1、摘要:
采用attention和NCF结合解决群组偏好融合的问题。
贡献:
- 第一个使用神经网络学习融合策略的组推荐。
- 进一步整合用户-项目交互改进组推荐,减轻冷启动问题。
2、方法:
模型AGREE模型包括:1)组特征学习:成员融合+群组偏好;2)与NCF的交互学习
2.1 符号:
n个用户:U = { u1,……,un }
s个群组:G = { g1,……,gs }
m个项目:V = { v1,……,vm }
群组和项目的交互:Y
用户和项目交互:R
输入:U、G、V、Y、R
输出:两个个性化排序函数
2.2 注意力群组表征学习:
(1)动机:传统的群组偏好融合策略(AVG、最小痛苦、最大满意度等)是数据独立的,缺乏动态调整组成员权重的灵活性。
采用注意力来学习融合策略,它的基本思想是将一组表示压缩层一个加权和的表示。权重学习来自于神经网络。
具体地说:平均数等于给所有成员赋予一个统一的权重,最小痛苦和最大满意对应于只给部分成员分配权重。注意力的权重是给所有成员都分配权重。
(2)方法:
本文的目标是获得每个组的嵌入向量,以估计其对一个项目的偏好。
组的嵌入向量 = 用户特征融合 + 组偏好特征

用户特征融合:
对群组成员用户特征嵌入进行加权求和,其中系数α(j,t )表示成员用户ut 在决定群组对项 vj 的选择时的影响权重参数。
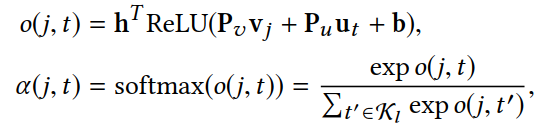
其中,Pv 和 Pu 是attention网络的权重矩阵,用来将项目特征嵌入和用户特征嵌入转化成隐藏层。b为隐藏层的偏差。
使用relu函数作为隐藏层的激活函数。
下图为用户嵌入特征融合策略。利用attention,允许每个成员用户在组决策中作出贡献,其中用户贡献取决于其历史偏好和目标性的属性,这些属性是从组--项交互和用户--项交互的历史数据中学到的。
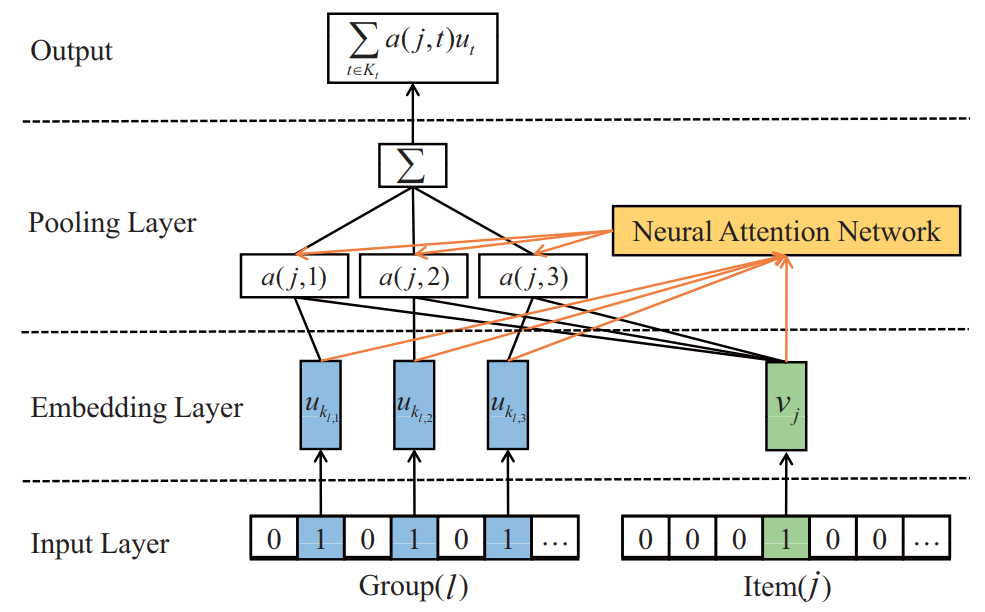
组偏好嵌入:
目的是考虑一个群体的一般偏好,在某些情况下,当用户组成一个组时,他们可能追求一个与每个用户偏好不同的目标。
eg:一个三口之家,孩子喜欢卡通片,父母喜欢浪漫片,但他们去看电影时,最后选择的电影可能是一部教育片。
将组偏好嵌入和用户嵌入融合进行组合,采用了一个简单的加法操作。
2.3 基于NCF的交互学习
选择NCF的原因:
NCF是用于项目推荐的多层神经网络框架。其思想是将用户嵌入和项目嵌入 输入专用的神经网络,以从数据中学习交互功能。由于神经网络具有较强的数据拟合能力,因此NCF框架比传统的MF模型具有更强的泛化能力,而传统的MF模型仅仅才要看过数据无关的内积函数作为交互函数。因此,选择NCF框架对嵌入(表示用户、项目和组)和交互功能(预测用户--项目 和 组-- 项目交互)执行端对端学习。
NCF过程:
目标:同时为组和用户进行推荐,故设计了将用户--项目和组--项目交互功能一起学习。
给定用户项对(ui,vj)或组项对(l,vj),表示层首先返回每个给定实体的嵌入向量(详细信息参见2.2节)。然后进入池化层和隐藏层,最后获得预测分数。
池化层:假设输入是组--项目对(l,vj),池化层首先在他们的嵌入(即gl(j)和vj) )进行点积【每个元素互乘】,然后将它们和原始嵌入连接成矩阵:

理由有两个:1)点积包含MF,使用乘法来体现每个嵌入维度的交互作用,而且点积在神经网络低层特征交互中是高效的。2)点积可能丢失一些信息,所以将原始信息保留。
共享隐藏层:全连接层,这样可以捕获用户、组和项目之间的非线性和高阶相关性。
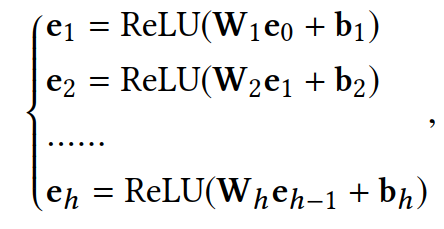
e为上层隐藏层神经元输出。

其中,w表示预测层的权重;rij和ylj分别表示对用户项对(ui,vj)和组项对(l,vj)的预测。
有目的地设计了两个任务共享同一隐含层的预测。这是因为组嵌入是从用户嵌入聚合而来的,这使得它们本质上处于相同的语义空间中。此外,利用用户项目交互数据可以增强组项目交互功能的训练,反之亦然,这有利于两个任务相互加强。

2.4 模型优化:
(1)目标函数:成对排序:


其中,O表示训练集,其中每个实例是三元组(i,j,s),这意味着用户ui已经与项目vj交互,但是没有与项目vs交互(即,vs是从未观察到的ui交互中采样的负实例);ri j s=ri j_ri s表示margi观察到的交互(UI,VJ)和未观察到的交互(UI,VS)的预测的N。
由于我们主要关注隐式反馈,其中每个观察到的交互作用都有一个值1,而未观察到的交互作用有一个值0,因此我们有rijs=rij_ris=1。
我们知道推荐中另一种流行的成对学习方法是贝叶斯个性化排序(BPR)[8,29]。值得指出的是,与BPR相比,上述基于回归的成对损失的优点在于,它消除了对隐藏层(即{Wh}和w)中的权重调整L2正则化的需要.
(2)学习细节:
- 小批量训练
- 预训练
- dropout
3、实验:
(1)数据集:
①马蜂窝。马峰窝是一个旅游网站,用户可以记录自己的旅游地点,创建或加入团体旅游。我们保留了至少有2名成员的团体,他们至少已经走过了3个场馆,并收集了他们的旅游场地。还收集了各组成员的旅游场所。基于上述标准,我们得到了5, 275个用户、995个组、1, 513个项目、39, 761个用户项目交互和3, 595个组项交互。平均而言,每组有7.19个用户。
② CAMRA2011是一个真实世界的数据集,包含个人用户和家庭的电影评级记录。由于大多数用户在数据集中没有组信息,所以我们过滤它们并保留已经加入组的用户。用户项目交互和组项交互是以0到100的评分量表进行的明确反馈。我们将评级记录转换为目标值为1的正实例,并将其他缺失数据作为负实例,目标值为0。最终数据集包含602个用户、290个组、7,710个项、116,344个用户项交互和145,068个组项交互。平均群体大小为2.08。
由于两个数据集都只包含正实例(即,观察到的交互),所以我们从缺失的数据中随机抽样作为负实例,以便与每个正实例配对。先前的努力表明,将负采样率从1增加到更大的值对top-K建议[16]是有益的。对于两个数据集的一致性,最优采样率在4到6之间,因此我们将负采样率固定为4。具体来说,对于马风窝的每个日志,我们随机抽样4个用户(组)从未访问过的场地;对于CAMRa2011的每个日志,我们随机抽样4个用户(组)从未观看过的电影。每个负实例被分配给目标值0。
(2)评价标准:
方法:LOO(leave-one-out):留一法:留一法交叉验证是一种用来训练和测试分类器的方法。用来评价top-k推荐性能。
标准:Hit Ratio (HR) and Normalized Discounted Cumulative Gain (NDCG)。
(3)基线模型:
- NCF
- Popularity
- COM
- GREE
4、总结:
在该框架下,评估一个群体对某个项目的偏好有两个关键因素:1)如何获取一个群体的语义表示,2)如何建模一个群体与一个项目的交互。