设计模式应用案例(上)
前文一共介绍了四人帮(Gang of Four)总结的的11个设计模式,对初学者而言,光看文字描述和UML类图略显抽象。本着Learning in Doing的原则,本文将举一些实际的业务需求场景,以C#代码为例,讲述在编程的过程中如何应用设计模式,实现模块间低耦合,高内聚,编写出优雅的代码。需说明的是,接下来的例子相对简单,省略了业务逻辑代码,目的是为了让大家专注于设计模式的应用,忽略业务逻辑本身的复杂性,毕竟本文的目的是加深对设计模式本身的理解。
一.Façade模式
业务场景:圣象饮料公司需汇总每个季度矿泉水的销量,并和竞争对手的销量进行比较,并且以季度报表的形式汇报管理层。当前的系统情况是:统计内部商品的销量由类SelfProduct、竞争对手商品的销量由类CompetitorProject负责,该需求用Facade模式实现如下:

namespace PartternCase { public class SelfProduct {//Class A in UML public decimal StatSales(DateTime start, DateTime end, string kind); } public class CompetitorProduct {//Class B in UML public decimal StatSales(DateTime start, DateTime end, string kind); } public class ReportFacade {//Facade in UML private SelfProduct Self { get; set; } private CompetitorProduct Competitor { get; set; } public ReportFacade(SelfProduct self, CompetitorProduct competitor) { Self = self; Competitor = competitor; } public Tuple<decimal, decimal> StatSelling(DateTime start, DateTime end) {//Interface for client call return Tuple.Create(Self.StatSales(start, end, "MineralWater"), Competitor.StatSales(start, end, "MineralWater")); } } }
二.Adapter模式
业务场景:需要提供一个快速创建Word文档的API,微软提供的Office对象模型太复杂,创建Word时需要传入太多的缺省参数。下面是用对象Adapter模式实现的代码(C#不支持多继承,在此不介绍类Adapter模式,况且也不推荐使用):
namespace PartternCase { public interface IWordAdapter {//Target in UML //Interface for client call void CreateWord(string filePath); } public class WordAdapter : IWordAdapter {//Adapter in UML public void CreateWord(string filePath) { Object Nothing = System.Reflection.Missing.Value; //MS default word creator is Adaptee Application wordApp = new Microsoft.Office.Interop.Word.ApplicationClass(); Document wordDoc = wordApp.Documents.Add(ref Nothing, ref Nothing, ref Nothing, ref Nothing); wordDoc.SaveAs(ref filePath, ref Nothing, ref Nothing, ref Nothing, ref Nothing, ref Nothing, ref Nothing, ref Nothing, ref Nothing, ref Nothing, ref Nothing, ref Nothing, ref Nothing, ref Nothing, ref Nothing, ref Nothing); wordDoc.Close(ref Nothing, ref Nothing, ref Nothing); wordApp.Quit(ref Nothing, ref Nothing, ref Nothing); } } }
三.Strategy模式
业务场景:假设用户熟悉每种排序算法的应用场景,需要在界面自己选择排序算法(众所周知,排序算法有很多种,各自适合不同的场景),将一组数字排序后,打印在窗口。采用策略模式实现的代码如下:
namespace PartternCase { public class SequencePrinter {//Context in UML private Sorter Sorter { get; set; } public SequencePrinter(Sorter sorter) {//Interface for client call
Sorter = sorter; } public void Perform(IList<int> sequences) {//Assign relative sorter by criteria at runtime context sequences = Sorter.Rank(sequences); foreach (var sequence in sequences) { Console.WriteLine("Number is " + sequence); } } } public abstract class Sorter {//Strategy in UML public abstract IList<int> Rank(IList<int> source); } public class BubbleSorter : Sorter {//ConcreteStrategyA in UML public override IList<int> Rank(IList<int> source); } public class QuickSorter : Sorter {//ConcreteStrategyB in UML public override IList<int> Rank(IList<int> source); } }
四.Bridge模式
业务场景:将上述Strategy模式的业务场景做一个扩展,正好就是采用Bridge模式的最佳场景,即:用户可以在界面选择外排序算法和打印终端,将一组数据排序后,打印到相应的终端上。采用Bridge模式的实现代码如下:
