内存对齐机制深入剖析
在我的博客
由底层和逻辑说开去--c++之引用的深入剖析
里面提到内存对齐机制,我觉得这个有点意思,但是却不能仅从汇编层面就分析出个所以然来,因此就从inter的cpu 对内存访问路线的角度分析分析。
对于内存对齐 我们可以提出的问题从逻辑层面讲,就是内存对齐有什么意义,从底层来讲就是cpu怎么访问内存;
首先这个内存对齐机制是比较复杂的,百度一下很多人的理解,我发现大多数都和编译器以及c语言控制对齐方式联系起来,使的这个问题看似困难无比。其实我们 都知道,1.编译器又不是标准 2.c语言能更改对齐方式只能说明c语言强大,不能说明cpu按这种方式工作就是好的。嗯,那么我们就先从逻辑层面搞清楚,内存对齐是什么? 这个问题显然就很简单了,我的那个博客里也表现了这种现象,就是在分配内存的时候 比如结构体这些,会在一些元素后面进行填充。具体填充的规则百度上面巨多无比,我们的重心应该是内存对齐的意义: 这个很多人都从逻辑上觉得这样cpu 访问内存比较快, 是的这就是我们的答案,但是为什么cpu这样就呢?逻辑上解释不同,我们就从底层来看看cpu对内存的访问。
首先内存是线性的 (虽然画的不好但是轮廓还在)这个大家都知道 没什么神奇之处,但是聪明的cpu能让它编程从逻辑意思上讲的神奇的东西,现在大多数cpu对内存的寻址采用的是字节寻址,也就是一个地址线连一个字节(Byte=8bit),如上图我们看到的,这个图也就解释了cpu内部寄存器+1 指向的位置就是下一个字节,而不是下一个bit或者一个字,(其实这个也是一个技术,不然只能读一个bit就更慢了,让8条数据线(cpu总线上有许多条databus数据线 )连一个字节,这样一次就能读一个字节了)然后呢,显然这样每次读数的时候很不爽啦,每次只读一个字节,也要读到死啊,cpu自然不想被慢死,所以就采用了另一个技术,叫作给内存分体,这个分体技术不想一个字节8个位这样有明确要求的,不同位数的cpu分体的多少不一样,怎么理解这个分体技术呢,我们先从逻辑上理解一下,就想我们住的宿舍楼,每个字节就像一个宿舍,导员要想来查宿舍把每个学生抓起来,就要从服务台那里拿到钥匙和8条绳子,拿到这把钥匙就能访问到我们这个宿舍里面的8个人了,每个人相当于内存里一位,用一条绳子拴住,8个人就是一个字节共享这么一个地址(感觉说成监狱好一点);那么分体是什么呢,导员想了,哎呀我想访问一楼的学生,总不能让我每次抓8个出来再进去抓8个吧,于是就拿了更多的绳子更多的钥匙,把一群人一次性的抓走了;嗯这一群人就是一个体;
cpu也是这样子,这样一次访问就可以访问多个数据了,比如32位cpu一次总是能够找到四个字节(一定是四个,4个字节就是32bit),(分体对于32位cpu就是把32个bit分成4个体,每个体管一个字节)但是又有问题了,有些字节是不用访问的啊,比如说一个char 你总不能一下子给我读四个字节吧,是的32位cpu有32条数据线 每8条指向一个字节 所以可以指向四个字节 可以通过控制电路,让要读的那个字节可以导通,其它线路不通,这样虽然32条数据线都有连接,只有一个字节能够读到数据,嗯也就是说32位cpu对内存的访问是分了4个体,(这四个体构成一个访问单位)就像10个宿舍构成一层楼,cpu可以访问这四个体中的一个(char)两个(short)三个(3个char不管是否连着)或四个(int);嗯这是一次读取的,而对于double这种就需要两次了,嗯 所以问题就来了,哎呀我的double读的时间是你int的两倍,不能忍啊,于是就出现了奔腾时代的64位,现在的个人cpu大多数是64位,我们就只讨论这些主流的cpu ,是的 64位分8个体 所以double也只用一次就读到了,好快哒~~
这样我们就用上述的原理来解释一下c语言里的结论,来佐证我们的原理是正确的有用的;
