1.取出一个新闻列表页的全部新闻 包装成函数。
2.获取总的新闻篇数,算出新闻总页数。
3.获取全部新闻列表页的全部新闻详情。
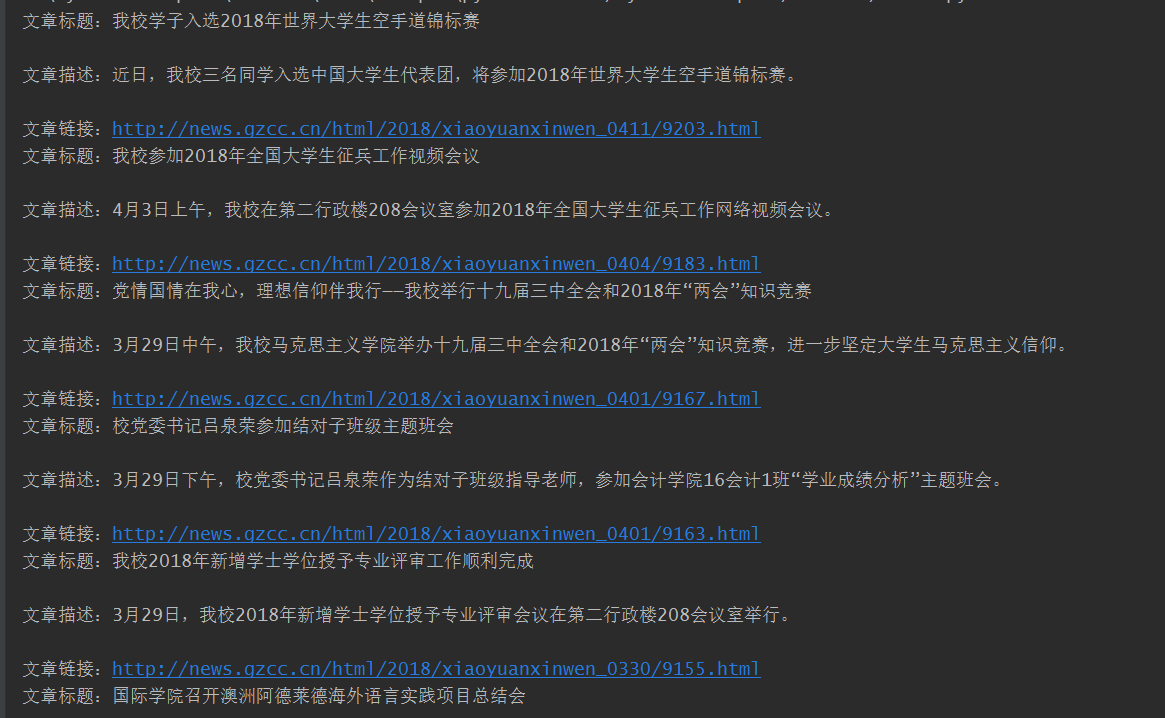
# -*- coding : UTF-8 -*- # -*- author : Kamchuen -*- import requests import re url = "http://news.gzcc.cn/html/xiaoyuanxinwen/" listnewurl = "http://news.gzcc.cn/html/xiaoyuanxinwen/index.html" res = requests.get(url) reslist = requests.get(listnewurl) res.encoding = 'utf-8' # 利用BeautifulSoup的HTML解析器,生成结构树 from bs4 import BeautifulSoup soup = BeautifulSoup(res.text, 'html.parser') soup_list = BeautifulSoup(reslist.text, 'html.parser') def getlistnew(listnewurl): # 获取全部简单的新闻 reslist = requests.get(listnewurl) reslist.encoding = 'utf-8' soup_list = BeautifulSoup(reslist.text, 'html.parser') tou = 'http://news.gzcc.cn/html/xiaoyuanxinwen/' shuzi = '' wei = '.html' for news in soup_list.select('li'): #首页 if len(news.select('.news-list-title')) > 0: # 首页文章标题 title = news.select('.news-list-title')[0].text # 首页文章描述 description = news.select('.news-list-description')[0].text # 首页文章链接 href = news.select('a')[0]['href'] print("文章标题:" + title) print(" 文章描述:" + description) print(" 文章链接:" + href) for i in range(2, 233): #首页外全部 shuzi = i; allnewurl='%s%s%s' % (tou, shuzi, wei) resalllist = requests.get(allnewurl) resalllist.encoding = 'utf-8' soup_alllist = BeautifulSoup(resalllist.text, 'html.parser') for news in soup_alllist.select('li'): if len(news.select('.news-list-title')) > 0: # 首页文章标题 title = news.select('.news-list-title')[0].text # 首页文章描述 description = news.select('.news-list-description')[0].text # 首页文章链接 href = news.select('a')[0]['href'] print("文章标题:" + title) print(" 文章描述:" + description) print(" 文章链接:" + href) def getClickCount(url): HitUrl = 'http://oa.gzcc.cn/api.php?op=count&id=9183&modelid=80' hitNumber = requests.get(HitUrl).text.split('.html')[-1].lstrip("('").rstrip("');") print("点击次数:", hitNumber) re.match('http://news.gzcc.cn/html/2018/xiaoyuanxinwen(.*).html', url).group(1).split('/')[1] print('新闻编号:', re.search('\_(.*).html', url).group(1)) def getNewDetail(url): # 获取首页的详细新闻 res = requests.get(url) res.encoding = 'utf-8' soup = BeautifulSoup(res.text, 'html.parser') for news in soup.select('li'): if len(news.select('.news-list-title')) > 0: # 首页文章标题 title = news.select('.news-list-title')[0].text # 首页文章描述 description = news.select('.news-list-description')[0].text # 首页文章信息 info = news.select('.news-list-info')[0].text # 首页文章链接 href = news.select('a')[0]['href'] url = href res = requests.get(url) res.encoding = 'utf-8' soup = BeautifulSoup(res.text, 'html.parser') # 获取每篇文章的信息 newinfo = soup.select('.show-info')[0].text # 获取文章内容 content = soup.select('#content')[0].text # 日期 date = newinfo.split()[0] # 当日时间 time = newinfo.split()[1] # 作者 author = newinfo.split()[2] # 审核 checker = newinfo.split()[3] # 来源 source = newinfo.split()[4] # 摄影 Photography = newinfo.split()[5] print("文章标题:" + title) print(" 文章描述:" + description) print(" 文章信息: " + date + ' ' + time + ' ' + author + ' ' + checker + ' ' + source + ' ' + Photography) getClickCount(href) # 点击次数、新闻编号 print(" 文章链接:" + href) print(content) getlistnew(listnewurl) # 获取全部的新闻
截图:
4.找一个自己感兴趣的主题,进行数据爬取,并进行分词分析。不能与其它同学雷同。
