1、Q-learning主要是Q表:
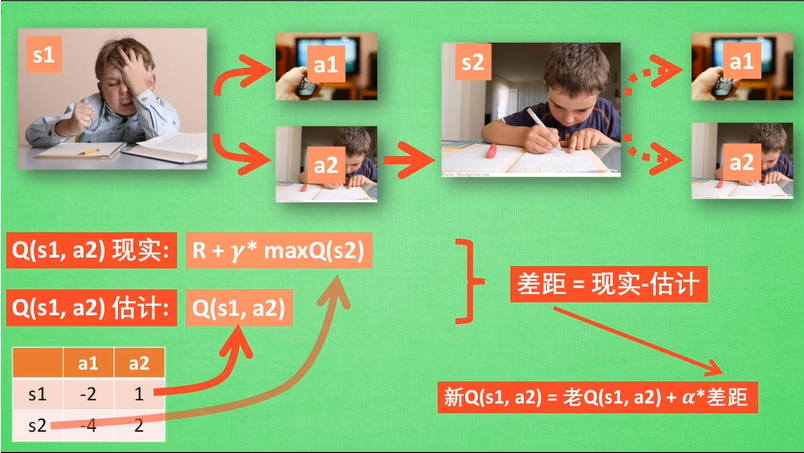
当前状态s1,接下来可以有两个动作选择,看电视a1和学习a2,对于agent人来说,可以根据reward来作出决策(Policy)。目的就是得到奖励最大。
Q-learning的目的就是学习特定state下、特定Action的价值。
Q-learning的方法是建立一个表,以state为行、action为列。比如:state有2个,action也有两个,所以Q-table就是2×2的一个表,对应总共4种可能得决策。
2、模型:
首先以 0 填充Q-table进行初始化,然后观察每一个决策带来的回馈,再更新Q-table。更新的依据是Bellman等式:
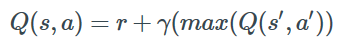

每一次行动,都会更新Q-table。
初始Q-table如下(行:state,列:action):
| a1 | a2 | |
| s1 | 0 | 0 |
| s2 | 0 | 0 |
相应的Q-table如下:
| a1 | a2 | |
| s1 | -2 | 1 |
| s2 | -4 | 2 |
但是这个Q-table是我们希望得出或逼近的,在开始时,Agent所知的Q-table还是一个全0的矩阵。
3、算法:



算法中的 α 是指学习率,其控制前一个 Q 值和新提出的 Q 值之间被考虑到的差异程度。尤其是,当 α=1 时,两个 Q[s,a] 互相抵消,结果刚好和贝尔曼方程一样。
我们用来更新 Q[s,a] 的只是一个近似,而且在早期阶段的学习中它完全可能是错误的。但是随着每一次迭代,该近似会越来越准确;而且我们还发现如果我们执行这种更新足够长时间,那么 Q 函数就将收敛并能代表真实的 Q 值。
4、代码:
import numpy as np GAMMA = 0.8 Q = np.zeros((6,6)) R=np.asarray([[-1,-1,-1,-1,0,-1], [-1,-1,-1,0,-1,100], [-1,-1,-1,0,-1,-1], [-1,0, 0, -1,0,-1], [0,-1,-1,0,-1,100], [-1,0,-1,-1,0,100]]) def getMaxQ(state): return max(Q[state, :]) def QLearning(state): curAction = None for action in range(6): if(R[state][action] == -1): Q[state, action]=0 else: curAction = action Q[state,action]=R[state][action]+GAMMA * getMaxQ(curAction) count=0 while count<1000: for i in range(6): QLearning(i) count+=1 print(Q/5)