参考:https://blog.csdn.net/malefactor/article/details/51078135
一、CNN网络模型
NLP中CNN模型网络:
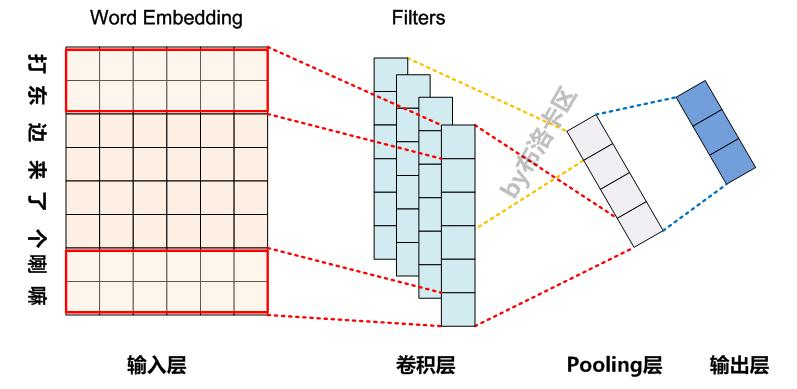
二、Pooling操作
1、CNN中的Max Pooling Over Time操作
(1)概念:
MaxPooling Over Time是NLP中CNN模型中最常见的一种下采样操作。意思是对于某个Filter抽取到若干特征值,只取其中得分最大的那个值作为Pooling层保留值,其它特征值全部抛弃,值最大代表只保留这些特征中最强的,而抛弃其它弱的此类特征。
(2)CNN中采用MaxPooling好处:
①这个操作可以保证特征的位置与旋转不变性,因为不论这个强特征在哪个位置出现,都会不考虑其出现位置而能把它提出来。对于图像处理来说这种位置与旋转不变性是很好的特性,但是对于NLP来说,这个特性其实并不一定是好事,因为在很多NLP的应用场合,特征的出现位置信息是很重要的,比如主语出现位置一般在句子头,宾语一般出现在句子尾等等,这些位置信息其实有时候对于分类任务来说还是很重要的,但是Max Pooling 基本把这些信息抛掉了。
②MaxPooling能减少模型参数数量,有利于减少模型过拟合问题。因为经过Pooling操作后,往往把2D或者1D的数组转换为单一数值,这样对于后续的Convolution层或者全联接隐层来说无疑单个Filter的参数或者隐层神经元个数就减少了。
③对于NLP任务来说,Max Pooling有个额外的好处;在此处,可以把变长的输入X整理成固定长度的输入。因为CNN最后往往会接全联接层,而其神经元个数是需要事先定好的,如果输入是不定长的那么很难设计网络结构。前文说过,CNN模型的输入X长度是不确定的,而通过Pooling 操作,每个Filter固定取1个值,那么有多少个Filter,Pooling层就有多少个神经元,这样就可以把全联接层神经元个数固定住(如图2所示),这个优点也是非常重要的。
【 Pooling层神经元个数等于Filters个数】
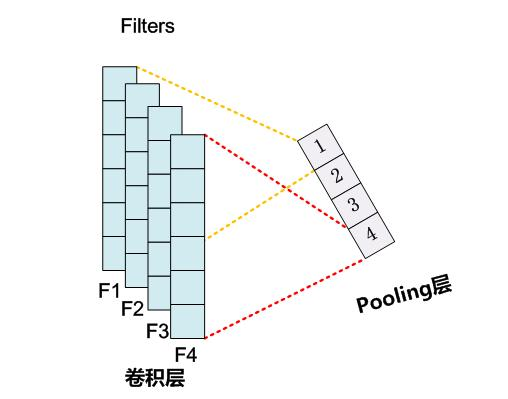
(3)CNN模型采取MaxPooling Over Time的缺点:
①特征的位置信息在这一步骤完全丢失。在卷积层其实是保留了特征的位置信息的,但是通过取唯一的最大值,现在在Pooling层只知道这个最大值是多少,但是其出现位置信息并没有保留;
②有时候有些强特征会出现多次,比如我们常见的TF.IDF公式,TF就是指某个特征出现的次数,出现次数越多说明这个特征越强,但是因为Max Pooling只保留一个最大值,所以即使某个特征出现多次,现在也只能看到一次,就是说同一特征的强度信息丢失了。
2、改进的Pooling操作:K-Max Pooling
(1)K-MaxPooling的概念:
原先的Max Pooling Over Time从Convolution层一系列特征值中只取最强的那个值,那么我们思路可以扩展一下,K-Max Pooling可以取所有特征值中得分在Top –K的值,并保留这些特征值原始的先后顺序(图3是2-max Pooling的示意图),就是说通过多保留一些特征信息供后续阶段使用。 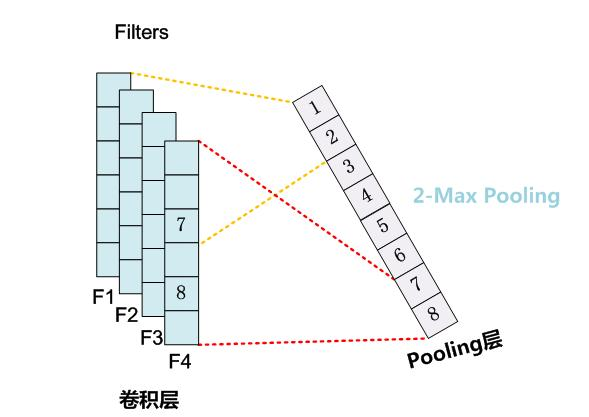
