一、训练集、验证集和测试集
传统的机器学习的切分:【小数量,百、千、万】
70%的训练集、30%的测试集
60%的训练集、20%验证集和20%的测试集
大数据时代:【百万、千万、亿】
验证集的目的是验证不同的算法,检验哪种算法有效。
百万:98%训练,1%验证,1%测试
超过百万:99.5%训练,0.25%验证,0.25测试或者0.4、0.1做测试都可以
比如:100万条数据,1万做验证集,1万做测试集,98万做训练集。
经验法则:验证集和测试集同一分布。
二、偏差和方差:
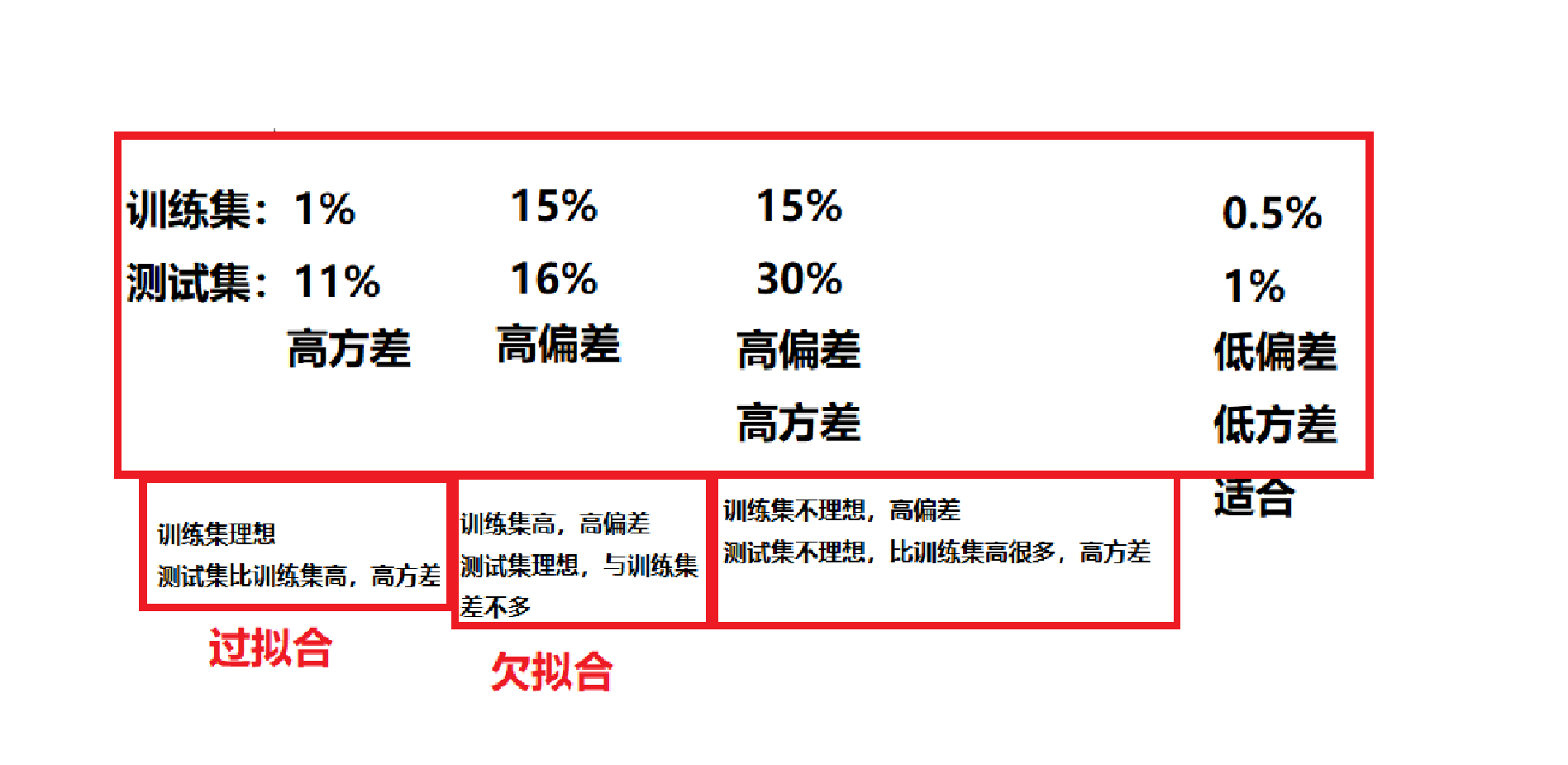
三、防止过拟合的技术:正则化、early stopping、参数共享
四、正则化:L2、Dropout(随机失活)
正则化可以解决过拟合问题,因为比如加上一个 λ * L2【 ||W||2 】,如果λ过大,则 W趋向于0,则由一个深层神经网络变成一个浅层神经网络,会变成欠拟合状态。如果λ过小,则还是处于过拟合状态。如果适中,则问题解决。
Dropout正则化:在前向传播的时候,让某个神经元的激活值以一定的概率p停止工作,使模型泛化性更强,因为它不会太依赖某些局部的特征。【消除某些节点】
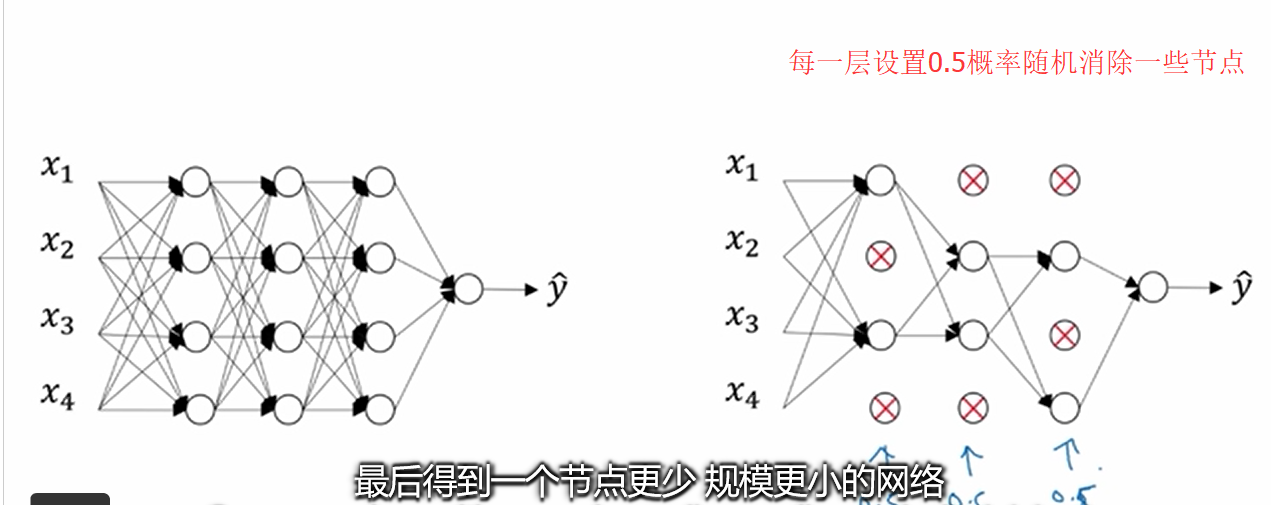
Dropout常用的方法:inverted dropout(反向随机失活)
过程:
(1)首先随机(临时)删掉网络中一半的隐藏神经元,输入输出神经元保持不变(图3中虚线为部分临时被删除的神经元)
(2) 然后把输入x通过修改后的网络前向传播,然后把得到的损失结果通过修改的网络反向传播。一小批训练样本执行完这个过程后,在没有被删除的神经元上按照随机梯度下降法更新对应的参数(w,b)。
