来自《TensorFlow深度学习》书籍
一、线性回归
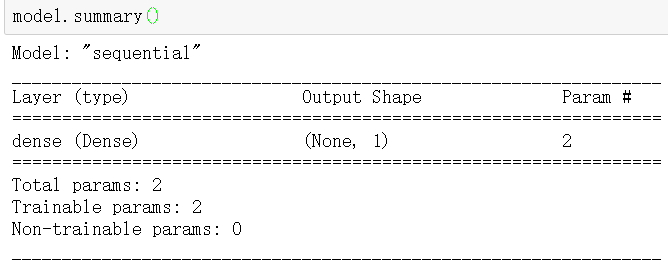
model = tf.keras.Sequential() #序列模型,在此基础上搭网络
model.add(tf.keras.layers.Dense(1,input_shape = (1,))) #全连接层
model.summary()
二、分类
import os import tensorflow as tf from tensorflow import keras from tensorflow.keras import layers, optimizers, datasets
加载数据
x的大小(60000,28,28),60000个样本,每个样本由28行、28列构成,数值大小为【0,255】
y大小为(60000),代表标签数字,0~9
#load_data()函数返回两个元祖(tuple)对象,第一个是训练集,第二个是测试集。 (x, y) , (x_val, y_val) = datasets.mnist.load_data() x = 2 * tf.convert_to_tensor(x, dtype=tf.float32) / 255. - 1 y = tf.convert_to_tensor(y, dtype=tf.int32) #转换成整形张量 print(x.shape, y.shape) train_dataset = tf.data.Dataset.from_tensor_slices((x,y)) #构建数据集对象 train_dataset = train_dataset.batch(512) #批量训练
模型


model = keras.Sequential([ layers.Dense(256, activation = 'relu'), #隐藏层1 layers.Dense(128, activation = 'relu'), #隐藏层2 layers.Dense(10) #输出层,输出节点数为10 ])
训练

with tf.GradientTape() as tape: #构建梯度记录环境 x = tf.reshape(x, (-1,28*28)) #打平操作,[b,28,28] => [b,284] out = model(x) #计算输出预测结果 [b,784] => [b ,10] y_onehot = tf.one_hot(y,depth=10) #[b] => [b,10] loss = tf.square(out - y_onehot) #计算差的平方和, [b,10] loss = tf.reduce_sum(loss) / x.shape[0] #计算每个样本的平均误差, [b] #自动求导函数求出所有参数的梯度信息,计算梯度w1, w2, w3, b1 ,b2 , b3 grads = tape.gradient(loss, model.trainable_variables) optimizer=optimizers.SGD(learning_rate=0.001) #更新网络参数,w '= w - lr * grad optimizer.apply_gradients(zip(grads,model.trainable_variables))