数据交换平台架构
一、数据交换平台定义(百度百科)
数据交换平台是指将分散建设的若干应用信息系统进行整合,通过计算机网络构建的信息交换平台,它使若干个应用子系统进行信息/数据的传输及共享,提高信息资源的利用率,成为进行信息化建设的基本目标,保证分布异构系统之间互联互通,建立中心数据库,完成数据的抽取、集中、加载、展现,构造统一的数据处理和交换。
二、Why数据交换平台?
1.分布式的需要
PS:(分布式出现的两个驱动要素:1.业务场景越来越复杂,需要进行系统拆分;2.性能的需要)
场景举例一:EDA
通过数据交换平台,把数据库Log事件(如Mysql的binlog)发送到MQ,驱动后续流程(如:刷新缓存,构造搜索引擎,业务流程驱动<如:下单之后发短信>等)
场景举例二:CQRS
【命令、查询分离】的思想本质上就是同一份数据建立两套视图:一套是模型清晰的Domain-Mode,代表业务实体,满足复杂业务逻辑的需要;另一套是查询视图,主要面向查询场景,不关心数据库范式,只关心查询最优最快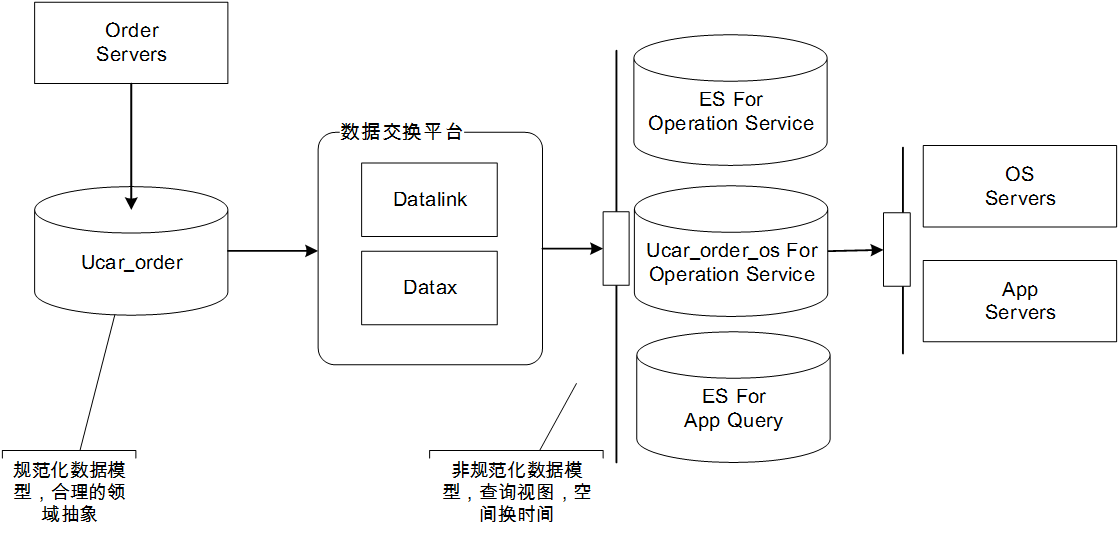
2.容灾备份的需要
场景举例一:多机房
多中心、多备份、异地多活等是很多大公司正在实践或者已经实践过的技术难题,这中间的核心便是一整套完整的数据同步方案场景举例二:数据镜像
通过数据交换平台,可以创建各种类型的DB镜像,满足不同场景下的使用需要场景举例三:数据归档
通过增量交换,可以实现实时归档3.异构、重构的需要
场景举例一:DB升级换代
通过数据交换平台解决升级过程中的版本兼容性问题场景举例二:资产复用
任何一个公司都有大大小小的各种IT资产,通过数据交换平台,可以实现这些核心资产的整合、复用场景举例三:迁库、拆库
