二次侧 一千多万条数据
SELECT count(1) FROM d_secondminutehandledata
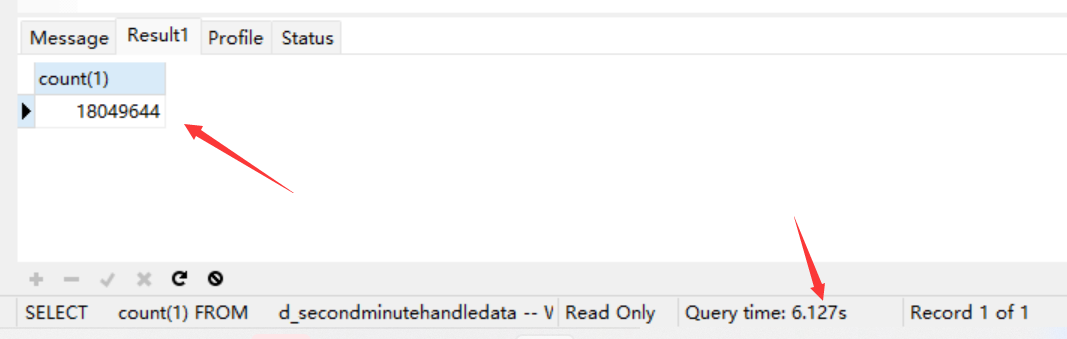
SELECT count(1) FROM d_secondminutehandledata WHERE collectionTime BETWEEN '2022-01-13' AND '2023-03-01'
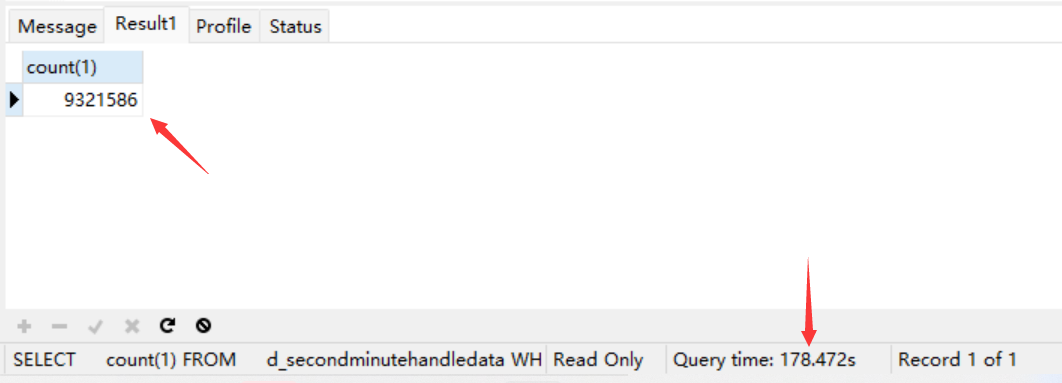
没有索引的时候,一个count都这么的慢
SELECT count(1) FROM d_secondminutehandledata WHERE stationBranchId = 533 AND collectionTime BETWEEN '2022-01-13' AND '2023-03-01'
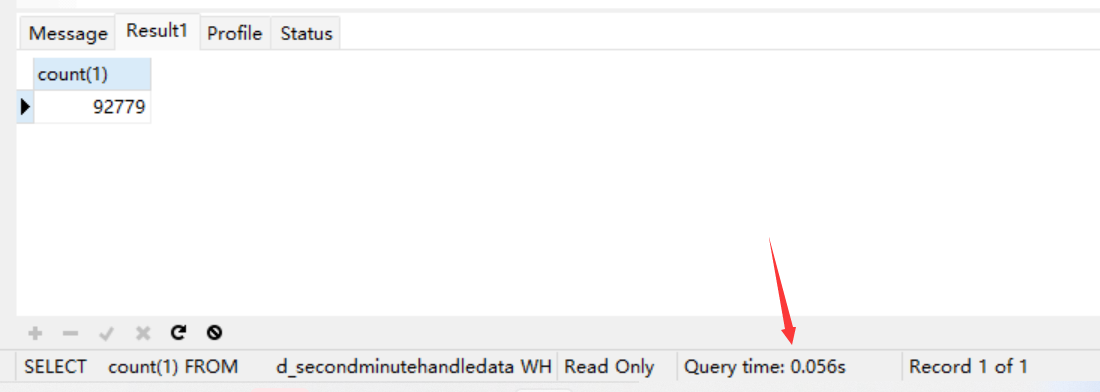
用到索引是非常快的
SELECT count(1) FROM d_secondminutehandledata WHERE stationBranchId = 533
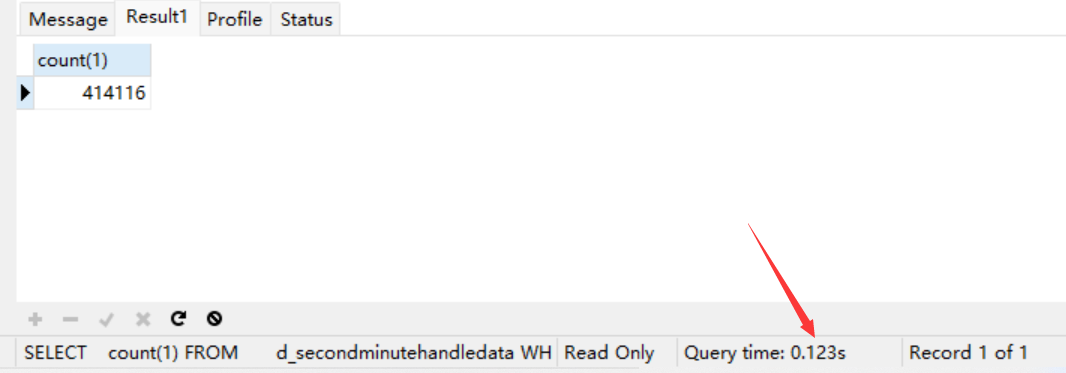
用到索引的第一个字段也是非常快的
