[acmi 2015]Image based Static Facial Expression Recognition with Multiple Deep Network Learning
ABSTRACT
该文章作者为EmotiW2015比赛静态表情识别的亚军,采用的方法为cnn的级联,人脸检测方面也采用了当时3种算法的共同检测,
通过在FER2013数据库上进行模型预训练,并在SFEW2.0(比赛数据)上fine-tune,从而在比赛的验证集和测试集上取得55.96%和61.29%
的准确率,远远超过比赛的baseline(35.96%,39.13%)。
作者本文主要贡献如下:
- 1.实现了CNN架构,在表情识别方面性能卓越。
- 2.提出了一种数据增强和投票模式,应有提高CNN的性能。
- 3.提出了一种优化方法自动的决定级联CNN的权重分配问题。
FaceDetection
由于SFEW数据库给出的静态图像,背景非常复杂,同时为了后续的CNN表情分类,人脸的检测与对齐是非常重要的,因此作者级联了三个state-of-the-art
的人脸检测算法,从而保证人脸检测的正确性.三种检测算法为(JDA,DCNN,MoT),图像事先resize为1024x576.总共帧为372,实验结果如下表所示:
| Method | JDA | DCNN | MoT | JDA+DCNN | JDA+DCNN+MoT |
|---|---|---|---|---|---|
| Det # | 333 | 358 | 352 | 363 | 371 |
FacePreprocessing
数据预处理对后续的识别有极大的影响,良好的数据预处理可以去除样本间的无关噪声,并能够一定程度的做到数据增强。图像尺寸归一化(48x48)
直方图均衡化,去均值除方差。
样本扩增(论文5.2),由于FER数据库包含35000+的图片,因此作者采用fer数据库进行预训练,作者对数据进行了随机的旋转,从而生成了更多的样本,使得网络训练的结果更具有鲁棒性。,样本生成公式以及效果图如下图所示:
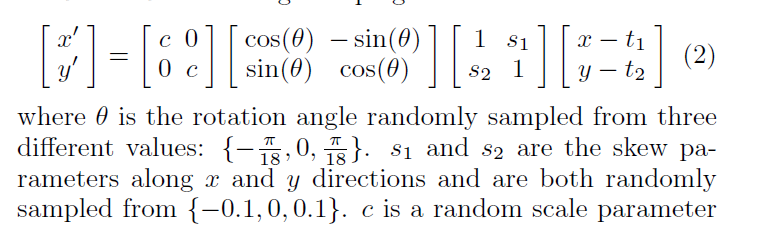


CNNModel
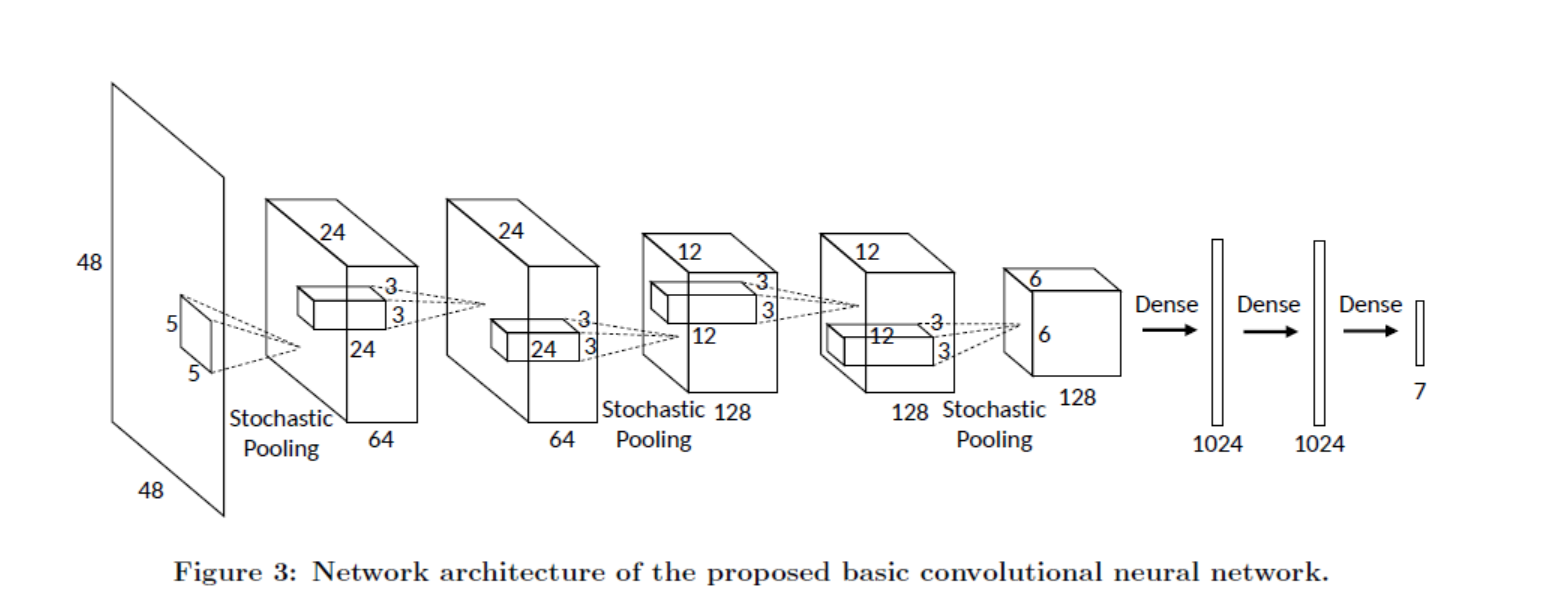
基本网络结构
5个conv+relu(step:1),3个stochastic pooling层(kernel_size:3*3,step:2),3个全连接层次(带relu+dropout)+softmax,随机初始化参数.
采用sgd优化方式,batch_size:128.

损失函数与级联思想
损失函数为softmaxWithLoss,只不过计算的时候一个样本会与其生成的样本loss一起计算,整个网络用FER数据库进行预训练(base_lr:0.005),当loss突然增加25%或者连续5次观察loss发现loss上升,则手动的减小学习率,最小的学习率设置为0.0001.
由于随机初始化参数,因此作者测试的时候,对多个网络进行级联,从而提高测试的准确率.
相比较简单的加权投票平均的思想,作者认为可以通过学习策略,来决定网络的具体权重。所以提出了一个级联的似然函数,实际可以理解为根据各个网络的输出去学习一个全连接层.其中||w|| == 1.
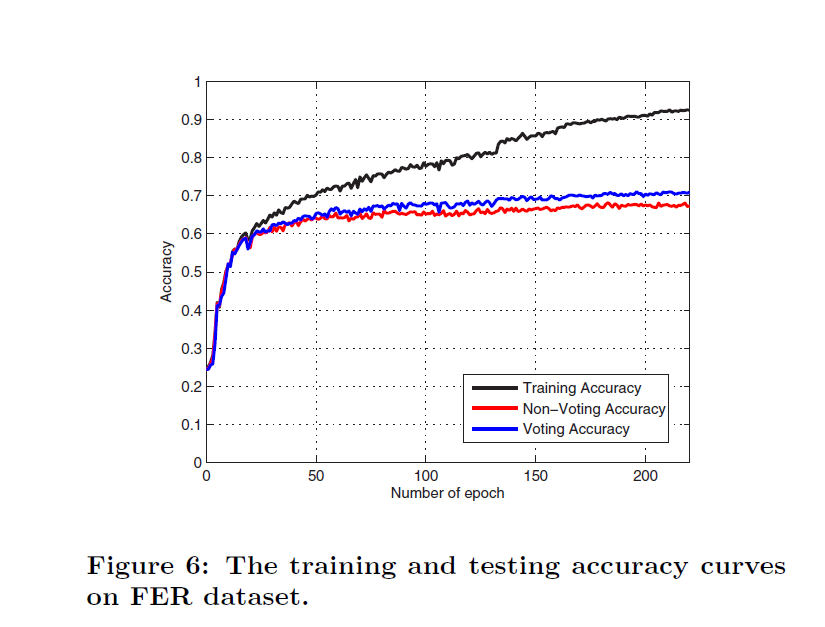
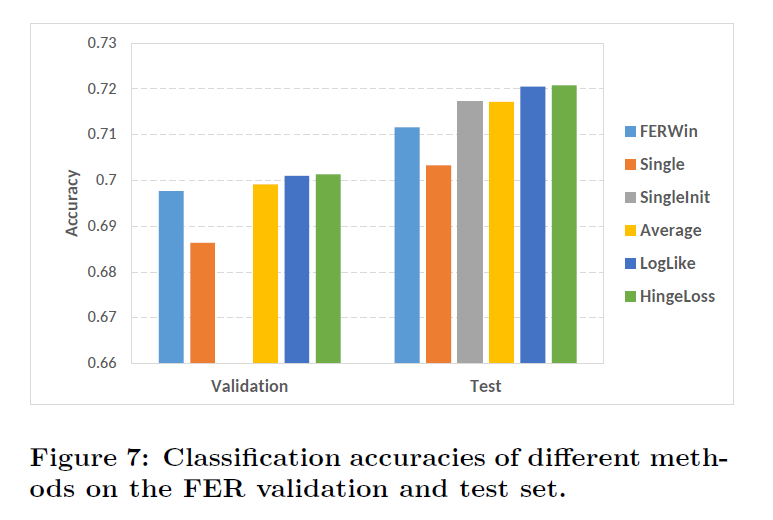
实验结果
作者分别列出了在FER,SFEW上数据库的单独训练结果以及,采用提升的级联方式对最终结果的提高。

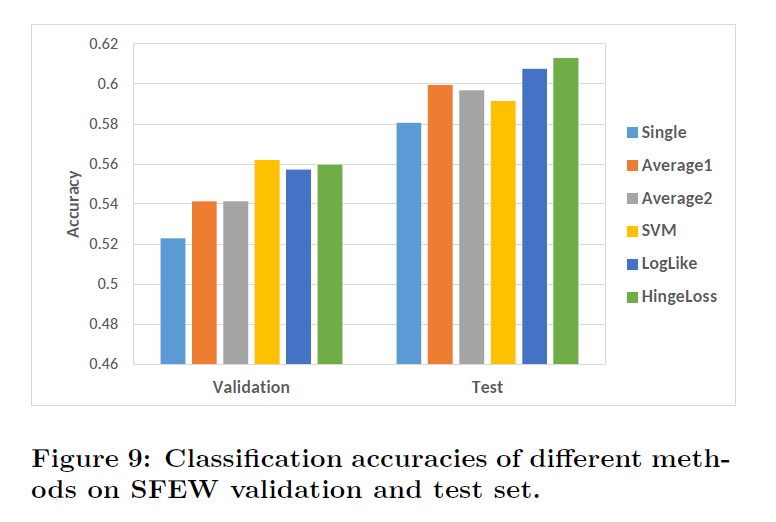
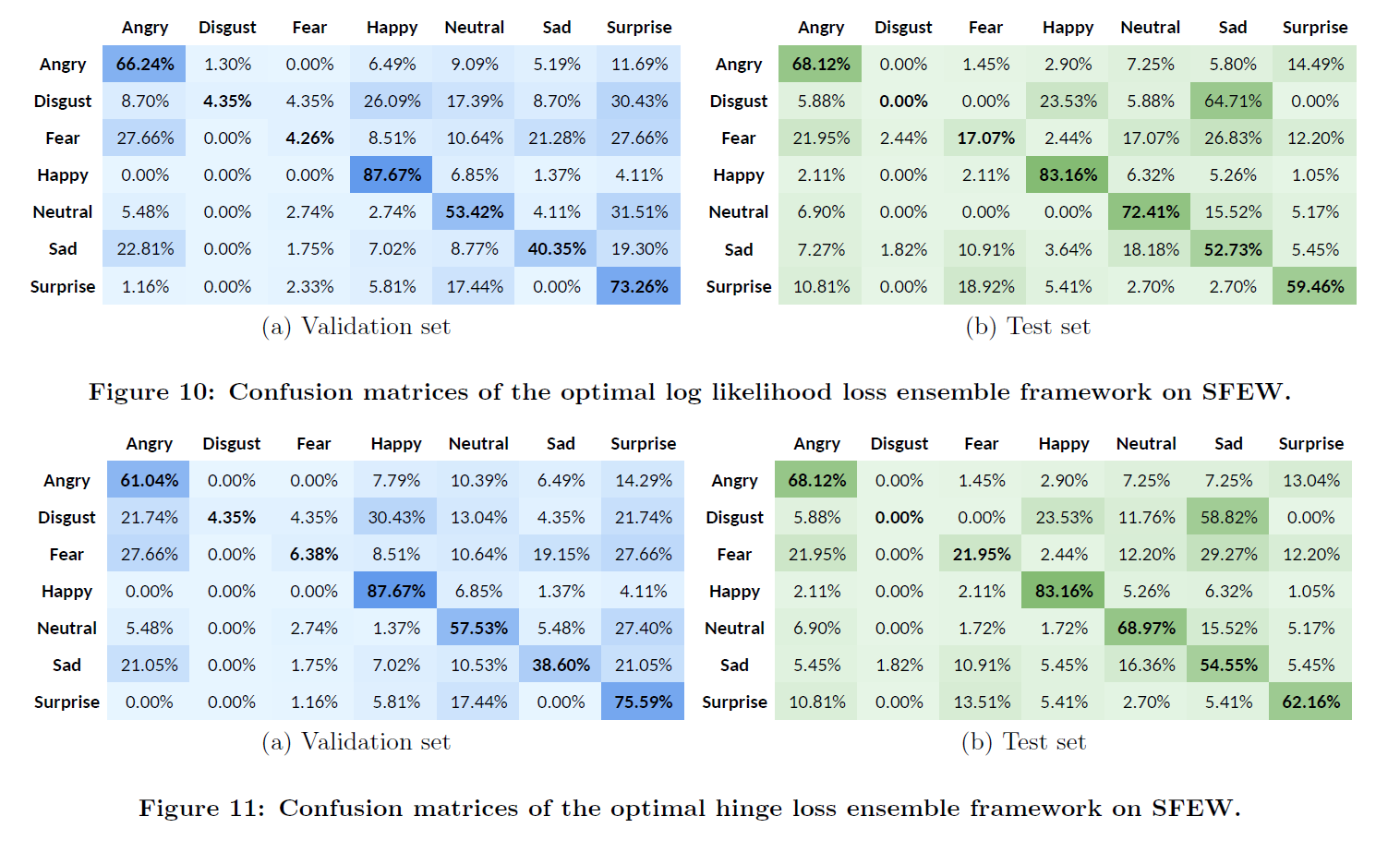
结论
预训练+提升的级联方式对最终的识别效果有效。同时,样本扩增对实验提升也是有作用的。
本文作者: 张峰
本文链接: http://www.enjoyai.site/2018/01/08/
版权声明: 本博客所有文章,均采用 CC BY-NC-SA 3.0 许可协议。转载请注明出处!