非等值折半查找
折半查找也就是二叉查找,其查找时间复杂度为O(logn),比顺序查找的效率高得多,唯一的要求就是待查表已经有序。
1、等值折半查找比较简单,算法如下:

def binarySearch(data,value): low = 0 high = len(data) - 1 while low <= high: middle = (high-low) / 2 + low#这个处理可以防止整数相加溢出 if data[middle] == value: return middle #找到,返回下标 if data[middle] < value: low = middle + 1 else: high = middle - 1 return -1#没找到返回-1
等值折半查找需要注意几个地方:
1)循环条件是low <= high,不是low < high,少了=符号,会造成有些实际在data中存在的value找不到而返回-1。如下图在表中查找4

查找过程如下:

经过两次查找后,low==high 等于1,于是跳出循环,而返回-1,事实上应该返回1,因为data[1]==4
2)low = middle + 1,而不是low = middle,如果写成low = middle会造成死循环。作为示例,我们在上面的data表中查找8,
查找过程如下:

可以看到从第4次查找后,就陷入了死循环,low始终等于4。
3)high = middle - 1,这里跟2)类似,写成high = middle一样会导致死循环,你可以试着在data表中查找3看看。
4)middle = (high-low) / 2 + low,为什么不直接写成middle = (high + low) / 2,试想一下,如果high和low都是int类型,high=30000,low=20000,high+low=50000已经超出int类型的范围,你再除以2,得到的middle已经不是你想要的数了,而middle = (high-low) / 2 + low可以很好的处理这个潜在 溢出错误。
2、非等值折半查找
很多时候我们需要在顺序表中进行范围查找,如在data中找小于某个值的数,data[index]<value,这与等值折半查找不同,在非等值查找时,即使在有序表data中没有找到值value仍然可能返回一个下标,而不是-1,如在前面的data中查找<4.5,我们应该让折半查找返回1,因为所有i <= 1 满足data[i] < 4.5,尽管4.5不在data中。
事实上非等值折半查找只需要在等值折半查找上添加几个判断条件,便可以实现,以下是python算法:
1 #折半范围查找 2 #若查找成功,返回最大的下标,满足data[i]<value或data[i]<=value 3 #若不存在指定的范围,则返回-1 4 def binarySearch(data,compare,value): 5 length = len(data) 6 low = 0 7 high = length - 1 8 while low <= high:#等值折半查找value 9 middle = (high-low) / 2 + low 10 if data[middle] == value: 11 break#找到value,跳出循环 12 if data[middle] < value: 13 low = middle + 1 14 else: 15 high = middle - 1 16 if low <= high:#value在data中 17 if compare == '<=' or compare == '>=' or compare == '=':#包含‘=’的比较,直接返回值value的下标 18 return middle 19 elif compare == '<':#'<'需要返回前面一个下标,有可能为-1 20 return middle - 1 21 else: 22 #(compare == '>') '>'需要返回后面一个下标 23 if middle == length -1:#middle等于有序表长度时,表示不存在data[i]>value,返回-1 24 return -1 25 else: 26 return middle + 1#返回后面一个下标 27 else:#value不在data中,此时high = low - 1,如果查找成功,value 在(high,low)的开区间中 28 if compare == '=': 29 return -1#等值查找,返回-1,查找失败 30 elif compare == '<' or compare == '<=':#返回区间左边端点,有可能返回-1 31 return high 32 else: 33 #compare == '>' or compare == '>=' 34 if low >= length:#不存在区间,返回-1 35 return -1 36 else: 37 return low#返回区间右端点
