摘要: 对比GET与POST。
- 原文:都9102年了,还问GET和POST的区别
- 作者:程淇铭
Fundebug经授权转载,版权归原作者所有。
1. 前言
最近看了一些同学的面经,发现无论什么技术岗位,还是会问到 get 和 post 的区别,而搜索出来的答案并不能让我们装得一手好逼,那就让我们从 HTTP 报文的角度来撸一波,从而搞明白他们的区别。
2. 标准答案
在开撸之前吗,让我们先看一下标准答案长什么样子 w3school: GET 对比 POST。标准答案很美好,但是在面试的时候把下面的表格甩面试官一脸,估计会装逼不成反被*。
| 分类 | GET | POST |
|---|---|---|
| 后退按钮/刷新 | 无害 | 数据会被重新提交(浏览器应该告知用户数据会被重新提交)。 |
| 书签 | 可收藏为书签 | 不可收藏为书签 |
| 缓存 | 能被缓存 | 不能缓存 |
| 编码类型 | application/x-www-form-urlencoded | application/x-www-form-urlencoded 或 multipart/form-data。为二进制数据使用多重编码。 |
| 历史 | 参数保留在浏览器历史中。 | 参数不会保存在浏览器历史中。 |
| 对数据长度的限制 | 是的。当发送数据时,GET 方法向 URL 添加数据;URL 的长度是受限制的(URL 的最大长度是 2048 个字符)。 | 无限制。 |
| 对数据类型的限制 | 只允许 ASCII 字符。 | 没有限制。也允许二进制数据。 |
| 安全性 | 与 POST 相比,GET 的安全性较差,因为所发送的数据是 URL 的一部分。在发送密码或其他敏感信息时绝不要使用 GET ! | POST 比 GET 更安全,因为参数不会被保存在浏览器历史或 web 服务器日志中。 |
| 可见性 | 数据在 URL 中对所有人都是可见的。 | 数据不会显示在 URL 中。 |
注意,并不是说标准答案有误,上述区别在大部分浏览器上是存在的,因为这些浏览器实现了 HTTP 标准。
所以从标准上来看,GET 和 POST 的区别如下:
- GET 用于获取信息,是无副作用的,是幂等的,且可缓存
- POST 用于修改服务器上的数据,有副作用,非幂等,不可缓存
但是,既然本文从报文角度来说,那就先不讨论 RFC 上的区别,单纯从数据角度谈谈。
3. GET 和 POST 报文上的区别
先下结论,GET 和 POST 方法没有实质区别,只是报文格式不同。
GET 和 POST 只是 HTTP 协议中两种请求方式,而 HTTP 协议是基于 TCP/IP 的应用层协议,无论 GET 还是 POST,用的都是同一个传输层协议,所以在传输上,没有区别。
报文格式上,不带参数时,最大区别就是第一行方法名不同
POST方法请求报文第一行是这样的 POST /uri HTTP/1.1
GET方法请求报文第一行是这样的 GET /uri HTTP/1.1
是的,不带参数时他们的区别就仅仅是报文的前几个字符不同而已
带参数时报文的区别呢? 在约定中,GET 方法的参数应该放在 url 中,POST 方法参数应该放在 body 中
举个例子,如果参数是 name=qiming.c, age=22。
GET 方法简约版报文是这样的
GET /index.php?name=qiming.c&age=22 HTTP/1.1
Host: localhostPOST 方法简约版报文是这样的
POST /index.php HTTP/1.1
Host: localhost
Content-Type: application/x-www-form-urlencoded
name=qiming.c&age=22
现在我们知道了两种方法本质上是 TCP 连接,没有差别,也就是说,如果我不按规范来也是可以的。我们可以在 URL 上写参数,然后方法使用 POST;也可以在 Body 写参数,然后方法使用 GET。当然,这需要服务端支持。
4. 常见问题
GET 方法参数写法是固定的吗?
在约定中,我们的参数是写在 ? 后面,用 & 分割。
我们知道,解析报文的过程是通过获取 TCP 数据,用正则等工具从数据中获取 Header 和 Body,从而提取参数。
也就是说,我们可以自己约定参数的写法,只要服务端能够解释出来就行,一种比较流行的写法是 http://www.example.com/user/name/chengqm/age/22。
POST 方法比 GET 方法安全?
按照网上大部分文章的解释,POST 比 GET 安全,因为数据在地址栏上不可见。
然而,从传输的角度来说,他们都是不安全的,因为 HTTP 在网络上是明文传输的,只要在网络节点上捉包,就能完整地获取数据报文。
要想安全传输,就只有加密,也就是 HTTPS。
GET 方法的长度限制是怎么回事?
在网上看到很多关于两者区别的文章都有这一条,提到浏览器地址栏输入的参数是有限的。
首先说明一点,HTTP 协议没有 Body 和 URL 的长度限制,对 URL 限制的大多是浏览器和服务器的原因。
浏览器原因就不说了,服务器是因为处理长 URL 要消耗比较多的资源,为了性能和安全(防止恶意构造长 URL 来攻击)考虑,会给 URL 长度加限制。
POST 方法会产生两个TCP数据包?
有些文章中提到,post 会将 header 和 body 分开发送,先发送 header,服务端返回 100 状态码再发送 body。
HTTP 协议中没有明确说明 POST 会产生两个 TCP 数据包,而且实际测试(Chrome)发现,header 和 body 不会分开发送。
所以,header 和 body 分开发送是部分浏览器或框架的请求方法,不属于 post 必然行为。
5. talk is cheap show me the code
如果对 get 和 post 报文区别有疑惑,直接起一个 Socket 服务端,然后封装简单的 HTTP 处理方法,直接观察和处理 HTTP 报文,就能一目了然
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import socket
HOST, PORT = '', 23333
def server_run():
listen_socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
listen_socket.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)
listen_socket.bind((HOST, PORT))
listen_socket.listen(1)
print('Serving HTTP on port %s ...' % PORT)
while True:
# 接受连接
client_connection, client_address = listen_socket.accept()
handle_request(client_connection)
def handle_request(client_connection):
# 获取请求报文
request = ''
while True:
recv_data = client_connection.recv(2400)
recv_data = recv_data.decode()
request += recv_data
if len(recv_data) < 2400:
break
<span class="hljs-comment"># 解析首行</span>
first_line_array = request.split(<span class="hljs-string">'
'</span>)[<span class="hljs-number">0</span>].split(<span class="hljs-string">' '</span>)
<span class="hljs-comment"># 分离 header 和 body</span>
space_line_index = request.index(<span class="hljs-string">'
'</span>)
header = request[<span class="hljs-number">0</span>: space_line_index]
body = request[space_line_index + <span class="hljs-number">4</span>:]
<span class="hljs-comment"># 打印请求报文</span>
print(request)
<span class="hljs-comment"># 返回报文</span>
http_response = <span class="hljs-string">b"""
HTTP/1.1 200 OK
<!DOCTYPE html>
<html>
<head>
<title>Hello, World!</title>
</head>
<body>
<p style="color: green">Hello, World!</p>
</body>
</html>
"""
client_connection.sendall(http_response)
client_connection.close()
if name == 'main':
server_run()
上面代码就是简单的打印请求报文然后返回 HelloWorld 的 html 页面,我们运行起来
[root@chengqm shell]# python httpserver.py
Serving HTTP on port 23333 ...然后从浏览器中请求看看
打印出来的报文

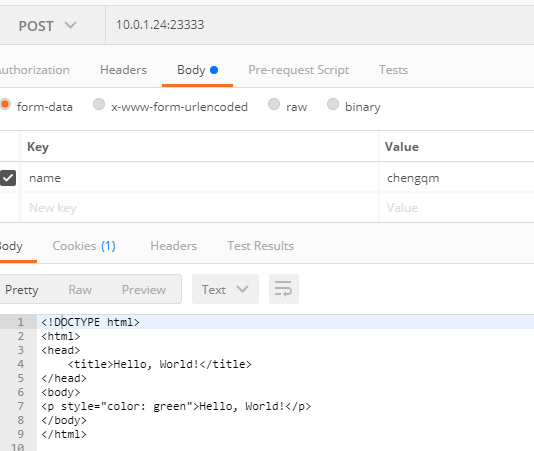
然后就可以手动证明上述说法,比如说要测试 header 和 body 是否分开传输,由于代码没有返回 100 状态码,如果我们 post 请求成功就说明是一起传输的(Chrome/postman)。
又比如 w3school 里面说 URL 的最大长度是 2048 个字符,那我们在代码里面加上一句计算 uri 长度的代码
...
# 解析首行
first_line_array = request.split('
')[0].split(' ')
print('uri长度: %s' % len(first_line_array[1]))
...我们用 postman 直接发送超过 2048 个字符的请求看看

然后我们可以得出结论,url 长度限制是某些浏览器和服务器的限制,和 HTTP 协议没有关系。
到此,我们可以愉快地装逼了 :)
参考
- 99%的人都理解错了HTTP中GET与POST的区别
- 关于HTTP GET 和 POST
- w3school: HTTP 方法:GET 对比 POST
- wikipedia: 超文本传输协议
- RFC 2068
关于Fundebug
Codeforces Round #203 (Div. 2)
Codeforces Round #206 (Div. 2)
Codeforces Round #204 (Div. 2): C
Codeforces Round #204 (Div. 2): B
Codeforces Round #204 (Div. 2): A
Codeforces Round #205 (Div. 2) : D
Codeforces Round #205 (Div. 2) : C
Codeforces Round #205 (Div. 2) : B
Codeforces Round #205 (Div. 2) : A