很明显,K-Max Pooling可以表达同一类特征出现多次的情形,即可以表达某类特征的强度;另外,因为这些Top K特征值的相对顺序得以保留,所以应该说其保留了部分位置信息,但是这种位置信息只是特征间的相对顺序,而非绝对位置信息。
(2)keras实现:https://blog.csdn.net/u010976347/article/details/80739208
3、Chunk-Max Pooling
(1)Chunk-MaxPooling的思想是:
把某个Filter对应的Convolution层的所有特征向量进行分段,切割成若干段后,在每个分段里面各自取得一个最大特征值,比如将某个Filter的特征向量切成3个Chunk,那么就在每个Chunk里面取一个最大值,于是获得3个特征值。(如图4所示,不同颜色代表不同分段) 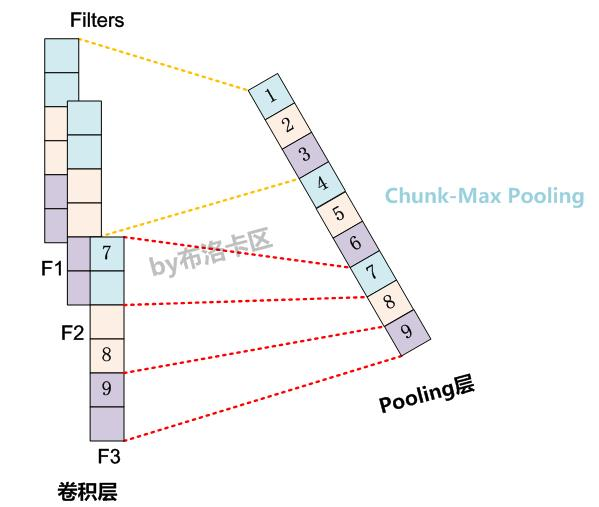
乍一看Chunk-Max Pooling思路类似于K-Max Pooling,因为它也是从Convolution层取出了K个特征值,但是两者的主要区别是:K-Max Pooling是一种全局取Top K特征的操作方式,而Chunk-Max Pooling则是先分段,在分段内包含特征数据里面取最大值,所以其实是一种局部Top K的特征抽取方式。
至于这个Chunk怎么划分,可以有不同的做法,比如可以事先设定好段落个数,这是一种静态划分Chunk的思路;也可以根据输入的不同动态地划分Chunk间的边界位置,可以称之为动态Chunk-Max方法(这种称谓是我随手命名的,非正式称谓,请注意)。
Chunk-Max Pooling很明显也是保留了多个局部Max特征值的相对顺序信息,尽管并没有保留绝对位置信息,但是因为是先划分Chunk再分别取Max值的,所以保留了比较粗粒度的模糊的位置信息;当然,如果多次出现强特征,则也可以捕获特征强度。
Event Extraction via Dynamic Multi-Pooling Convolutional Neural Networks这篇论文提出的是一种ChunkPooling的变体,就是上面说的动态Chunk-Max Pooling的思路,实验证明性能有提升。Local Translation Prediction with Global Sentence Representation 这篇论文也用实验证明了静态Chunk-Max性能相对MaxPooling Over Time方法在机器翻译应用中对应用效果有提升。
总结:
如果思考一下,就会发现,如果分类所需要的关键特征的位置信息很重要,那么类似Chunk-Max Pooling这种能够粗粒度保留位置信息的机制应该能够对分类性能有一定程度的提升作用;但是对于很多分类问题,估计Max-Pooling over time就足够了。
比如我们拿情感分类来说,估计用Chunk-max策略应该有帮助,因为对于这种表达模式:
“Blablabla….表扬了你半天,BUT…..你本质上就是个渣”
与这种表达模式
“虽然说你是个渣,但是…..Blablabla…..欧巴我还是觉得你最好,因为你最帅”
明显位置信息对于判别整体情感倾向是有帮助作用的,所以引入位置信息应该有帮助。
所以,你分析下你手头的问题,看看位置是不是重要特征,如果是,那么套用一下Chunk-Max策略,估计性能会有提升,比如上面举的情感分类问题估计效果会有提升。