算法就是设计
插入排序的套路
坚持我之前的说法,学习算法设计关键是要学习算法套路。一些经典排序算法,很好的体现了一些重要的套路,值得想一想。本文介绍插入排序的算法套路,即重用与增量有序的思想。

先要注意,排序的结果一般都是升序的,也就是从小到大(与上图相反)。
插入排序的算法很好理解,形式上,跟排扑克牌一样的操作:一开始,手是空的,然后拿一张牌开始插入排序,每一张新拿的牌都跟手中的牌进行比较,可以从小到大的比较(遇到大的就插在前面),也可以从大到小的比较(遇到小的就插在后面)。
这个排扑克牌的操作,有两个特点,一个是对于每一张新牌都是一样的处理(重用),另一个是手中的牌始终是有序(增量有序)。类比于这两个特点,插入排序算法体现了两个重要的套路,就是重用跟增量有序。
重用,并不是插入排序算法特有的,很多算法都有这个表现,所以“重用”已经是一种基本的算法套路。
什么是重用呢?
举个例子:
如何把大象装进一个关着门的冰箱?
先把冰箱打开门,再把大象装进去,最后关上门。这是解决办法,而且,把这个视为标准作业。
那么:
如何把大象装进一个开着门的冰箱?
解决办法是,先把冰箱关上门,然后执行上面的标准作业。
那么:
如何把十只大象装进冰箱呢?
解决办法是,找十台冰箱,先把门关上,然后执行标准作业。
执行标准作业,就是在重用。
那插入排序算法中的重用是什么表现呢?就是每一个元素,都跟之前的元素进行相同的比较定位与插入的操作,也就是说,如果把第i个元素的操作想清楚了(比如我把第3个元素怎么操作想清楚就好),那就所有元素的操作都想清楚了。
因为可以重用,所以思考的复杂度大幅下降。重用也是抽象的重要手段,有助于提取主干。
需要注意,边界并不是算法设计重点考虑的内容,如果不重要甚至可以忽略边界的处理。但是,写程序就要考虑清楚边界。写程序跟设计算法,是两个不同的话题,这个我之前已经介绍过了。
总的来说,插入排序算法中的第i个元素的排序,是一个标准作业,可以反复重用。
小白:如果地上有一支枪,你的敌人过来了,你怎么杀死敌人?
小程:捡起枪,瞄准射击。
小白:如果你手上拿着枪,你的敌人过来了,你怎么杀死敌人?
小程:先把枪扔到地上,然后启用之前的操作。
以上讲的是“重用”的套路,接着讲“增量有序”的套路。
“增量有序”的表现,有点像清洗的工作,比如每一棵菜都要洗干净再放到锅里、每一个新入职的员工都要接受公司的价值观后才能开展工作,这样保证锅里的菜都是干净的、一起工作的人都是有相同价值观的。
简单来说,增量有序,就是保证正在扩展的区域一定是有序的。
插入排序算法中的“增量有序”,可以看下面这个图来表现: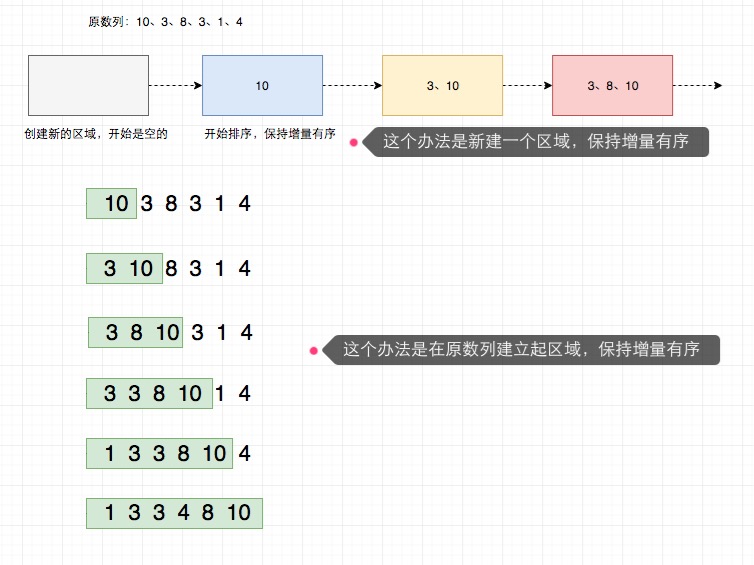
这个扩展的区域可以是新的数组,也可以在原数组中进行。
以上是增量有序的设计套路,至此,“重用”与“增量有序”这两个重要的算法套路就介绍完毕了。
接下来,是小的方面,就是这个标准作业,即其中一个元素是怎么定位插入的问题。在增量有序的情况下,任何一个元素,如何找到合适的位置,一般有三个办法。
办法一是从高往低地跟有序队列的元素作比较(也就是从右往左地比较),遇到一个更小的值,就插在其后面。
办法二是从低往高地跟有序队列的元素作比较(也就是从左往右地比较),遇到一个更大的值,就插在其前面。
办法三是比较的时候,反复二分定位比较,最终定下位置的办法,这个办法可以减小比较的次数,但程序实现的复杂度高一些。
这三个办法中,一般来说,办法一是最好的选择,一来可以使这个标准作业的思路简单而清晰,二来程序实现也相对便利。
至此,插入排序的算法套路就介绍完毕了,简单来说,插入排序,就是,当前已经处理的数组总是有序的,然后就重用插入一个元素的操作,增加一个元素到已处理的数组中,至到所有元素都处理过。而对于插入一个元素,可以从小到大比较(遇大就进前面),也可以从大到小比较(遇小就进后面),也可以二分定位(这个复杂一点,不利于实现),整个算法就设计完了,并不复杂。
以下的内容,是程序实现方面,这里做一个简单的演示,你如果想训练程序的编写能力的话,应该自己动手实现。
