没有的话,返回null。
static <K,V> K keyOrNull(TreeMap.Entry<K,V> e) {
return e == null? null : e.key;
}
getCeilingEntry(K key)的作用是“获取TreeMap中大于/等于key的最小的节点,若不存在(即TreeMap中所有节点的键都比key大),就返回null”。
遍历方法
遍历的方式包括遍历TreeMap的键值对(entrySet),遍历TreeMap的键(KeySet)、遍历TreeMap的值(value)三种。
通过keyIterator() 和 descendingKeyIterator()来说明,keyIterator()的作用是返回顺序的KEY的集合,
descendingKeyIterator()的作用是返回逆序的KEY的集合。
Iterator<K> keyIterator() {
return new KeyIterator(getFirstEntry());
}
final class KeyIterator extends PrivateEntryIterator<K> {
KeyIterator(Entry<K,V> first) {
super(first);
}
public K next() {
return nextEntry().key;
}
}
HashMap
HashMap由数组+链表组成的,数组是HashMap的主体.
HashMap的主干是一个Entry数组。Entry是HashMap的基本组成单元,每一个Entry包含一个key-value键值对。
构造函数
public HashMap(int initialCapacity, float loadFactor) {
//此处对传入的初始容量进行校验,最大不能超过MAXIMUM_CAPACITY = 1<<30(230)
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal initial capacity: " +
initialCapacity);
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal load factor: " +
loadFactor);
this.loadFactor = loadFactor;
threshold = initialCapacity;
init();//init方法在HashMap中没有实际实现,不过在其子类如 linkedHashMap中就会有对应实现
}
put操作
public V put(K key, V value) {
//如果table数组为空数组{},进行数组填充(为table分配实际内存空间),入参为threshold,此时threshold为initialCapacity 默认是1<<4(24=16)
if (table == EMPTY_TABLE) {
inflateTable(threshold);
}
//如果key为null,存储位置为table[0]或table[0]的冲突链上
if (key == null)
return putForNullKey(value);
int hash = hash(key);//对key的hashcode进一步计算,确保散列均匀
int i = indexFor(hash, table.length);//获取在table中的实际位置
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
//如果该对应数据已存在,执行覆盖操作。用新value替换旧value,并返回旧value
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;//保证并发访问时,若HashMap内部结构发生变化,快速响应失败
addEntry(hash, key, value, i);//新增一个entry
return null;
}
在常规构造器中,没有为数组table分配内存空间(有一个入参为指定Map的构造器例外),而是在执行put操作的时候才真正构建table数组
3.代码托管
实验二-1-实现二叉树
实验二 树-2-中序先序序列构造二叉树
实验二 树-3-决策树
实验二 树-4-表达式树
实验二 树-5-二叉查找树
4.其他
这实验,简单的简单难的难,那个红黑树的源码分析如果没有资料帮扶,我真可能是一筹莫展,反正有些难受
5.参考资料
-
《Java程序设计与数据结构教程(第二版)》
-
《Java程序设计与数据结构教程(第二版)》学习指导