(3)然后继续重复这一过程:.
恢复被删掉的神经元(此时被删除的神经元保持原样,而没有被删除的神经元已经有所更新).
从隐藏层神经元中随机选择一个一半大小的子集临时删除掉(备份被删除神经元的参数)。.
对一小批训练样本,先前向传播然后反向传播损失并根据随机梯度下降法更新参数(w,b) (没有被删除的那一部分参数得到更新,删除的神经元参数保持被删除前的结果)。
(1)训练阶段采用dropout:
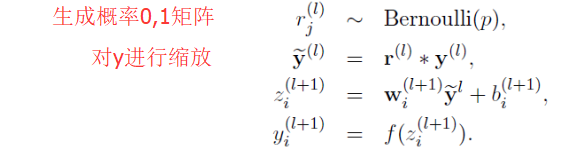
上面公式中Bernoulli函数是为了生成概率r向量,也就是随机生成一个0、1的向量。
代码层面实现让某个神经元以概率p停止工作,其实就是让它的激活函数值以概率p变为0。
比如我们某一层网络神经元的个数为1000个,其激活函数输出值为y1、y2、y3、......、y1000,我们dropout比率选择0.4,那么这一层神经元经过dropout后,1000个神经元中会有大约400个的值被置为0。
注意: 经过上面屏蔽掉某些神经元,使其激活值为0以后,我们还需要对向量y1……y1000进行缩放,也就是乘以1/(1-p)。如果你在训练的时候,经过置0后,没有对y1……y1000进行缩放(rescale),那么在测试的时候,就需要对权重进行缩放,操作如下。
(2)在测试模型阶段
预测模型的时候,每一个神经单元的权重参数要乘以概率p。

测试阶段Dropout公式:
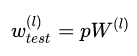
五、梯度消失和梯度爆炸
W>1,W1*W2*……*Wn爆炸
W<1,W1*W2*……*Wn消失,趋向于0