// 多用一个临时数组
void insertsort(int* arr, int size) {
int* tmparr=(int*)malloc(sizeof(int) * size);
memcpy(tmparr, arr, size*sizeof(int));
int count = 0;
for (int i = 0; i < size; i ++) {
int j=0;
for (j = 0; j < count; j ++) {
if (arr[i]<tmparr[j]) {
memcpy(tmparr+j+1, tmparr+j, (size-j-1)*sizeof(int));
tmparr[j]=arr[i];
break;
}
}
if (j==count) {
tmparr[j]=arr[i];
}
count ++;
}
memcpy(arr, tmparr, size*sizeof(int));
free(tmparr);
}
// 就地insert
void insertsort2(int* arr, int size) {
for (int i = 0; i < size; i ++) {
for (int j = 0; j < i; j ++) {
if (arr[i] < arr[j]) {
int t = arr[i];
memcpy(arr+j+1, arr+j, (i-j)*sizeof(int));
arr[j]=t;
break;
}
}
}
}
// 就地insert,另一个思路(办法一):从右向左比较,边比较边移位,遇到更小的值为止
void insertsort3(int* arr, int size) {
for (int i = 1; i < size; i ++) {
int t = arr[i];
int j = 0;
for (j = i-1; j >= 0 ; j --) {
if (arr[j] < t) {
arr[j+1] = t;
break;
}
else {
arr[j+1] = arr[j];
}
}
if (j<0) {
arr[0] = t;
}
}
}
int main(int argc, char *argv[])
{
int arr[] = {5, 3, 6, 1, 2};
int size = sizeof arr/sizeof *arr;
insertsort3(arr, size);
for (int i = 0; i < size; i ++) {
printf("%d, ", arr[i]);
}
return 0;
}写程序跟设计算法不一样,算法注重套路、主干,并且抽象(忽略不重要的细节),而写程序就要考虑一些细节(比如边界、异常之类)而且还有数据类型、模块化之类的考虑。
写程序不是本文的重点。
总结一下,本文介绍了插入排序体现的算法套路,即重用与增量有序的设计思想,另外也介绍了任一元素如何完成插入排序这一标准作业,最后演示了代码实现。
用一只海龟来引入“递归”,是有一些滑稽,但也没有关系。可能你更喜欢的是海龟而不是无穷的递归调用,那递归长什么样呢?
(一)递归的样子
各种表现,比如这些样子:
-
和尚讲故事
从前有座山,山里有座庙,庙里有个老和尚,老和尚给小和尚讲故事,讲的是从前有座山。。。。
-
沙滩是怎么形成的
A:沙堆是怎么形成的?
B:沙堆是一个沙堆加上一粒沙。
A:那这一个沙堆是怎么形成的?
B:这一个沙堆是一个沙堆加上一粒沙。
A:... -
吓得我

-
递归函数
f(x) = g(f(x-1))
-
巧妙的衣服

-
谣言成真,那还算造谣吗?
上海一男子因造谣称自己因造谣而被拘留15日而被拘留15日。
-
洋葱的构成
一个洋葱就是带着一层洋葱皮的洋葱。
-
转发通知
这些例子可以看到递归的影子,可以感受到递归的一个特点就是“嵌套”,一层套一层,层层新。正如我说的,一定要用自己的话突出重点地表达你的理解,不要完整或完善,那么,递归是什么?
