python内置函数
截止到python版本3.6.2,python一共为我们提供了68个内置函数。它们就是python提供给你直接可以拿来使用的所有函数
思维导图:https://www.processon.com/mindmap/5a97b9d7e4b083b043a1dcd5
以下是具体分布:
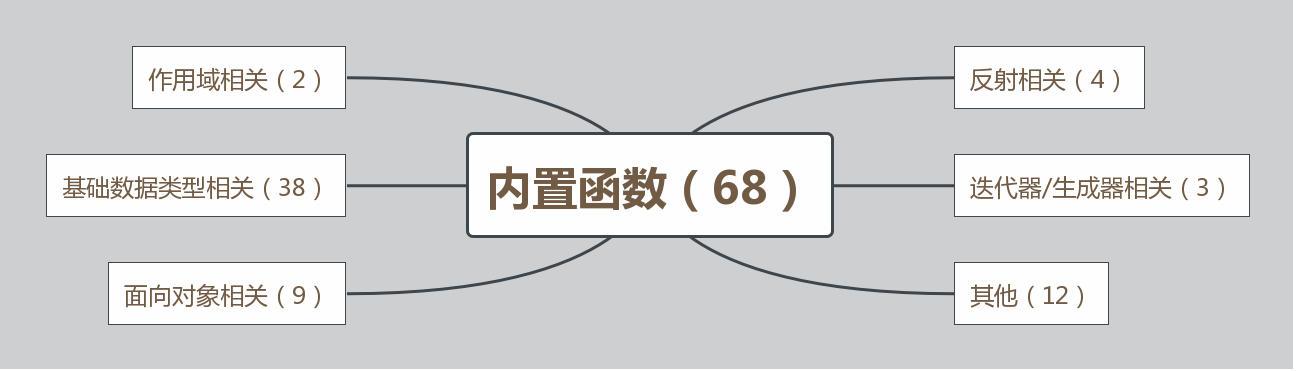
python所用内置函数:
https://docs.python.org/3/library/functions.html
http://www.cnblogs.com/sesshoumaru/category/894935.html
以下需常看的内容:
算法相关
# divmod() 这个做项目后期会用到
print(divmod(10, 3)) # 取商/余
---(3, 1)
# round()
print(round(3.1415926, 2)) # 求取精确度,保留两位小数
---3.14
# power()
print(pow(2, 3)), print(2**3) # 求幂运算,两个等同
---8
# complex:函数用于创建一个值为real + imag*j的复数或者转化一个字符串或数为复数。
如果第一个参数为字符串,则不需要指定第二个参数。
complex(1,4)
---(1+4j)
complex(1) # 数字
---(1 + 0j)
complex("1") # 当做字符串处理
---(1 + 0j)
# abs(): 如果输入是整数或者浮点数,它返回的是输入值的绝对值;
如果输入是复数(complex number),那么返回这个复数的模
# reversed() 顺序的反转
l = [1, 2, 3, 4]
print(list(reversed(l))) # 是生成了一个新的列表,没有改变原来的列表
---[4,3,2,1]
l.reverse() # 在现在的列表的基础上修改了,修改的是原来的列表
print(l)
---[4,3,2,1]
--------------------------------------------------------------------------------------------
内存相关
# hash:获取可哈希对象(int,str,Bool,tuple)的的哈希值
(如果在Python中需要对用户输入的密码或者其他内容进行加密,出于安全性考虑首选的方法是生成hash值)
print(hash('arg'))
-8969565126408161272 # 这里虽然一次运行时值是一致的,但是重新运行时得到的值就不相同了,详见知乎
print(hash(True)) # 1
print(hash(False)) # 0
# id:返回对象的唯一标识符,用整数表示。在程序生命周期内,这个标识符常量是唯一的。
id(2)
---1940280128
--------------------------------------------------------------------------------------------
进制转换相关
# bin:将十进制转换成二进制并返回
# oct:将十进制转化成八进制字符串并返回
# hex:将十进制转化成十六进制字符串并返回
print(bin(5), type(bin(5)))
---0b101 <class 'str'>
print(oct(5), type(oct(5)))
---0o5 <class 'str'>
print(hex(5), type(hex(5)))
---0x5 <class 'str'>
---------------------------------------------------------------------------------------------
字符串相关
# repr:返回一个对象的string形式(原形毕露,连引号都给打印出来了)
print(repr('{"name":"alex"}'))
---'{"name":"alex"}'
print('{"name":"alex"}')
---{"name":"alex"}
(这里其实就和格式化字符串概念一样)
%r ---是什么就返回什么
%d ---返回整形数字
%f ---返回浮点型数字
%s ---返回字符串类型
# format:与具体数据相关,用于计算各种小数,精算等,此外这个用于格式化输出很重要(详见我的博客第二节)
# 字符串可以提供的参数,指定对齐方式,<是左对齐, >是右对齐,^是居中对齐
print(format('test', '<20'))
print(format('test', '>20'))
print(format('test', '^20'))
其他用法详见链接:http://www.cnblogs.com/jin-xin/articles/8423937.html
# bytes:用于不同编码之间的转换,只能编码,将unicode ---> 非unicode bytes(s1,encoding='utf-8')。
print('你好'.encode('utf-8'))
---b'xe4xbdxa0xe5xa5xbd'
bs = bytes('你好', encoding='utf-8')
print(bs)
---b'xe4xbdxa0xe5xa5xbd'
(两个结果是一样的,但是明显没有直接encode好用)
# ord:输入字符找该字符编码的位置 unicode
# chr:输入位置数字找出其对应的字符 unicode
# ascii:是ascii码中的返回该值,不是就返回u...
print(ord('a'))
---97
print(ord('中'))
---20013
print(chr(97))
---a
print(chr(20013))
---中
print(ascii('a'))
---'a'
print(ascii('中'))
---'u4e2d'
# bytearry:返回一个新字节数组。这个数组里的元素是可变的,并且每个元素的值范围: 0 <= x < 256
ret = bytearray('alex', encoding='utf-8')
print(id(ret))
---2448694454456
print(ret)
---bytearray(b'alex')
print(ret[0]) # 找到字母a对应ascll表的位置
---97
ret[0] = 65 # 将其通过修改ascll表的位置对其字母进行修改
print(ret)
---bytearray(b'Alex')
print(id(ret))
2448694454456 # 对其修改完但是它的id并没有发生改变
# memoryview:
ret = memoryview(bytes('你好',encoding='utf-8'))
print(len(ret))
---6
print(ret) # 打印出内存地址
---<memory at 0x0000021B7F2BB1C8>
print(bytes(ret[:3]).decode('utf-8')) #通过内存地址切片
---你
print(bytes(ret[3:]).decode('utf-8'))
---好
---------------------------------------------------------------------------------------------
字符串代码执行相关
# eval函数() # 执行字符串类型的代码,并返回最终结果
print(eval('3+5'))
---8
num = eval('6+8+5')
print(num) # 执行了有返回值
---19
# exec()函数 # 执行字符串类型的代码,它属于流程语句
num = exec('6+8+5')
print(num) # 执行但是没有返回值
---None
ret1 = '''
li = [1,2,3]
for i in li:
print(i)
'''
print(exec(retl))
---1
---2
---3
---None
# compile # 将字符串类型的代码翻译,代码对象能够通过exec()语句执行或者是eval()进行求值
'''
参数说明:
1. 参数source:字符串或者动态执行的代码段。
2. 参数filename:代码文件名称,如果不是从文件读取代码则传递一些可辨认的值。
当传入了source参数时,filename参数传入空字符即可。
3. 参数model:指定编译代码的种类,可以指定为 ‘exec’,’eval’,’single’
当source中包含流程语句时,model应指定为‘exec’;
当source中只包含一个简单的求值表达式,model应指定为‘eval’;
当source中包含了交互式命令语句,model应指定为'single'。
'''
# 流程语句使用exec
code1 = 'for i in range(0,3): print (i)'
compile1 = compile(code1, '', 'exec')
exec(compile1)
---0
---1
---2
# 简单求值表达式用eval
code2 = '1 + 2 + 3 + 4'
compile2 = compile(code2, '', 'eval')
print(eval(compile2))
---10
# 交互语句用single # 略,看不懂,也用不上
-------------------------------------------------------------------------------------------
其他容易遗忘的知识点
# help():用于查看函数或模块用途的详细说明
# dir():函数不带参数时,返回当前范围内的变量、方法和定义的类型列表;
带参数时,返回参数的属性、方法列表。
# callable:函数用于检查一个对象是否是可调用的。如果返回True,object仍然可能调用失败;但如果返回False,调用对象ojbect绝对不会成功。
def func1():
print(555)
a = 3
f = func1
print(callable(f))
---True
print(callable(a))
---False
zip函数
zip()是Python的一个内建函数,它接受一系列可迭代的对象作为参数,将对象中对应的元素打包成一个个tuple(元组),
zip()是Python的一个内建函数,它接受一系列可迭代的对象作为参数,将对象中对应的元素打包成一个个tuple(元组),
然后返回由这些tuples组成的list(列表)。若传入参数的长度不等,则返回list的长度和参数中长度最短的对象相同。
利用*号操作符,可以将list unzip(解压)。
py3中zip()是可迭代对象,使用时必须将其包含在一个list中,方便一次性显示出所有结果
→这里和py2的差别很大啊
a = [1,2,3] b = [4,5,6] c = [4,5,6,7,8] d = zip(a,b)
print(list(d)) ---[(1, 4), (2, 5), (3, 6)]
d = dict(zip(a,b)) # 通过使用zip函数来构造字典
print(d)
---{1: 4, 2: 5, 3: 6}
d = {} # 也是字典类型
for k,v in zip(a,b) : d[k] = v
print(d)
---{1: 4, 2: 5, 3: 6}
l = ['a', 'b', 'c', 'd', 'e','f']
a = list(zip(l[:-1], l[1:])) # l[:-1]后面'f'没取,l[1:]前面'a'没取
print(a)
---[('a', 'b'), ('b', 'c'), ('c', 'd'), ('d', 'e'), ('e', 'f')]
二维矩阵变换:
a = [[1, 2, 3], [4, 5, 6], [7, 8, 9]] b = [[row[col] for row in a] for col in range(len(a[0]))] print(b) ---[[1, 4, 7], [2, 5, 8], [3, 6, 9]] a = [[1, 2, 3], [4, 5, 6], [7, 8, 9]]
c = list(zip(*a))
print(c)
---[(1, 4, 7), (2, 5, 8), (3, 6, 9)]
d = map(list,zip(*a))
print(list(d))
---[[1, 4, 7], [2, 5, 8], [3, 6, 9]]