1.为什么大数据高并发要用Redis
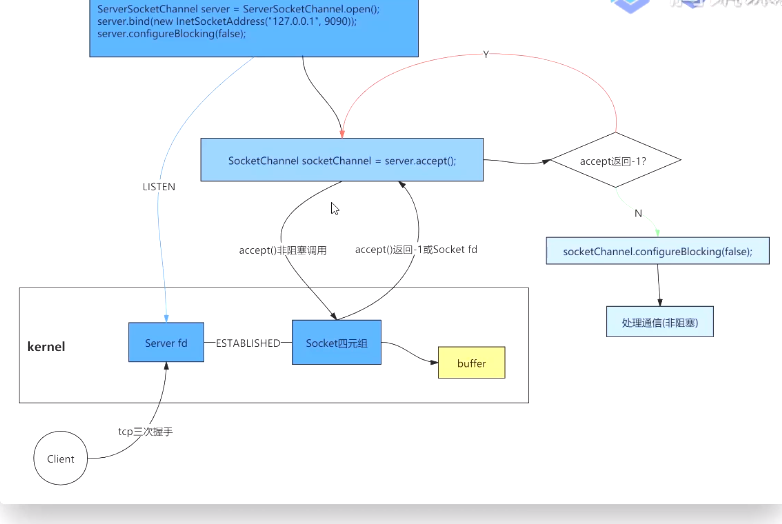
平常的客户端 请求mysql等数据库 需要socket四元件
第一慢:需要进行IO操作,无序的读取or插入
第二慢:在第一慢的基础上,连接数据库(每次只能请求和处理1个请求,而这个请求是阻塞的),请求超时,就不能进行高并发
就像买票排队,人超出食堂门口,就处理不了
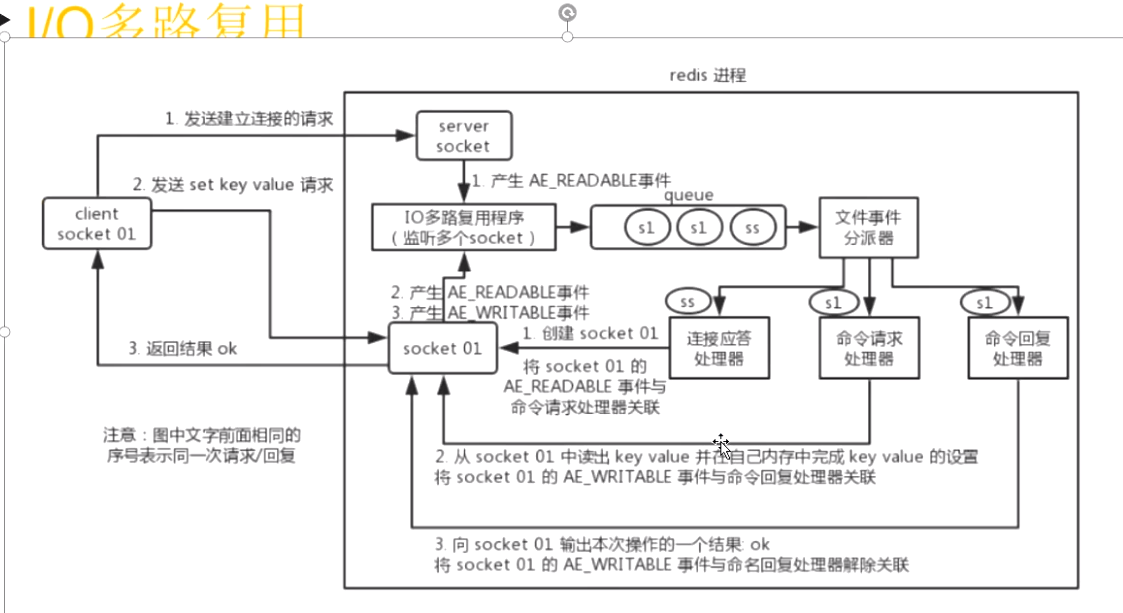
而redis把第一慢io操作变成内存操作,数据存储内存中第二慢:连接队列超时问题-通过Io多路复用
所以redi解决了两个大问题:1.直接操作内存,2.解决Io阻塞,通过多路复用,由系统帮你监听链接,只要有事件处理,系统调redis的回调函数,把监听事件交给了系统,释放了我们的代码
所以:redis的异步多线程是由系统完成的,而普通的异步IO是自己写程序调用的。
多路复用是操作系统提供的, reidis能使用Linux是因为用C语言写的,而.net底层里面并没有调用Linux的多路复用代码API
服务端在等待连接和等待请求的时候,不能进行任务操作(BIO阻塞)
NIO(异步的IO) 如果没有请求,就去干自己的事情,下一次请求看有没有你做的事情
.net 同步socket 如果没有任务 直接阻塞当前线程
.net 异步socket 只不过把之前等待的事情,交给了其他线程
redis:IO多路复用-基于liunx系统-生产环境中一定要安装在liunx
redisI/0多路复用如图,多个客户端过来直接把请求交给内核,不用写什么java,.net代码

liunx同时间可以有6w多个客户端(链接) 但是windos系统下面的redis最多监听1024个链接
所以redis在windos使用的系统调用模型是 select redis在liunx中使用的是Epoll 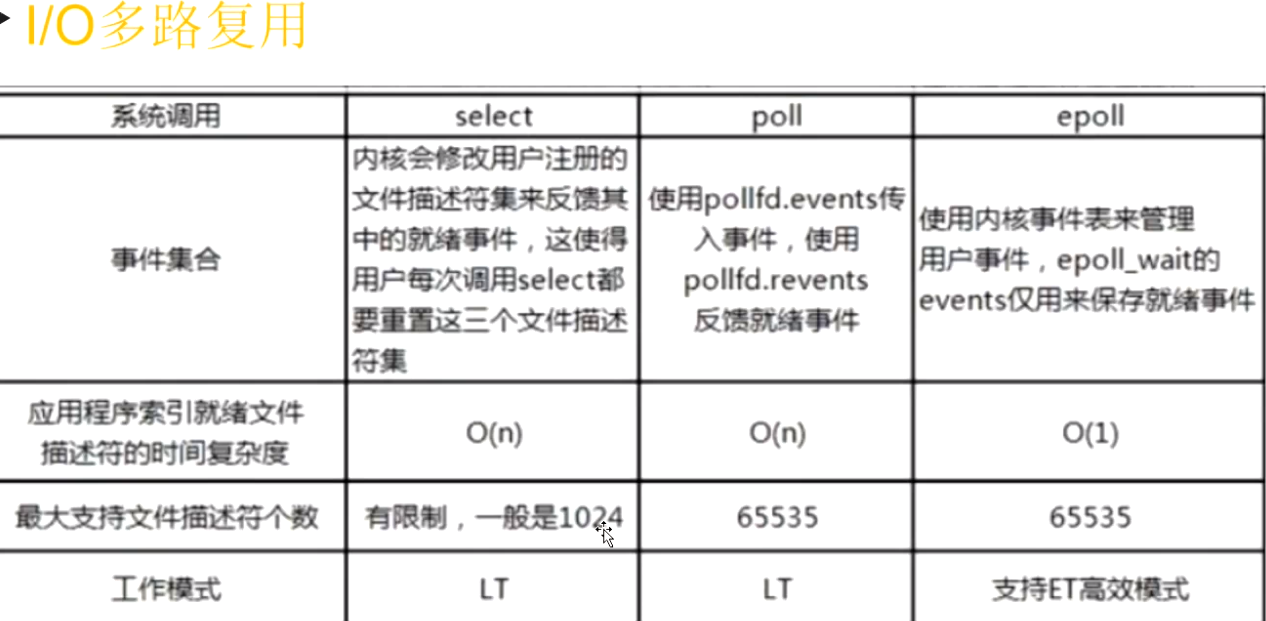
多路复用:就是把监听和阻塞等待是否有请求进来的事情交给系统内核处理而系统直接开启高速通道处理
以下是执行流程