上面的算法实现了一个通用的不等值折半查找,首先进行等值折半查找找到value的位置或者区间,如在上面的表中查找<4.5,等值折半查找的区间为(high,low)= (1,2),所有找到的index为1,即返回值为1。
由于value是否在data中影响"<=",">="和"="的查找结果,所有分情况处理。
调用:
1 data = [5,6,7,8,9,10,11,12,13,14,15,16] 2 print binarySearch(data,'>',11) 3 print binarySearch(data,'<=',5)
Cmdlet处理生命周期
这一次介绍一下Cmdlet处理过程的生命周期
总共分为六个部分
下图展示Windows PowerShell怎样处理一个管道请求指令。
这个流程包括:
- 指令参数(parameters)初始绑定阶段
- 指令处理开始
- 管道参数(parameters)二次绑定阶段
- 记录处理
- 指令处理结束
第一次绑定期间,Windows PowerShell运行时使用它的管道处理器绑定参数(Arguments)到参数(parameters)。参数(arguments)可能被用户以交互方式指定并作为命令行输入,也可能是被宿主程序以编程方式指定。管道处理器触发指令处理器,指令处理器为每一个受影响指令执行初始绑定。
对于每一个指令,按照下面顺序执行第一次绑定阶段:
a. 绑定名称参数
b. 绑定位置参数
c. 绑定公共参数
d. 绑定参数支持调用ShouldProcess方法
c. 绑定名称动态参数
绑定位置动态参数
绑定期间,管道处理器是使用参数的元数据、扩展类型系统(ETS)的类型定义和强制类型转换的参数值。强制类型转换过程中一个特定值,这个特定值是.NET Framework类型变成另外一个类型的参数值。
假如管道处理器完成处理过程,但发现管道收命令行输入任何未绑定的参数指令,此时管道处理就会失败,处理过程中断。如果这些指令的所有参数绑定成功,管道处理器开始记录处理。
所有命令行输入的参数都被绑定了他们的值,这个时候管道处理器开始指令处理。这样,处理器开始调用第一个指令——BeginProcessing方法,并把这个指令发送给管道。要是只是使用这个方法的默认实现,他什么事情也不会做。然而,如果重写这个方法,就会执行该方法的多有处理。
当管道处理器从一个方法返回,然后调用在管道中区域的指令方法,知道所有的方法都被调用。如果一个指令在管道出现多次,每一次都被作为一个单独的方法处理。
所有的指令被处理后,管道处理器现在进入外一个绑定阶段。在该操作中,处理器绑定值到每一个通过管道输入的指令上。
对于接受管道输入的每一个指令,处理器绑定值到这些参数上要按照下面的顺序:
a. 绑定指令定义管道参数
b. 绑定动态管道参数
如果管道处理器发现任何接受的管道输入指令没有绑定参数,管道处理失败,处理中断。如果所有参数成功绑定,管道处理器开始处理记录。
所有接受管道输入的参数都被绑定了值之后,管道处理器开始处理记录。管道处理器在管道中开始第一个指令。
以下是管道处理器记录处理的步骤:
a. 确定是否所有强制参数值都是可用,如果存在不可用的,失败。
b. 确定单一参数集被定义,如果不是,失败。
c. 在接下来的指令中调用ProcessRecord方法。要是只是使用这个方法的默认实现,他什么事情也不会做。如果重写了这个方法,将会按照新方法处理。
d. 当管道处理器从ProcessRecord方法返回时,设置所有管道参数的初始值。
e .检查更多管道对象。
f. 如果存在更多地对象,再次绑定管道参数。
g. 重复上面步骤,知道所有管道中的的指令记录都被处理。
管道中所有指令的记录已经被处理,最后结束指令处理。
所有的记录已经被处理,管道处理器告诉后续指令处理器在相关的指令中调用EndProcessing方法。要是只是使用这个方法的默认实现,他什么事情也不会做。如果重写了这个方法,将会按照新方法处理。
本文主要解决一个问题,如何实现二叉树的前中后序遍历,有两个要求:
1. O(1)空间复杂度,即只能使用常数空间;
2. 二叉树的形状不能被破坏(中间过程允许改变其形状)。
通常,实现二叉树的前序(preorder)、中序(inorder)、后序(postorder)遍历有两个常用的方法:一是递归(recursive),二是使用栈实现的迭代版本(stack+iterative)。这两种方法都是O(n)的空间复杂度(递归本身占用stack空间或者用户自定义的stack),所以不满足要求。(用这两种方法实现的中序遍历实现可以参考这里。)
Morris Traversal方法可以做到这两点,与前两种方法的不同在于该方法只需要O(1)空间,而且同样可以在O(n)时间内完成。
要使用O(1)空间进行遍历,最大的难点在于,遍历到子节点的时候怎样重新返回到父节点(假设节点中没有指向父节点的p指针),由于不能用栈作为辅助空间。为了解决这个问题,Morris方法用到了线索二叉树(threaded binary tree)的概念。在Morris方法中不需要为每个节点额外分配指针指向其前驱(predecessor)和后继节点(successor),只需要利用叶子节点中的左右空指针指向某种顺序遍历下的前驱节点或后继节点就可以了。
Morris只提供了中序遍历的方法,在中序遍历的基础上稍加修改可以实现前序,而后续就要再费点心思了。所以先从中序开始介绍。
首先定义在这篇文章中使用的二叉树节点结构,即由val,left和right组成:
1 struct TreeNode { 2 int val; 3 TreeNode *left; 4 TreeNode *right; 5 TreeNode(int x) : val(x), left(NULL), right(NULL) {} 6 };
一、中序遍历
步骤:
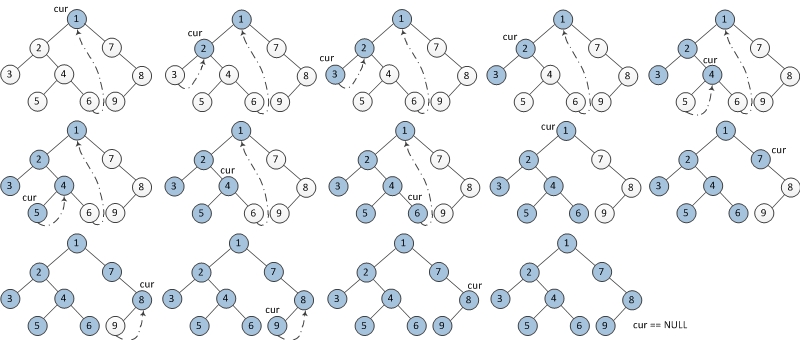
1. 如果当前节点的左孩子为空,则输出当前节点并将其右孩子作为当前节点。
2. 如果当前节点的左孩子不为空,在当前节点的左子树中找到当前节点在中序遍历下的前驱节点。
a) 如果前驱节点的右孩子为空,将它的右孩子设置为当前节点。当前节点更新为当前节点的左孩子。
b) 如果前驱节点的右孩子为当前节点,将它的右孩子重新设为空(恢复树的形状)。输出当前节点。当前节点更新为当前节点的右孩子。
3. 重复以上1、2直到当前节点为空。
图示:
下图为每一步迭代的结果(从左至右,从上到下),cur代表当前节点,深色节点表示该节点已输出。

代码:
1 void inorderMorrisTraversal(TreeNode *root) { 2 TreeNode *cur = root, *prev = NULL; 3 while (cur != NULL) 4 { 5 if (cur->left == NULL) // 1. 6 { 7 printf("%d ", cur->val); 8 cur = cur->right; 9 } 10 else 11 { 12 // find predecessor 13 prev = cur->left; 14 while (prev->right != NULL && prev->right != cur) 15 prev = prev->right; 16 17 if (prev->right == NULL) // 2.a) 18 { 19 prev->right = cur; 20 cur = cur->left; 21 } 22 else // 2.b) 23 { 24 prev->right = NULL; 25 printf("%d ", cur->val); 26 cur = cur->right; 27 } 28 } 29 } 30 }
复杂度分析:
空间复杂度:O(1),因为只用了两个辅助指针。
时间复杂度:O(n)。证明时间复杂度为O(n),最大的疑惑在于寻找中序遍历下二叉树中所有节点的前驱节点的时间复杂度是多少,即以下两行代码:
1 while (prev->right != NULL && prev->right != cur) 2 prev = prev->right;
直觉上,认为它的复杂度是O(nlgn),因为找单个节点的前驱节点与树的高度有关。但事实上,寻找所有节点的前驱节点只需要O(n)时间。n个节点的二叉树中一共有n-1条边,整个过程中每条边最多只走2次,一次是为了定位到某个节点,另一次是为了寻找上面某个节点的前驱节点,如下图所示,其中红色是为了定位到某个节点,黑色线是为了找到前驱节点。所以复杂度为O(n)。
二、前序遍历
前序遍历与中序遍历相似,代码上只有一行不同,不同就在于输出的顺序。
步骤:
1. 如果当前节点的左孩子为空,则输出当前节点并将其右孩子作为当前节点。
2. 如果当前节点的左孩子不为空,在当前节点的左子树中找到当前节点在中序遍历下的前驱节点。
a) 如果前驱节点的右孩子为空,将它的右孩子设置为当前节点。输出当前节点(在这里输出,这是与中序遍历唯一一点不同)。当前节点更新为当前节点的左孩子。
b) 如果前驱节点的右孩子为当前节点,将它的右孩子重新设为空。当前节点更新为当前节点的右孩子。
3. 重复以上1、2直到当前节点为空。
图示:
代码:
1 void preorderMorrisTraversal(TreeNode *root) { 2 TreeNode *cur = root, *prev = NULL; 3 while (cur != NULL) 4 { 5 if (cur->left == NULL) 6 { 7 printf("%d ", cur->val); 8 cur = cur->right; 9 } 10 else 11 { 12 prev = cur->left; 13 while (prev->right != NULL && prev->right != cur) 14 prev = prev->right; 15 16 if (prev->right == NULL) 17 { 18 printf("%d ", cur->val); // the only difference with inorder-traversal 19 prev->right = cur; 20 cur = cur->left; 21 } 22 else 23 { 24 prev->right = NULL; 25 cur = cur->right; 26 } 27 } 28 } 29 }