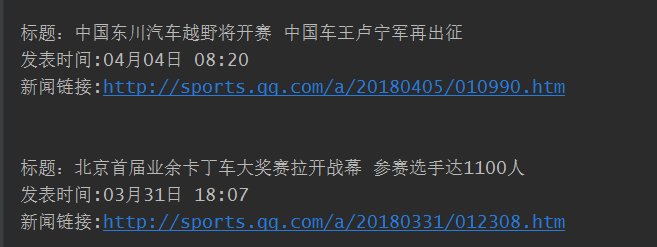
腾讯的中国赛车新闻网
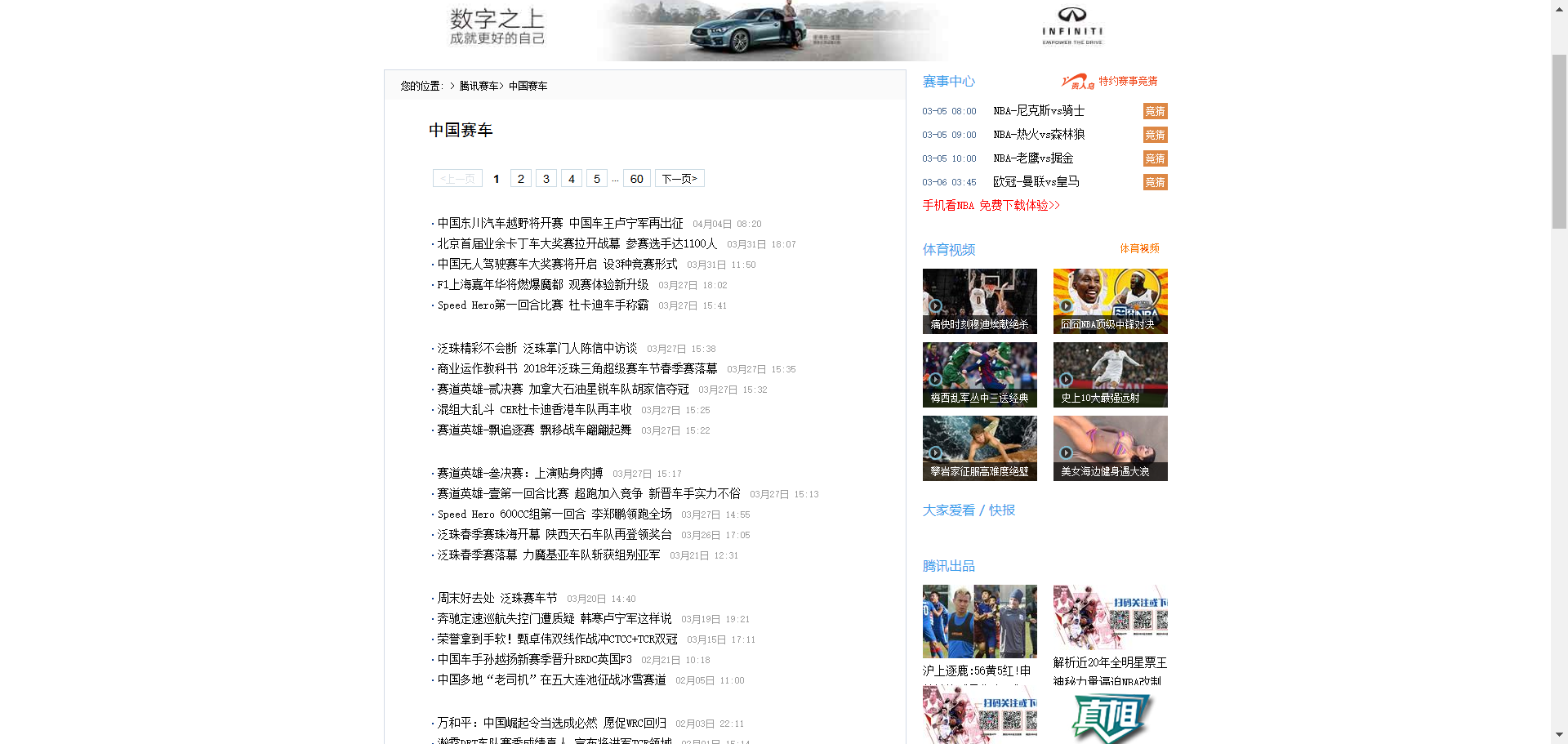
# -*- coding : UTF-8 -*- # -*- author : Kamchuen -*- import requests from bs4 import BeautifulSoup import jieba def getnewsdetail(NewsUrl): resd = requests.get(NewsUrl) resd.encoding = 'gbk' soupd = BeautifulSoup(resd.text, 'html.parser') total = len(soupd.select(".text")) content = '' for p in range(0, total): content += soupd.select('.text')[p].text + ' ' print(content + " 词频统计如下:") delword = ['了', '那', '-', '的', '是', '这', '在', '也', '都', '而','被', ' ', ',', '。', '?', '!', '“', '”', ':', ';', '、', '.', '‘', '’', '(', ')', ' ', '【', '】', '…'] wordDict = {} newscontent = list(jieba.cut(content)) wordset = set(newscontent) - set(delword) for i in wordset: wordDict[i] = newscontent.count(i) sort = sorted(wordDict.items(), key=lambda item: item[1], reverse=True) for i in range(10): print(sort[i]) def getnewslist(newsurl): res = requests.get(newsurl) res.encoding = 'gbk' soup = BeautifulSoup(res.text, 'html.parser') for newsList in soup.select('.newslist')[0].select('li'): title = newsList.select('a')[0].text datetime = newsList.select('.pub_time')[0].text address = newsList.select('a')[0]['href'] print(' 标题:{0} 发表时间:{1} 新闻链接:{2} '.format(title, datetime, address)) getnewsdetail(address) Url = "http://sports.qq.com/l/f1/allchinesenews/list20100311182947.htm" getnewslist(Url) for i in range(1, 183): if (i == 1): getnewslist(Url) else: NewsUrl = "http://sports.qq.com/l/f1/allchinesenews/list20100311182947_{}.htm".format(i) getnewslist(NewsUrl)
截图: