数据分片
在分布式存储系统中,数据需要分散存储在多台设备上,数据分片(Sharding)就是用来确定数据在多台存储设备上分布的技术。数据分片要达到三个目的:
-
分布均匀,即每台设备上的数据量要尽可能相近;
-
负载均衡,即每台设备上的请求量要尽可能相近;
-
扩缩容时产生的数据迁移尽可能少。
数据分片方法
数据分片一般都是使用Key或Key的哈希值来计算Key的分布,常见的几种数据分片的方法如下:
-
划分号段。这种一般适用于Key为整型的情况,每台设备上存放相同大小的号段区间,如把Key为[1, 10000]的数据放在第一台设备上,把Key为[10001, 20000]的数据放在第二台设备上,依次类推。这种方法实现很简单,扩容也比较方便,成倍增加设备即可,如原来有N台设备,再新增N台设备来扩容,把每台老设备上一半的数据迁移到新设备上,原来号段为[1, 10000]的设备,扩容后只保留号段[1, 5000]的数据,把号段为[5001, 10000]的数据迁移到一台新增的设备上。此方法的缺点是数据可能分布不均匀,如小号段数据量可能比大号段的数据量要大,同样的各个号段的热度也可能不一样,导致各个设备的负载不均衡;并且扩容也不够灵活,只能成倍地增加设备。
-
取模。这种方法先计算Key的哈希值,再对设备数量取模(整型的Key也可直接用Key取模),假设有N台设备,编号为0~N-1,通过Hash(Key)%N就可以确定数据所在的设备编号。这种方法实现也非常简单,数据分布和负载也会比较均匀,可以新增任何数量的设备来扩容。主要的问题是扩容的时候,会产生大量的数据迁移,比如从N台设备扩容到N+1台,绝大部分的数据都要在设备间进行迁移。
-
检索表。在检索表中存储Key和设备的映射关系,通过查找检索表就可以确定数据分布,这里的检索表也可以比较灵活,可以对每个Key都存储映射关系,也可结合号段划分等方法来减小检索表的容量。这样可以做到数据均匀分布、负载均衡和扩缩容数据迁移量少。缺点是需要存储检索表的空间可能比较大,并且为了保证扩缩容引起的数据迁移量比较少,确定映射关系的算法也比较复杂。
-
一致性哈希。一致性哈希算法(Consistent Hashing)在1997年由麻省理工学院提出的一种分布式哈希(DHT)实现算法,设计目标是为了解决因特网中的热点(Hot Spot)问题,该方法的详细介绍参考此处http://blog.csdn.net/sparkliang/article/details/5279393。一致性哈希的算法简单而巧妙,很容易做到数据均分布,其单调性也保证了扩缩容的数据迁移是比较少的。
通过上面的对比,在这个系统选择一致性哈希的方法来进行数据分片。
虚拟服务器
为了让系统有更好的扩展性,这里提出存储层VServer(虚拟服务器)的概念,一个VServer是一个逻辑上的存储服务器,是分布式存储系统的一个存储单元,一台物理设备上可以部署多个VServer,一个VServer支持一个写进程和多个读进程。
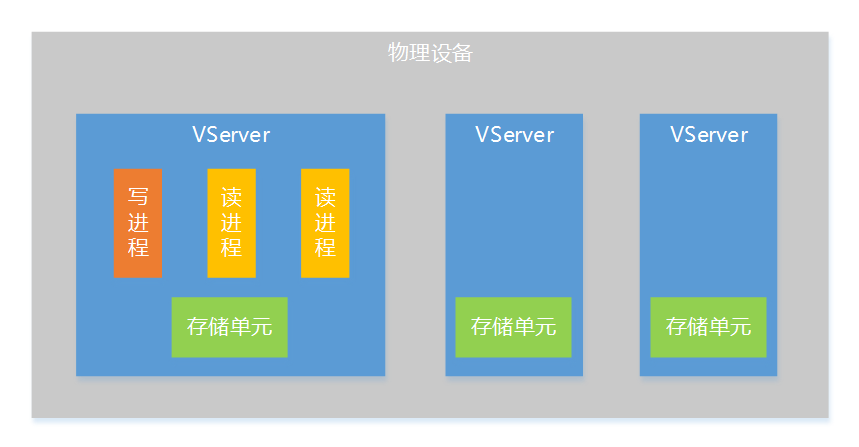
通过VServer的方式,会有下面一些好处:
-
提高单机性能。为了不引入复杂的锁机制,采用了单写进程的设计,如果单机只有一个写进程,写并发能力会受到限制,通过VServer方式把单机上的存储资源(内存、硬盘)划分为多个存储单元,这样就支持多个写进程同时工作,大大提升单机写并发能力。
-
部署扩展性更好。VServer的方式在部署上非常灵活,可以根据单机的资源情况来确定VServer的数量,针对不同的机型配置不同的VServer数量,这样不同的机型都能充分利用机器上的资源,即使在一个系统中使用多种机型,也能做到机器的负载比较均衡。
一致性哈希的应用
数据分片是在接口层实现的,目的是把数据均匀地划分到不同的VServer上。有了接口层的存在,逻辑层寻址就轻量了很多,寻址存储层VServer的工作全部由接口层负责,逻辑层只需要随机选一个接口层机器访问即可。
接口层使用了一致性哈希的割环算法来实现数据分片,在割环算法中,为了让数据均匀分布到各个VServer,每个VServer需要有多个VNode(虚拟节点)。一个Key寻址的过程如下图所示,首先根据Hash(Key)在哈希环上找到对应的VNode,在根据VNode和VServer的映射表确定所属的VServer。
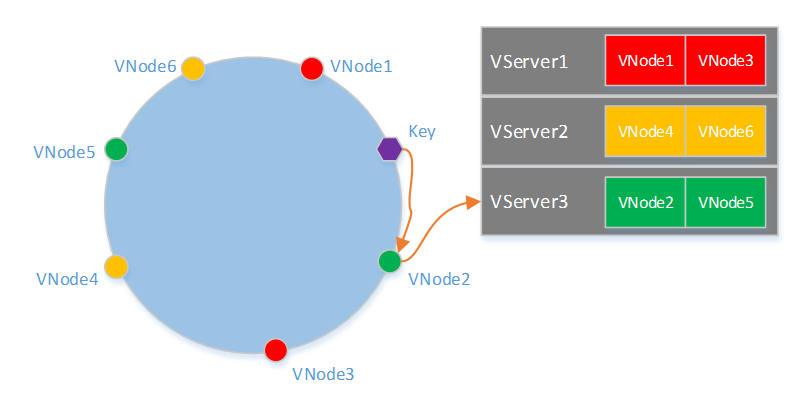
由上述查找过程可知,需要事先离线计算出VNode在哈希环上的分布、VServer和VNode映射关系。为了是计算结果具有通用性,即在拥有任何数量VServer的一个系统都可以使用该结果得到一致性哈希的映射表,这就要求结果是与机器无关的,比如不能使用IP来计算VNode的哈希值。在计算前需要确定每个VServer包含的VNode数量,以及一个系统所支持的最大VServer数量。一个简单的方法是类似上文链接中提到的方法,但不能和IP相关,可以改用VServer和VNode的编号来计算哈希值,如Hash("1#1"),Hash("1#2")… 这种方法要求一个VServer包含的VNode的数量比较多,大概需要500个才能使各个VServer上的数据比较均匀。当然还有其他的一些方法做到一个VServer上包含更少的VNode数量,并且让数据分布偏差在一定范围内。
Google提出了一种新的一致性哈希算法Jump Consistent Hash,此算法零内存消耗,均匀分配,快速,并且只有5行代码,优势非常明显,详细介绍见此处http://my.oschina.net/u/658658/blog/424161。和上面介绍的方法相比,一个最大的不同点是,在扩容重新分布数据时,在上面的方法中,新机器的一个VNode上的数据只会来自一个老机器上的VNode,而这种方法是会来自所有老机器上的VNode。这个问题可能会导致一些设计上复杂化,所以使用的时候要慎重考虑。