SELECT collectionTime, stationBranchId, beforeBranchMeterAccHeat, beforeBranchMeterAccFlow, twoMeterAccHeat, twoSupplyAccFlow, mixingwaterAccHeat, mixingwaterAccFlow, oneBranchReplenishmentTankAccFlow, Data_FMeter_V1TO2SFlow, fillWaterAccFlow, oneBranchTotalElectricMeterElectricity, cyclePumpElectricMeterElectricity FROM d_secondminutehandledata WHERE stationBranchId = 533 AND collectionTime BETWEEN '2022-01-13' AND '2023-03-01' ORDER BY collectionTime DESC LIMIT 10000
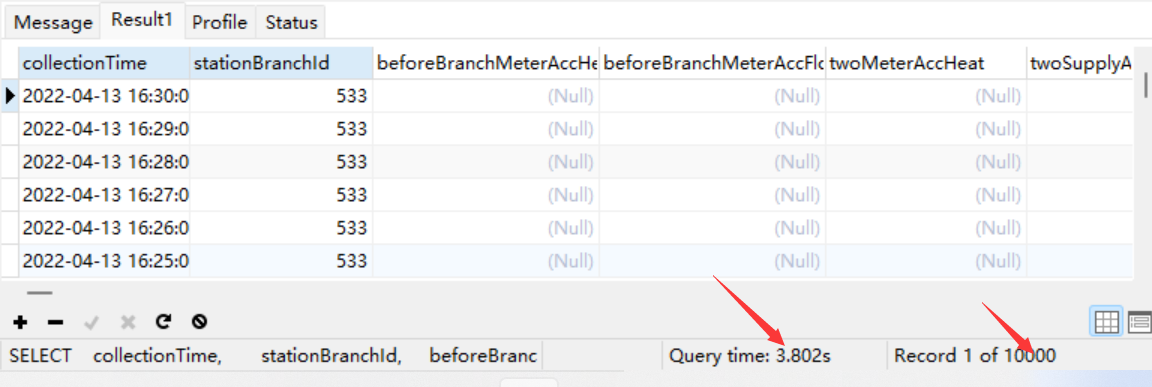
SELECT b.*, beforeBranchMeterAccHeat, beforeBranchMeterAccFlow, twoMeterAccHeat, twoSupplyAccFlow, mixingwaterAccHeat, mixingwaterAccFlow, oneBranchReplenishmentTankAccFlow, Data_FMeter_V1TO2SFlow, fillWaterAccFlow, oneBranchTotalElectricMeterElectricity, cyclePumpElectricMeterElectricity FROM d_secondminutehandledata a RIGHT JOIN ( SELECT collectionTime, stationBranchId FROM d_secondminutehandledata WHERE stationBranchId = 533 AND collectionTime BETWEEN '2022-01-13' AND '2023-03-01' ORDER BY collectionTime DESC LIMIT 10000 ) b ON a.stationBranchId = b.stationBranchId AND a.collectionTime = b.collectionTime
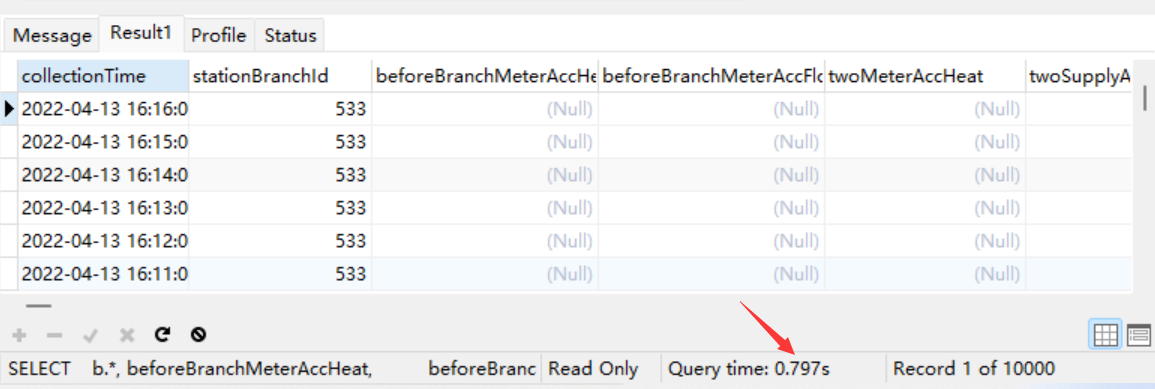
二次侧的数据查询好快
这就不对劲了,一次侧的数据量好像还要小一点的
SELECT count(1) FROM d_firstminutehandledata
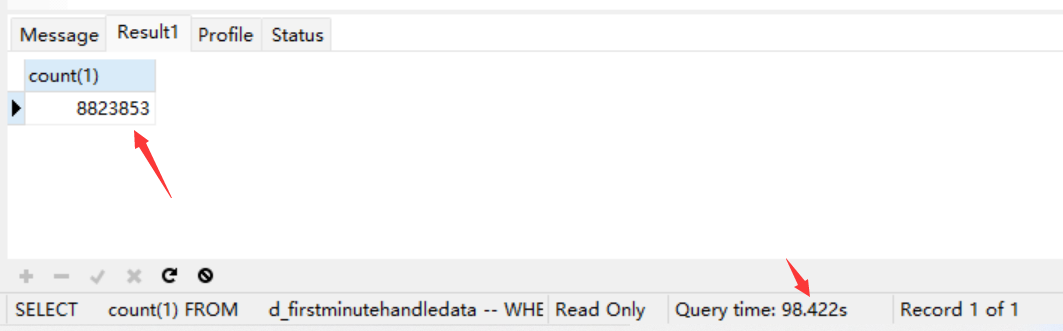
但是一次侧数据查询为啥这么慢?
难道是一次侧表的操作过于频繁?
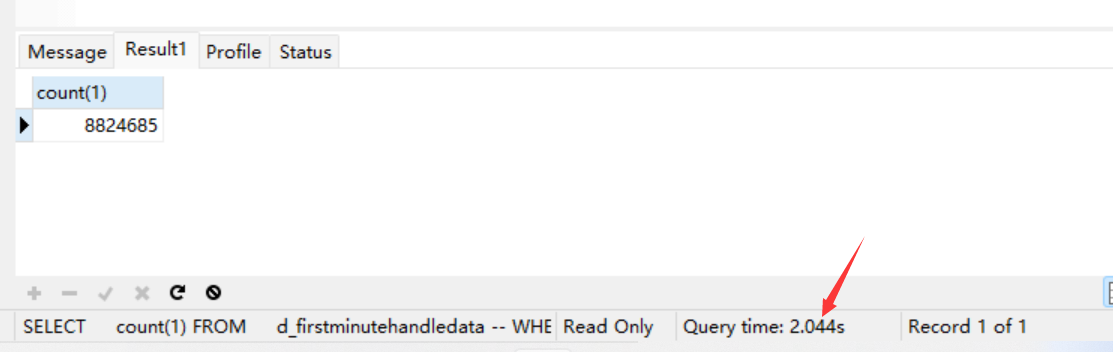
又试了一下,这下count快很多,难道是刚巧刚刚操作一次侧的表的代码减少了?