(二)递归是什么?
递归就是调用自己,调用自己的就是递归,就这么简单。“自己”是什么?“自己”是一个递归结构或算法。
为什么能够调用自己?
之所以能调用自己,是因为子问题也能用原问题的解决办法。递归的设计,就是把问题分解成更小的问题,而且更小的问题也能用原问题的解决办法。在问题规模足够小的时候,把它解决掉,再层层返回,层层组合。
如果非要说一个伟大的思想来突显递归的nb,那就是以退为进,在遇到问题很复杂你解决不了的情况下,退一步,如果退一步还解决不了,就再退一步--没有什么问题是退一步解决不了的,如果有,那就退两步。在退到足够简单的情况下,把它解决,再回归。这个是不是很厉害?
当然你也可以用数学归纳法来考证递归的伟大,但我觉得大可不必,更多情况下,递归只是解决问题的小工具。
那么,这个小工具怎么用起来?走你!
(三)使用递归
使用递归时,有两个要点可以考虑,一是如何调用自己,包括自己返回后怎么处理,二是在什么时候结束递归。
说多无谓,实战出感悟。不考虑性能,看几个问题的递归解决吧。
问题1:输入数字n,打印出1到n的所有整数。
主体:要打印1到n,那先打印1到n-1,再打印一个n就可以了。这个就是主体,只考虑n跟n-1。
结束:在n为1时打印1,并结束递归。
代码示例:
void pr(int n) {
if (n == 1) {
printf("1
");
return;
}
pr(n-1);
printf("%d
", n);
}效果: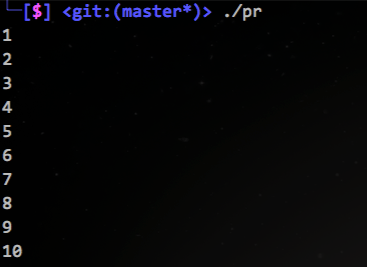
问题2:输出“我当然知道 我知道 我知道 我知道 ...我是个sb 这件事 这件事...这件事”,输入n来控制次数。
主体:把“我当然知道”放在递归函数外,因为它不符合同构的原则。先输出“我知道”,再递归到下一层即可。
结束:在递减到0时,结束递归。
收尾:在递归返回后,输出“这件事”。
代码示例:
#include <stdio.h>
void pr(int n) {
if (n == 0) {
printf("[我是sb]");
return;
}
printf("我知道[");
pr(n-1);
printf("这件事]");
}
int main(int argc, char *argv[])
{
printf("我当然知道{");
pr(10);
printf("}
");
return 0;
}效果:
问题3:求二叉树的高度(最长路径)。
主体:左子树与右子树的高度的最大值,加1就是当前树的高度。
结束:没有子树了。
代码示例:
int treeHeight(struct TreeNode* root) {
if (!root) return 0;
int left = treeHeight(root->left);
int right = treeHeight(root->right);
return MAX(left, right) + 1;
}问题4:求数组中的最大值与最小值。
演示代码:
#include <iostream>
using namespace std;
template<typename T>
void max_min( T a[], int low, int high, T & max, T & min)
{
if ( low == high ) // 只有一个元素不再划分
{
max = min = a[low];
return;
}
else if ( low == high -1 ) // 只有两上元素不再划分
{
if ( a[low] < a[high] )
{
max = a[high];
min = a[low];
}
else
{
max = a[low];
min = a[high];
}
return;
}
int mid = (low + high) / 2;
T max_another;
T min_another;
max_min( a, low, mid, max, min );
max_min( a, mid+1, high, max_another, min_another );
if ( max < max_another )
max = max_another;
if ( min > min_another )
min = min_another;
}
int _tmain(int argc, _TCHAR* argv[])
{
double a[5] = {23.23, 23.45, .3, -89.3, -2.1};
double max, min;
max_min<double>( a, 0, 4, max, min );
cout << "max: " << max << " min: " << min << endl;
return 1;
}
最后,再提一下递归的深度。
每次递归调用都意味着部分数值压入栈中(比如系统维护的下压栈),这是跟迭代的区别。在迭代中每次循环结束时所有局部变量都获得释放,而递归却会不断累计,所以使用递归算法必须考虑它的深度,考虑是否会造成栈溢出,与及对效率造成的影响。
另外,每一次递归调用,问题的规模都应该有所减少,并最终达到终止条件的要求,从而结束递归调用。
至此,递归的入门介绍完毕了。
总结一下,本文介绍了递归的表现、递归的理解与设计,最后举了几个例子并用递归的思路来实现。递归是一个重要的思考问题的思路,希望能帮到你。
又是小程讲道理的时间,如果根本就不对你的口味请直接离开。讲什么道理呢,就是对算法的理解,算法是什么,有什么用,怎么学习算法。
上一次讲了递归的简单入门,说递归是重要而实用的算法套路。那为什么递归是算法先?
