1.爬虫介绍
1.1 什么是爬虫
互联网最有价值的就是资源,爬虫要做的就是爬取资源,比如链家网的租房信息,拉勾网的求职信息,岛国的资源等等
1.2 爬虫流程
发送请求------>获取响应------>爬取资源(下载资源)------>解析数据------>数据持久化(mongodb数据库,redis数据库)
请求模块:requests模块,selenium模块
解析模块:BeautifulSoup模块,xpath模块
2. requests模块
Requests 唯一的一个非转基因的 Python HTTP 库,人类可以安全享用
Requests 允许你发送纯天然,植物饲养的 HTTP/1.1 请求,无需手工劳动。你不需要手动为 URL 添加查询字串,也不需要对 POST 数据进行表单编码。Keep-alive 和 HTTP 连接池的功能是 100% 自动化的,一切动力都来自于根植在 Requests 内部的 urllib3。(来源官网)
#各种请求方式:常用的就是requests.get()和requests.post() >>> import requests >>> r = requests.get('https://api.github.com/events') >>> r = requests.post('http://httpbin.org/post', data = {'key':'value'}) >>> r = requests.put('http://httpbin.org/put', data = {'key':'value'}) >>> r = requests.delete('http://httpbin.org/delete') >>> r = requests.head('http://httpbin.org/get') >>> r = requests.options('http://httpbin.org/get')
官网链接:猛戳此处
2.1 对于get请求
#GET请求 HTTP默认的请求方法就是GET * 没有请求体 * 数据必须在1K之内! * GET请求数据会暴露在浏览器的地址栏中 GET请求常用的操作: 1. 在浏览器的地址栏中直接给出URL,那么就一定是GET请求 2. 点击页面上的超链接也一定是GET请求 3. 提交表单时,表单默认使用GET请求,但可以设置为POST
常见get请求
import requests response = requests.get("https://www.jd.com/") with open('jingdong.html','wb') as f: f.write(response.content)
或者获取它的文本信息:
import requests response = requests.get("https://www.jd.com/") print(response.text)
带参数的get请求:
对于某些网站(比如百度),我们需要伪装成流程器,必须携带浏览器可识别的请求头信息
在百度搜索关于python的文本信息
import requests response=requests.get('https://www.baidu.com/s?wd=python&pn=1', headers={ 'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.75 Safari/537.36', }) print(response.text)
# 对于某些网站,我们的请求头可能不止仅携带user-agent信息,请求头是将自身伪装成浏览器的关键,常见的有用的请求头如下
Host Referer #大型网站通常都会根据该参数判断请求的来源 User-Agent #客户端 Cookie #Cookie信息虽然包含在请求头里,但requests模块有单独的参数来处理他,headers={}内就不要放它了
request.session()的使用
import requests # res=requests.get("https://www.zhihu.com/explore") # print(res.cookies.get_dict()) # {'_xsrf': '4oL216OENatT6LIshv3zBlXFpvTW4lcM', 'tgw_l7_route': 'b3dca7eade474617fe4df56e6c4934a3'} session = requests.session() res1 = session.get("https://www.zhihu.com/explore") # 访问该页面后会生成cookie res2 = session.get("https://www.zhihu.com/question/40031734/answer/499507903", # 302重定向到该问题 headers={ "User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3534.4 Safari/537.36" } # 必须还要携带请求头相关信息 ) print(res2.text)
2.2 对于post请求
#POST请求 * 数据不会出现在地址栏中 * 数据的大小没有上限 * 有请求体 * 请求体中如果存在中文,会使用URL编码!
requests.post()用法与requests.get()完全一致,特殊的是requests.post()有一个data参数,用来存放请求体数据
模拟github登陆,获取登陆信息
import requests import re #请求1: r1=requests.get('https://github.com/login') r1_cookie=r1.cookies.get_dict() #拿到初始cookie(未被授权) authenticity_token=re.findall(r'name="authenticity_token".*?value="(.*?)"',r1.text)[0] #从页面中拿到CSRF TOKEN print("authenticity_token",authenticity_token) #第二次请求:带着初始cookie和TOKEN发送POST请求给登录页面,带上账号密码 data={ 'commit':'Sign in', 'utf8':'✓', 'authenticity_token':authenticity_token, 'login':'yuanchenqi0316@163.com', 'password':'yuanchenqi0316' } #请求2: r2=requests.post('https://github.com/session', data=data, cookies=r1_cookie, # allow_redirects=False ) print(r2.status_code) #200 print(r2.url) #看到的是跳转后的页面:https://github.com/ print(r2.history) #看到的是跳转前的response:[<Response [302]>] print(r2.history[0].text) #看到的是跳转前的response.text with open("result.html","wb") as f: f.write(r2.content)
这里其实我们也可以通过使用session请求来获取我们的cookie
3.响应Response
常见属性
import requests
respone=requests.get('https://sh.lianjia.com/ershoufang/')
# respone属性
print(respone.text)
print(respone.content)
print(respone.status_code)
print(respone.headers)
print(respone.cookies)
print(respone.cookies.get_dict())
print(respone.cookies.items())
print(respone.url)
print(respone.history)
print(respone.encoding)
下载二进制文件(图片,视频,音频)
import requests response=requests.get('https://gss3.baidu.com/6LZ0ej3k1Qd3ote6lo7D0j9wehsv/' 'tieba-smallvideo-transcode/1767502_56ec685f9c7ec542eeaf6eac93a65dc7_6fe25cd1347c_3.mp4', stream=True) #stream参数:表示一点一点的取 with open('b.mp4','wb') as f: for line in response.iter_content(): f.write(line) # 一行一行的写入
json解析
对于获取某些数据需要进行反序列化,此时我们可以直接使用response.json()
import requests import json response=requests.get('http://httpbin.org/get') res1=json.loads(response.text) #太麻烦 res2=response.json() #直接获取json数据 print(res1==res2)
Response.history
Response.history 是一个 Response 对象的列表,为了完成请求而创建了这些对象。这个对象列表按照从最老到最近的请求进行排序。
>>> r = requests.get('http://github.com')
>>> r.url
'https://github.com/'
>>> r.status_code
200
>>> r.history
[<Response [301]>]
# 还可以通过 allow_redirects 参数禁用重定向处理
4. 爬取拉勾网信息
我们进入首页,输入python职位搜索,按F12查看搜索信息,发现response中除了职位信息,其他东西都有
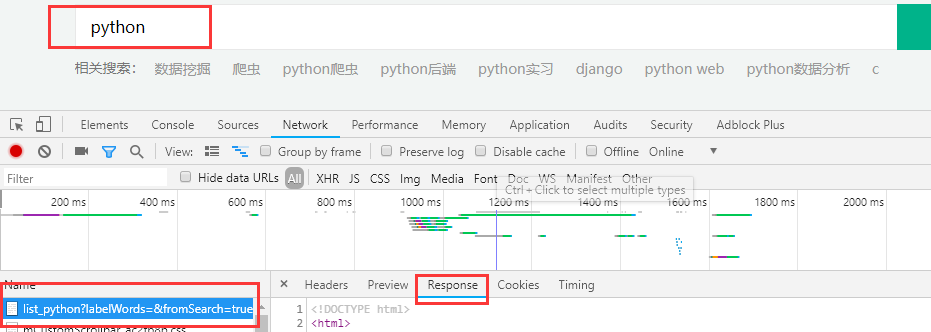
说明这里可能发生了重定向,或者我们需要的信息后台通过ajax发送来的,再次检查发现他的端口号是200,没有重定向,那只有是第二种可能
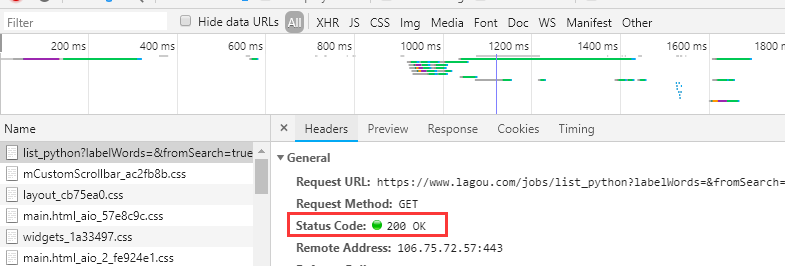
这里可能会报访问频繁,这就是网页所用的反爬机制,注意这里需要先获取网站的cookie,携带cookie去访问我们的网页。
代码演示:
base_url1 = "https://www.lagou.com/jobs/list_python" base_url = 'https://www.lagou.com/jobs/positionAjax.json?px=default&city=%E8%A5%BF%E5%AE%89&needAddtionalResult=false' headers = { 'Referer': "https://www.lagou.com/jobs/list_python/p-city_298?px=default", 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.97 Safari/537.36', } session = requests.session() session.get(url=base_url1, headers=headers) # 第一步先获取cookie res = session.post(url=base_url,headers=headers) print(res.text)