系统进行重构,业务应用要拆分为两个子系统,对应的数据库由一个拆成两个,需要数据交换平台先进行全量Copy,再进行增量同步,然后配合系统完成迁移对接,如下所示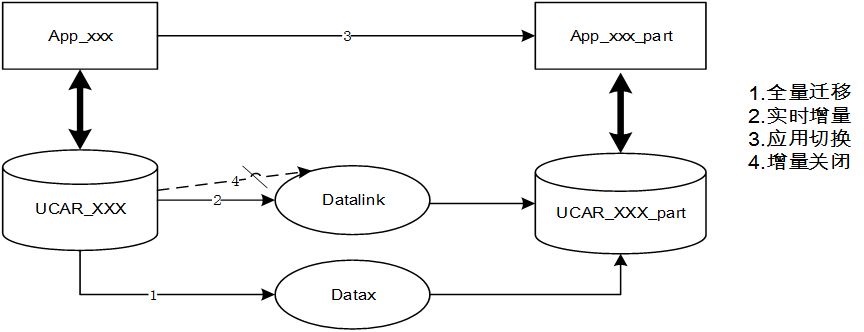
三、(神州优车)数据交换平台总体架构
总体架构图如下所示,整个平台由三个子系统组成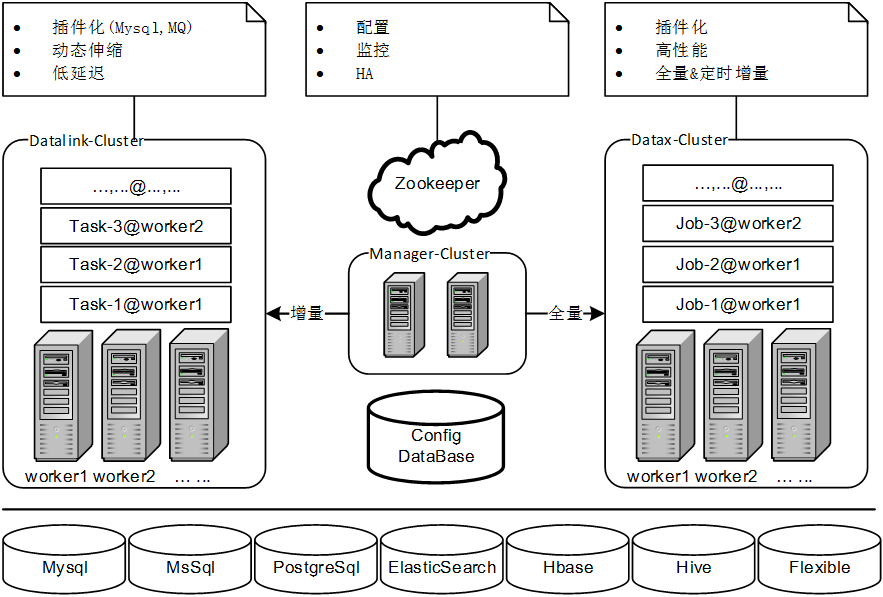
ucar_datalink(增量同步子系统)
ucar_datalink是优车技术团队自研的一套数据同步中间件,主要满足各异构数据源之间的实时增量同步需求,具有高伸缩性、高扩展性和高性能等优点ucar_dataX(全量同步子系统)
ucar_datax是对Alibaba开源的datax进行了深度定制和改造,满足集团内的全量数据同步需求Admin(管理监控子系统)
管理子系统对整个增量和全量集群进行运维管理,包括:HA、同步申请自动处理、延迟监控、异常监控、机器监控等等四、Datalink产品介绍
Datalink借鉴了数个开源产品的设计
- 借鉴了Kafka-Connect的基础设施:分组、HA、Rebalance协议、Task模型等
- 借鉴了Otter的诸多功能模型:领域模型抽象、双向同步、数据压缩合并、数据权重算法等
- 参与了Linkedin的Databus的一些设计思想
1.Datalink的基础设施模型
Manager
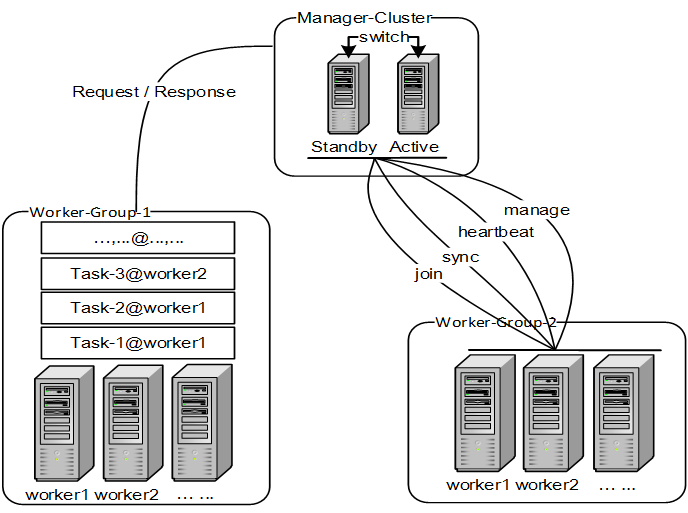
整个Datalink集群的大脑,负载均衡协调器、配置管理、集群监控Group
分组是一个核心逻辑概念,通过分组实现组内自治、组间隔离,便于进行拆分管理Worker
Worker是Task的运行容器,一个Worker节点运行一系列同步任务,Worker归属于某个分组Task
数据同步任务实例,由一个reader和至少一个writer组成,归属于某个分组,在一个分组内Task通过一定的负载均衡策略,被分配到不同的Worker上执行Rebalance
Rebalance单位:分组;
Rebalance时机:Manager主备切换、Worker加入分组、Worker离开分组、新增Task、删除Task2.Datalink的领域模型

Contract
针对每种类型的数据库,我们会抽象一套契约类型,有了这套契约便可实现Reader和Writer的任意组合
比如我们针对关系型数据库抽象一个契约,契约的核心类名为RdbEventRecord,代表一条数据库log事件变更,围绕这个契约,我们可以开发若干插件
如果是Reader插件,这个插件的一个核心功能就是做数据类型转换,如MysqlReader、SqlserverReader、OracleReader分别会把自己对应数据库的底层log-event转换为RdbEventRecord即可
如果是Writer插件,需要的是针对每一种契约实现一个处理器,如HbaseWriter,其主要目的是往hbase写数据,但是在不同的Task中,它对接的Reader是随机的,所以需要的是对不同类型契约的数据做适配Business Model
领域模型借鉴了Aalibaba-Otter的一些思想,针对数据同步领域的一些常见功能,我们进行了深度分析和抽象
* MediaSource:
是对数据源的抽象,所有类型的数据源都会保存到这个模型,神州内部已经支持的数据源有 MYSQL, SQLSERVER, ORACLE, HDFS, HBASE, ELASTICSEARCH, ZOOKEEPER,POSTGRESQL
* Media:
是对数据存储单元的抽象,可以是关系型数据库的表、Hbase的表、ElastaicSearch的索引等等
* MediaMapping:
是对数据交换协议的抽象,所有类型的Media之间的数据同步关系都保存到这个模型
* 支持的功能
依托这套领域模型,可以实现的一些主要功能特性如下所示
库别名
表别名
列别名
列白名单
列黑名单
多表合一
多表聚合
主键跳过
同步拦截器
按权重同步3.Datalink的插件模型

Task&Plugin
* Task是Datalink中的一个核心概念,一个运行中的Task就是一个数据同步任务
* Task由一个Reader和若干个Writer组成,即可以实现一对多的数据同步
* Task的数据同步流程:由Reader端取数据,然后放到内存队列,Writer端消费数据,成功的话执行Ack操作,失败的话执行Rollback操作
* Task提供了插件机制,一个Task只有在运行时才知道自己组装的Reader和Writer是什么
* Task的Reader和Writer插件在运行时有自己独立的ClassLoader,以解决同一进程中jar包冲突的问题
* 通过这套插件模型我们可以实现最大程度的基础设施复用:一套框架支持各种数据源之间的增量同步需求,框架稳定之后,后期关注重点只需要放到插件开发上即可,目前我们内部实现的插件有:
MysqlReader
FlexibleQReader(FlexibleQ:内部消息中间件)
RdbmsWriter
HbaseReader(建设中)
ElasticSearchWriter
HdfsWriter
FlexibleQWriter
HbaseWriter(建设中)(神州优车内部)Datalink同步场景举例
1.Mysql同步到RDBMS
简介
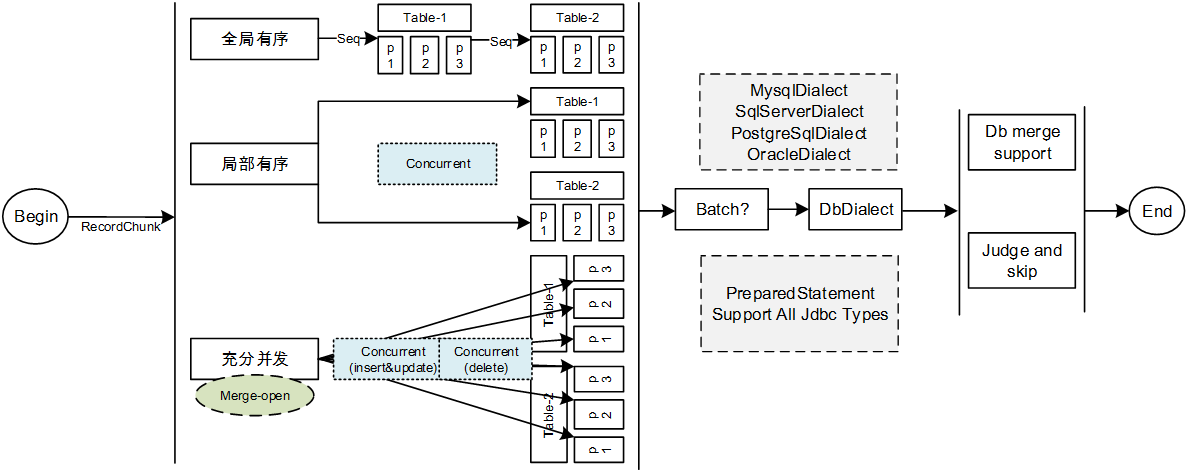
* 该场景下的数据同步主要分为两种:一种是线上各个系统间的基础参数表同步,另外一种是线上数据同步到OLAP系统(主要是BI)
* 支持多种同步模式
全局有序同步:完全按照源端binlog的执行顺序进行重放