(1)算法是什么?
算法就是设计好的计算流程。
首先,算法是经过设计的,是为了解决某个或某类问题的,是有考虑资源成本的,等等。那些不知道为何而做的,随遇而安的,不是算法。
然后,算法是计算流程。计算是一个抽象概念,形式上可以是数值运算,也可以是调配资源,也可以是攻城夺寨,等等。而流程,就是操作步骤。
再简单一点,突出重点,算法就是经过设计的东西。你要有设计,不是说想到哪做到哪,不是“自然而然”的行动,当然,如果你的直觉充满了设计,你是天生的设计师,那不能否认你的“边做边想”也是算法,只不过你没有提炼出来而已。

另一个问题,算法跟程序是什么关系?
有人曾说过:程序=数据结构+算法,所以要写好程序就要算法好。我并不同意这种说话,我认为程序跟算法没有必然的联系,我认为,程序=变量+流程,很多时候,写好程序只要理解业务跟需求,并且掌握编程工具,就可以做到,并不需要你有设计算法的能力。同样,算法设计好,也不一定能把程序写好,你可能根本就不懂编程工具,还写什么程序。
所以,设计是设计,写程序是写程序,没有必然关系的,你可以专做算法设计而不写代码。只不过,一般像我们这些一线开发,设计跟编程是同一个人,所以才有算法设计跟编程一起来的情况,像那些高级的,他们很可能只扔给你一个算法,由你来编程实现,这时两者就明显分开(设计者有可能不懂编程)。
既然算法就是事先设计,那这个设计有用吗?
(2)算法有没有用?
这个问题很好回答,从大局来说,从行业、技术的发展来说,算法一定是一个关键元素。
那对于个人呢,算法设计是不是有用?
你可能会觉得,只有跟我相关的算法才有用,比如,如果我整天都是写Android平台的activity,那我理解视频的压缩算法又能带来什么帮助呢?如果我的职责就是优化视频首帧的显示速度,那理解压缩算法就可能有帮助了。所以你可能会得出一个结论:只有跟我相关的算法才有用。
我觉得跟你相关的算法能直接帮助到你的,而跟你不相关的算法的理解也一样能帮助到你。正如之前所说,具体的事情本身往往不是关注点,关注点在于做这个事情的过程中强化什么。
所以,没有疑问,算法设计是有用的,退一万步来说,你对设计的思考能让你保持独立思考与坚持苦想的习惯。而且你会发现,现实工作环境中,懂算法的人更能通杀不同的平台(所以工资高呗),毕竟设计套路很多是相通的。
既然算法设计能帮到我们,甚至某些场合是必须的,那应该怎么去学习算法呢?毕竟那么多算法设计!
(3)怎么学习算法?
就像武侠小说中的太祖长拳、罗汉拳一样,算法是套路。你应该学习的是设计套路,至于怎么把多个套路组合,怎么分拆成散打,那是参悟的问题。
学习算法,主要还是学习经典的套路,比如分治思想、贪婪算法、回溯法,等等,而对于专门领域的算法,你可能要学得更加具体(这个过程足够强化你的苦想能力)。
不要学那些“抖机灵的算法”,有些“算法”只是编程技术的巧妙运用,并不是套路。包括很多算法题目,都没有引导大家去学习算法套路,而只是强调编程技巧。编程技巧有可能是重要的,但跟学习算法没有关系,应该摒弃这个干扰。
比如,这样一个题目:
逆转单向链表。
如果从“分治”与“复用”的套路出发,就会把问题简化为“如何把两个结点逆转”,两个结点逆转是容易实现的。当两个结点逆转后,问题再次变成了“如何把两个结点逆转”,只不过是指向往前推进了。
如果“抖机灵”,使用编程技巧,可以先把所有结点的地址保存到数组,然后循环数组,让a[i]->next = a[i-1],留意边界,即可。但是,编程技巧不是算法套路,不应该出现在算法设计上。
另外,专门领域的算法,比如视频压缩、搜索引擎等算法,也是套路,而且是实战性很强的套路。
总的来说,你应该学习经典的算法套路,并且忽略编程技巧类的干扰,毕竟在这里,我们学的是设计,而不是编程。

总结一下,又是讲道理,回答了“算法是什么”、“有没有用”、“怎么学习”这三个问题。算法就是设计,是我们的朋友,要跟经典的算法套路打交道。