namespace PartternCase { public abstract class AbstractSequencePrinter {//Abstraction in UML protected Sorter Sorter { get; set; } protected AbstractSequencePrinter(Sorter sorter) {//Assign relative sorter by criteria at runtime context Sorter = sorter; } public abstract void Perform(IList<int> sequences); } public class ConsoleSequencePrinter : AbstractSequencePrinter {//RefinedAbstraction in UML public ConsoleSequencePrinter(Sorter sorter) : base(sorter) { } public override void Perform(IList<int> sequences) { sequences = Sorter.Rank(sequences); foreach (var sequence in sequences) { Console.WriteLine("Number is " + sequence); } } } public abstract class Sorter {//Implementor in UML public abstract IList<int> Rank(IList<int> source); } public class BubbleSorter : Sorter {//ConcreteImplementorA in UML public override IList<int> Rank(IList<int> source); } public class QuickSorter : Sorter {//ConcreteImplementorB in UML public override IList<int> Rank(IList<int> source); } }
五.Abstract Factory模式
业务场景:圣天基金公司旗下有两种私募基金产品:主基金(Master Fund)和子基金(Feeder Fund)。两种基金的提款(Capital Call)规则和分配(Distribution)规则都存在明显差异,要求主基金的提款规则只能和主基金的分配规则搭配使用,不允许混淆。采用Abstract Factory模式的实现代码如下:
namespace PartternCase { public abstract class AbstractFund {//Abstract Factory //Interface for client call public abstract CapitalCallRule CreateCallRule(); public abstract DistributionRule CreateDistribRule(); } public class MasterFund : AbstractFund {//ConcreteFactory1 in UML public override CapitalCallRule CreateCallRule() { return new MasterCallRule(); } public override DistributionRule CreateDistribRule() { return new MasterDistribRule(); } } public class FeederFund : AbstractFund {//ConcreteFactory2 in UML public override CapitalCallRule CreateCallRule() { return new FeederCallRule(); } public override DistributionRule CreateDistribRule() { return new FeederDistribRule(); } } public abstract class CapitalCallRule {//AbstractProductA in UML } public class MasterCallRule : CapitalCallRule {//ConcreteProductA1 in UML } public class FeederCallRule : CapitalCallRule {//ConcreteProductA2 in UML } public abstract class DistributionRule {//AbstractProductB in UML } public class MasterDistribRule : DistributionRule {//ConcreteProductB1 in UML } public class FeederDistribRule : DistributionRule {//ConcreteProductB2 in UML } }
Radix Sort
为了完成二维数据快速分类,最先使用的是hash分类。
前几天我突然想,既然基数排序的时间复杂度也不高,而且可能比hash分类更稳定,所以不妨试一下。
在实现上我依次实现:
1、一维数组基数排序
基本解决主要问题,涵盖排序,包含改进的存储分配策略。
如果用链表来实现,大量的函数调用将耗费太多时间。
2、二维数组基数排序
主要是实现和原有程序的集成。
一、数据结构
下面是存储节点的主数据结构。
typedef struct tagPageList{ int * PagePtr; struct tagPageList * next; }PageList; typedef struct tagBucket{ int * currentPagePtr; int offset; PageList pl; PageList * currentPageListItem; }Bucket;
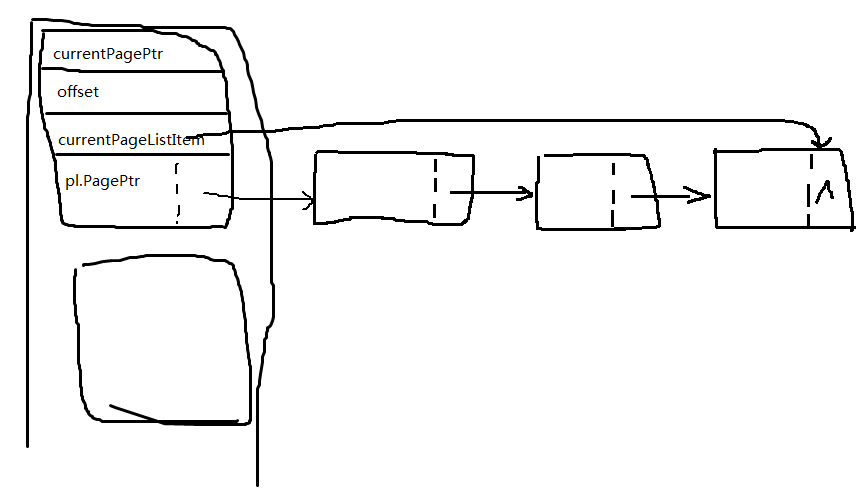
链表内是存储的一个4KB页面的指针。
每4KB页面可以存储最多1024个记录序号,如果是一维数组排序,那就直接存储数组元素了。
二、算法
基数排序可以分为MSD或者LSD。这里用的是LSD。
伪代码如下:
for i=0 to sizeof(sorted-element-type){ for each sorted-num{ cell = sorted-num bucketIdx = (cell>>8*i)&0xff bucket[bucketIdx] = cell } combine linked list nodes to overwrite original array }
C代码实现:
int main(){ HANDLE heap = NULL; Bucket bucket[BUCKETSLOTCOUNT]; PageList * pageListPool; int plpAvailable = 0; int * pages = NULL; int * pagesAvailable = NULL; int * objIdx; unsigned short * s; time_t timeBegin; time_t timeEnd; heap = HeapCreate(HEAP_NO_SERIALIZE|HEAP_GENERATE_EXCEPTIONS, 1024*1024, 0); if (heap != NULL){ pages = (int * )HeapAlloc(heap, 0, (TFSI/PAGEGRANULAR + BUCKETSLOTCOUNT + 8) * 4096); pageListPool = (PageList *)HeapAlloc(heap, 0, (TFSI/PAGEGRANULAR + 8) * sizeof(PageList)); s = (unsigned short *)HeapAlloc(heap, 0, TFSI*sizeof(unsigned short)); objIdx = (int *)HeapAlloc(heap, 0, TFSI * sizeof(int)); } MakeSure(pages != NULL && pageListPool != NULL && objIdx != NULL); for(int i=0; i<TFSI; i++) objIdx[i]=i; timeBegin = clock(); for (int i=0; i<TFSI; i++) s[i] = rand(); timeEnd = clock(); printf(" %f(s) consumed in generating numbers", (double)(timeEnd-timeBegin)/CLOCKS_PER_SEC); timeBegin = clock(); for (int t=0; t<sizeof(short); t++){ FillMemory(pages, (TFSI/PAGEGRANULAR + BUCKETSLOTCOUNT + 8) * 4096, 0xff); SecureZeroMemory(pageListPool, (TFSI/PAGEGRANULAR + 8) * sizeof(PageList)); pagesAvailable = pages; plpAvailable = 0; for(int i=0; i<256; i++){ bucket[i].currentPagePtr = pagesAvailable; bucket[i].offset = 0; bucket[i].pl.PagePtr = pagesAvailable; bucket[i].pl.next = NULL; pagesAvailable += PAGEGRANULAR; bucket[i].currentPageListItem = &(bucket[i].pl); } int bucketIdx; for (int i=0; i<TFSI; i++){ bucketIdx = (s[objIdx[i]]>>t*8)&0xff; MakeSure(bucketIdx < 256); //save(bucketIdx, objIdx[i]); bucket[bucketIdx].currentPagePtr[ bucket[bucketIdx].offset ] = objIdx[i]; bucket[bucketIdx].offset++; if (bucket[bucketIdx].offset == PAGEGRANULAR){ bucket[bucketIdx].currentPageListItem->next = &pageListPool[plpAvailable]; plpAvailable++; MakeSure(plpAvailable < TFSI/PAGEGRANULAR + 8); bucket[bucketIdx].currentPageListItem->next->PagePtr = pagesAvailable; bucket[bucketIdx].currentPageListItem->next->next = NULL; bucket[bucketIdx].currentPagePtr = pagesAvailable; bucket[bucketIdx].offset = 0; pagesAvailable += PAGEGRANULAR; MakeSure(pagesAvailable < pages+(TFSI/PAGEGRANULAR + BUCKETSLOTCOUNT + 8) * 1024); bucket[bucketIdx].currentPageListItem = bucket[bucketIdx].currentPageListItem->next; } } //update objIdx index int start = 0; for (int i=0; i<256; i++){ PageList * p; p = &(bucket[i].pl); while (p){ for (int t=0; t<PAGEGRANULAR; t++){ int idx = p->PagePtr[t]; if (idx != TERMINATOR){ objIdx[start] = idx; start++; } if (idx == TERMINATOR) break; } p = p->next; } } } timeEnd = clock(); printf(" %f(s) consumed in generating results", (double)(timeEnd-timeBegin)/CLOCKS_PER_SEC); //for (int i=0; i<TFSI; i++) printf("%d ", s[objIdx[i]]); HeapFree(heap, 0, pages); HeapFree(heap, 0, pageListPool); HeapFree(heap, 0, s); HeapFree(heap, 0, objIdx); HeapDestroy(heap); return 0; }
三、测试结果。
i7 3632QM @2.2GHz ==>TB 3.2GHz/ 8G RAM/ win8 64bit/VS2012 win32 release
1024*1024*100,1亿个随机生成 short 型数据。
1.438000(s) consumed in generating random numbers
4.563000(s) consumed in radix sort
12.719000(s) consumed in qsort
7.641000(s) consumed in std::sort
1024*1024*5 500万随机生成 short 型数据。
0.078000(s) consumed in generating random numbers
0.172000(s) consumed in radix sort
0.656000(s) consumed in qsort
0.390000(s) consumed in std::sort
1024*500
0.000000(s) consumed in generating random numbers
0.015000(s) consumed in radix sort
0.063000(s) consumed in qsort
0.047000(s) consumed in std::sort
四、讨论
二维数据分类上,性能相当于hash分类 约 1/3 。
比库例程稍快,慢的主要原因还是存储器,如果只是解决一维数组的话,调整下可以更快。
但对于二维数组多个线程同时操作,排序是不可接受的。