我们来解释一下百度百科里面的言论:(内存对齐此条下面有这么一段话)

Win32平台下的微软C编译器(cl.exefor 80×86)的对齐策略: 1)结构体变量的首地址是其最长基本类型成员的整数倍; 备注:编译器在给结构体开辟空间时,首先找到结构体中最宽的基本数据类型,然后寻找内存地址能是该基本数据类型的整倍的位置,作为结构体的首地址。将这个最宽的基本数据类型的大小作为上面介绍的对齐模数。 2)结构体每个成员相对于结构体首地址的偏移量(offset)都是成员大小的整数倍,如有需要编译器会在成员之间加上填充字节(internal adding); 备注:为结构体的一个成员开辟空间之前,编译器首先检查预开辟空间的首地址相对于结构体首地址的偏移是否是本成员的整数倍,若是,则存放本成员,反之,则在本成员和上一个成员之间填充一定的字节,以达到整数倍的要求,也就是将预开辟空间的首地址后移几个字节。 3)结构体的总大小为结构体最宽基本类型成员大小的整数倍,如有需要,编译器会在最末一个成员之后加上填充字节(trailing padding)。 备注:结构体总大小是包括填充字节,最后一个成员满足上面两条以外,还必须满足第三条,否则就必须在最后填充几个字节以达到本条要求。 4) 结构体内类型相同的连续元素将在连续的空间内,和数组一样。 5) 如果结构体内存在长度大于处理器位数的元素,那么就以处理器的倍数为对齐单位;否则,如果结构体内的元素的长度都小于处理器的倍数的时候,便以结构体里面最长的数据元素为对齐单位。
1)结构体变量的首地址是其最长基本类型成员的整数倍;这个条款要和2)结构体每个成员相对于结构体首地址的偏移量(offset)都是成员大小的整数倍,一起理解;
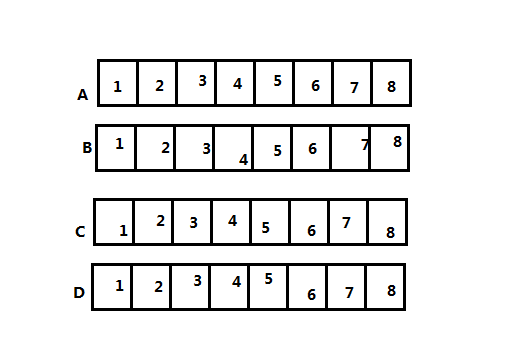
嗯 我们来看一个结构:
struct text{ char a; short b; int c; double d; };
分类讨论一下 :这个结构的最大元素是double 8个字节 自然 结构的首地址要在8的整数倍处(因为每行的开头就是8的倍数(行是从逻辑上言的方便理解 其实内存还是线性的)), 也就是说a要在1处 (A1 B1 C1或D1) 为什么首地址要是double的倍数呢,因为这样这个d就能够独占一行了并且达到整个结构体所占行数最小了(为什么要独占一行:一次性读完)(为什么结构要占行数少:读的次数少)
3)结构体的总大小为结构体最宽基本类型成员大小的整数倍:这个肯定是啊,a占一个字节,后面的b 与a之间填充一个字节 然后b占(这个位置是16位cpu的一个体) 所以c之前已经占了四个 c再占四个就是8个 然后d占8个 就是16个,这个结构可能偶然 可以再试试别的;
struct text{ double a; char b; };
16个字节; 为什么是16个不是9个 两次cpu读取都一样 不要怪cpu浪费 这只是它的生活态度~~~
4) 结构体内类型相同的连续元素将在连续的空间内,和数组一样。
这句话没什么说的;
5) 如果结构体内存在长度大于处理器位数的元素,那么就以处理器的倍数为对齐单位;否则,如果结构体内的元素的长度都小于处理器的倍数的时候,便以结构体里面最长的数据元素为对齐单位。
这个意思就是说 如果有个数据类型超过8个字节(long double) 那么就要cpu读两次才能读完了(逻辑上讲一行存不下) 所以就按照cpu的位数64bit 是8字节,进行对齐;
这样 这个话题就说完了,不过我这里说的分体技术 只适合 8位cpu(8086机)以后的(因为8bit就是1个字节 怎么分体) 比如16位机(80286)32位机(80386与80486)以及后来的奔腾机和酷睿机等等等等;