局部有序同步:以表为单位进行聚合,保证单表内同步是有序的
完全并发:当开启merger功能的时候,在merge合并完之后,能保证同一张表的同一条数据只有一条binlog事件,此时可以完全打乱顺序,保证最终一致即可2.Mysql同步到ElasticSearch
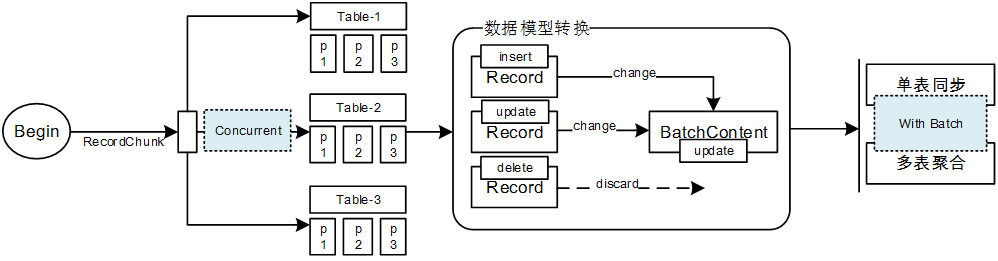
简介
* 订单库(Mysql)为应对线上的各种交易请求已经足够忙碌,查询操作必须放到二级系统中去做,所以实现了Mysql到ES的同步,所有查询走ES
* 在同步过程中,可以实现多表聚合,即将Mysql中多张有外键关系的表,在同步过程中进行聚合,到ES端,多张表的数据合并成一条3.Mysql同步到Hadoop
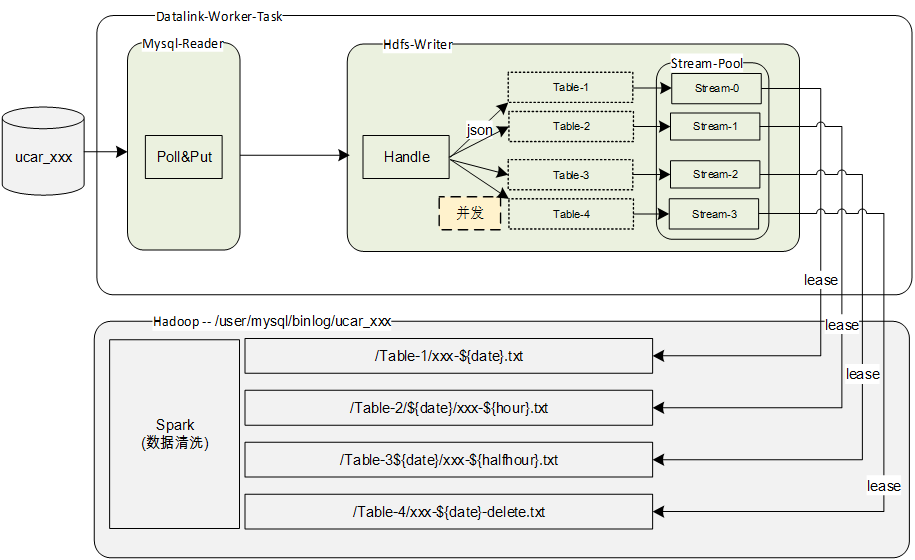
简介
* 作为大数据平台的第一层,datalink负责把线上生产库的binlog变更同步到Hadoop
* 数据处理平台每天凌晨对T-1的数据进行清洗、去重,把同步过去的binlog数据更新到spark-hive4.Mysql同步到MQ
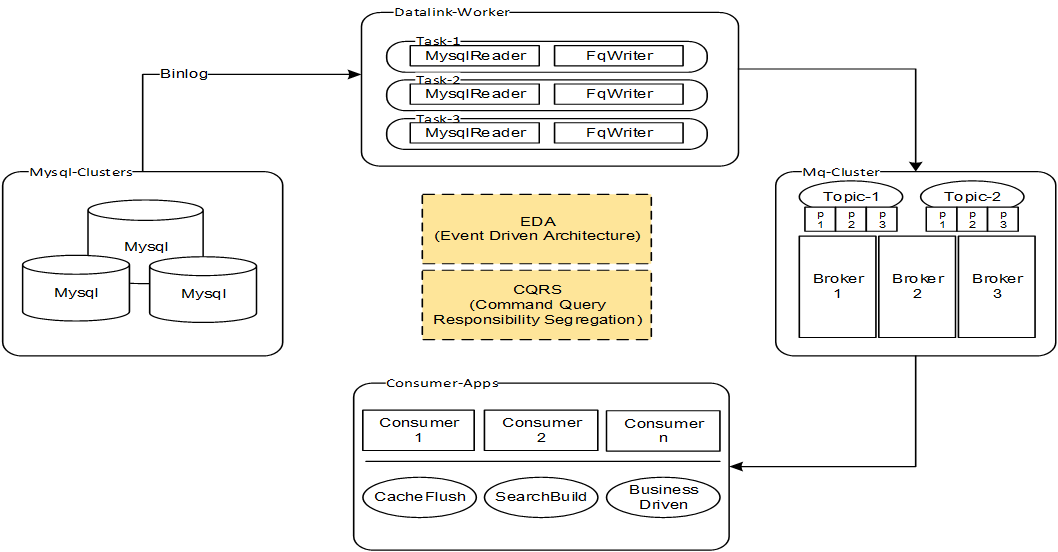
简介
* 目前我们内部主要是通过监听binlog事件实现【缓存刷新】和【业务通知】功能5.分布式DB同步
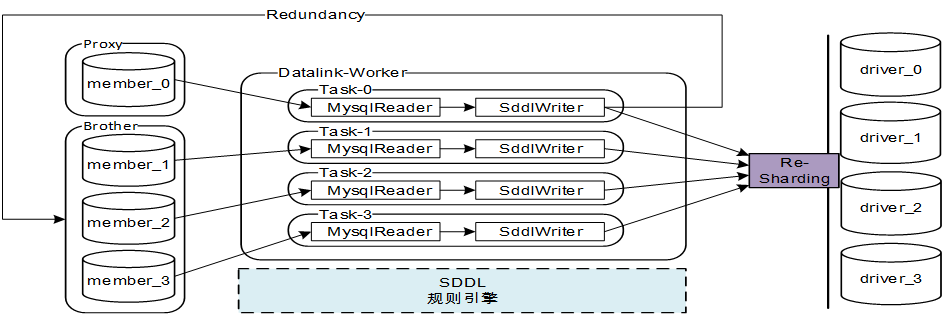
简介
* 类似于电商平台【买家和卖家】的划分,神州专车平台对应的划分为【乘客和司机】,为应对性能压力,我们对DB进行了分库处理,这样就产生了两个维度,主维度是乘客,子维度是司机
我们需要把主维度产生的数据进行Re-Sharding操作同步到司机维度的分库,以满足司机数据查询的需求主要列举这些,后续梳理完之后再进行补充
标签: DataSync