复杂度分析:
时间复杂度与空间复杂度都与中序遍历时的情况相同。
三、后序遍历
后续遍历稍显复杂,需要建立一个临时节点dump,令其左孩子是root。并且还需要一个子过程,就是倒序输出某两个节点之间路径上的各个节点。
步骤:
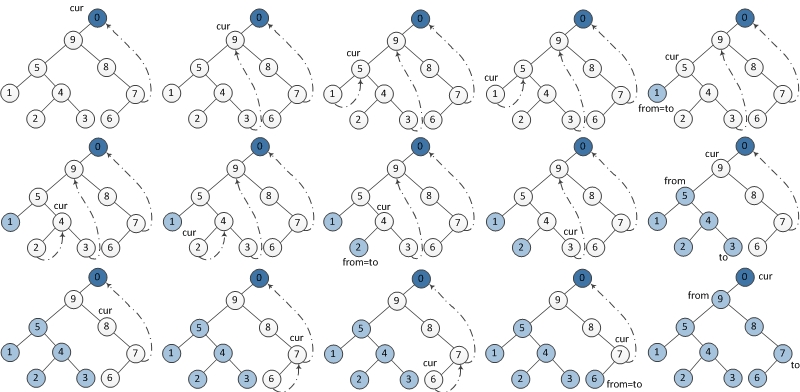
当前节点设置为临时节点dump。
1. 如果当前节点的左孩子为空,则将其右孩子作为当前节点。
2. 如果当前节点的左孩子不为空,在当前节点的左子树中找到当前节点在中序遍历下的前驱节点。
a) 如果前驱节点的右孩子为空,将它的右孩子设置为当前节点。当前节点更新为当前节点的左孩子。
b) 如果前驱节点的右孩子为当前节点,将它的右孩子重新设为空。倒序输出从当前节点的左孩子到该前驱节点这条路径上的所有节点。当前节点更新为当前节点的右孩子。
3. 重复以上1、2直到当前节点为空。
图示:
代码:
1 void reverse(TreeNode *from, TreeNode *to) // reverse the tree nodes 'from' -> 'to'. 2 { 3 if (from == to) 4 return; 5 TreeNode *x = from, *y = from->right, *z; 6 while (true) 7 { 8 z = y->right; 9 y->right = x; 10 x = y; 11 y = z; 12 if (x == to) 13 break; 14 } 15 } 16 17 void printReverse(TreeNode* from, TreeNode *to) // print the reversed tree nodes 'from' -> 'to'. 18 { 19 reverse(from, to); 20 21 TreeNode *p = to; 22 while (true) 23 { 24 printf("%d ", p->val); 25 if (p == from) 26 break; 27 p = p->right; 28 } 29 30 reverse(to, from); 31 } 32 33 void postorderMorrisTraversal(TreeNode *root) { 34 TreeNode dump(1); 35 dump.left = root; 36 TreeNode *cur = &dump, *prev = NULL; 37 while (cur) 38 { 39 if (cur->left == NULL) 40 { 41 cur = cur->right; 42 } 43 else 44 { 45 prev = cur->left; 46 while (prev->right != NULL && prev->right != cur) 47 prev = prev->right; 48 49 if (prev->right == NULL) 50 { 51 prev->right = cur; 52 cur = cur->left; 53 } 54 else 55 { 56 printReverse(cur->left, prev); // call print 57 prev->right = NULL; 58 cur = cur->right; 59 } 60 } 61 } 62 }
复杂度分析:
空间复杂度同样是O(1);时间复杂度也是O(n),倒序输出过程只不过是加大了常数系数。
注:
以上所有的代码以及测试代码可以在我的Github里获取。
参考:
http://www.geeksforgeeks.org/inorder-tree-traversal-without-recursion-and-without-stack/
http://www.geeksforgeeks.org/morris-traversal-for-preorder/
http://stackoverflow.com/questions/6478063/how-is-the-complexity-of-morris-traversal-on
http://blog.csdn.net/wdq347/article/details/8853371
Data Structures and Algorithms in C++ by Adam Drozdek
---------------
以前我只知道递归和栈+迭代实现二叉树遍历的方法,昨天才了解到有使用O(1)空间复杂度的方法。以上都是我参考了网上的资料加上个人的理解来总结,如果有什么不对的地方非常欢迎大家的指正。
原创文章,欢迎转载,转载请注明出处:http://www.cnblogs.com/AnnieKim/archive/2013/06/15/MorrisTraversal.html。