转载:https://blog.csdn.net/weixin_40924580/article/details/85023267
https://www.cnblogs.com/wmx24/p/10157154.html
https://www.jianshu.com/p/160c4800b9b5
https://blog.csdn.net/qq_39521554/article/details/83062188
https://baijiahao.baidu.com/s?id=1625869421219865699&wfr=spider&for=pc
一、业界框架:

Match(召回匹配)& Rank(推荐排序)
定义:Match基于当前user(profile、history)和context,快速在全库里找到TopN最相关的item,给Rank来做小范围综合多目标最大
通常做法:用各种算法做召回,比如user/item/model-based CF,Content-based,Demographic-based,DNN-Embedding-based等,做粗排之后交由后面的Rank层做更精细的排序。 
二、召回策略
主要有协同过滤、向量化召回和阿里最近在Aicon中提到的深度树匹配模型。
详细介绍:https://www.jianshu.com/p/ef3caa5672c8(摘自石晓文简书)
1、协同过滤召回:
user-cf、item-cf、矩阵分解
2、向量化召回:
主要通过模型来学习用户和物品的兴趣向量,并通过内积来计算用户和物品之间的相似性,从而得到最终的候选集。
YouTube召回模型:
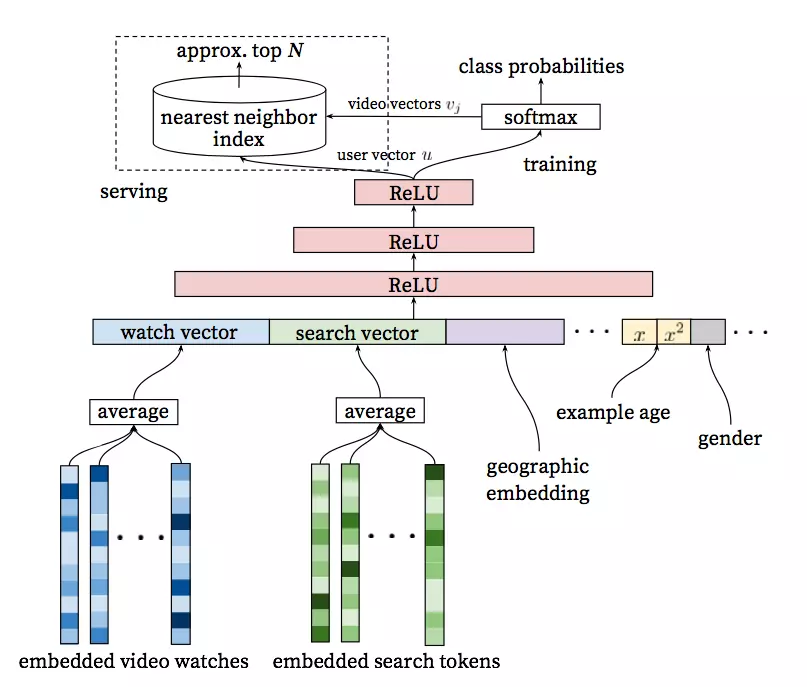
基于用户的历史观看记录和场景,学习一个用户向量U,通过一个softmax分类器,U能够有效地从视频预料库中识别视频的类别(即推荐的结果)
从模型结构可以看出,在离线训练阶段,将其视为一个分类问题。我们使用隐式反馈来进行学习,用户完整观看过一个视频,便视作一个正例。如果将视频库中的每一个视频当作一个类别,那么在时刻t,对于用户U和上下文C,用户会观看视频i的概率为:

局部敏感哈希(Locality-Sensitive Hashing, LSH)
3、深度树匹配
上面两种方法,揭示了召回中两个比较关键的问题:全库搜索、先进模型。
如果说向量化召回通过内积运算的方式打开了全库搜索的天花板,那么下一阶段应该是:能否设计一套全新的推荐算法框架,它允许容纳任意先进的模型而非限定内积形式,并且能够对全库进行更好的检索。
三、算法
1、基于共现关系的CF:User-based CF、Item-based CF、相似度
2、基于模型的CF:SVD算法、MF、SVD++、
2、FM模型:
3、深度学习: