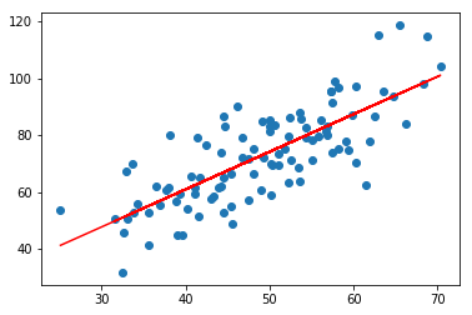
监督学习 —— 回归模型
- 线性回归模型
- 线性回归(linear regression)是一种线性模型,它假设输入变量x 和单个输出变量y之间存在线性关系
- 具体来说,利用线性回归模型,可以从一组输入变量X的线性组合中, 计算输出变量y
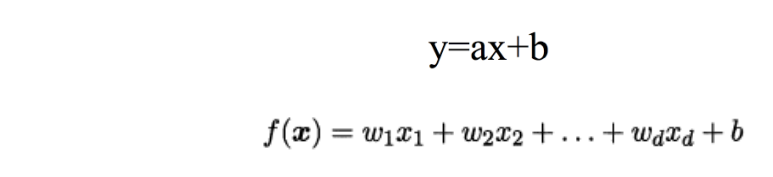
线性方程求解
假设我们有一个如下的二元一次方程:
y = ax + b
我们已知两组数据: x = l时,y = 3,即(1,3)
x = 2 时,y = 5,即(2,5)
将数据输入方程中,可得:
a + b = 3
2a + b = 5
解得: a = 2, b = 1
即方程为: 2x + 1 = y
当我们有任意一个x时,输入方程,就可以得到对应的y
例如x=5时,y = 11。
线性回归模型

• 给定有d个属性(特征)描述的示例x=(x1;x2;…;xd),其中 xi 是 x 在第 i 个属性(特征)上的取值,
线性模型(linear model)试图学得一个通过 属性(特征)的线性组合来进行预测的函数,即:

• —般用向量形式写成:
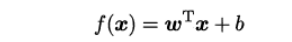
![]()
• 假设特征和结果都满足线性,即不大于一次方。
• w和b学得之后,模型就得以确定。
• 许多功能更为强大的非线性模型可在线性模型的基础上通过引入层级结构 或高维映射而得。
最小二乘法
• 基于均方误差最小化来进行模型求解的方法称为“最小二乘法” (least square method)
• 它的主要思想就是选择未知参数使得理论值与观测值之差的平方和达到最小。
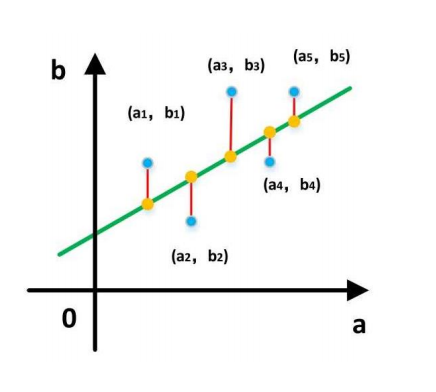
- 我们假设输入属性(特征)的数目只有一个:

- 在线性回归中,最小二乘法就是试图找到一条直线,使所有样本到 直线上的欧式距离之和最小。

• 求解w和b,使得 ![]() 最小化的过程,称为线性回归 模型的“最小二乘参数估计”
最小化的过程,称为线性回归 模型的“最小二乘参数估计”
• 将![]() 分别对w和b求导,可以得到
分别对w和b求导,可以得到
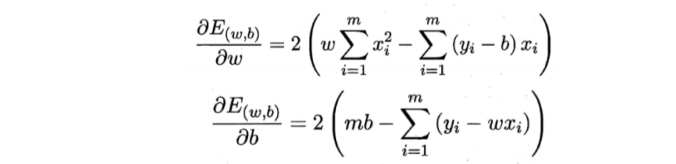
• 令偏导数都为0,可以得到

——其中:
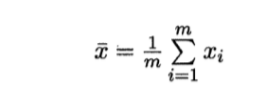
代码实现:
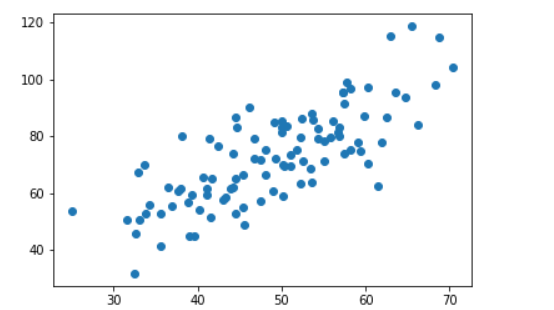
0.引入依赖 import numpy as np import matplotlib.pyplot as plt 1.导入数据(data.csv) points = np.genfromtxt("data.csv", delimiter=",") #points # 提取 points 中的两列数据,分别作为 x,y x = points[:, 0] y = points[:, 1] # 用 plt 画出散点图 plt.scatter(x, y) plt.show()
2.定义损失函数 # 损失函数是系数的函数 def compute_cost(w, b, points): total_cost = 0 M = len(points) # 逐点计算平方损失误差,然而求平均数 for i in range(M): x = points[i, 0] y = points[i, 1] total_cost += ( y - w * x - b ) ** 2 return total_cost/M 3.定义核心算法拟合函数 # 先定义一个求平均值的函数 def average(data): sum = 0 num = len(data) for i in range(num): sum += data[i] return sum/num # 定义核心拟合函数 def fit(points): M = len(points) x_bar = average(points[:, 0]) sum_yx = 0 sum_x2 = 0 sum_delta = 0 for i in range(M): x = points[i, 0] y = points[i, 1] sum_yx += y * (x - x_bar) sum_x2 += x ** 2 # 根据公式计算 W w = sum_yx / (sum_x2 - M * (x_bar**2)) for i in range(M): x = points[i, 0] y = points[i, 1] sum_delta += (y - w * x) b = sum_delta / M return w, b 4.测试 w, b = fit(points) print("w is:", w) print("b is:", b) cost = compute_cost(w, b, points) print("cost is:", cost)

5.画出拟合曲线 plt.scatter(x, y) # 针对每一个 x,计算出预测的 y 值 pred_y = w * x + b plt.plot(x, pred_y, c='r') plt.show()
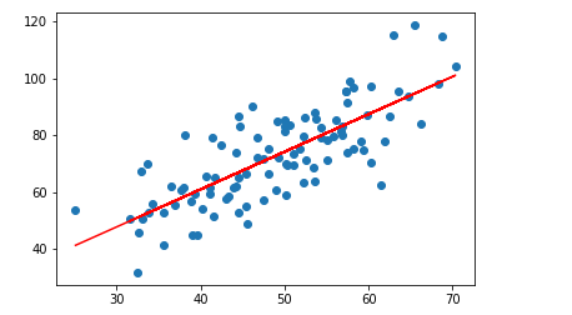
多元线性回归
- 如果有两个或两个以上的自变量,这样的线性回归分析就称为多元线 性回归
- 实际问题中,一个现象往往是受多个因素影响的,所以多元线性回归 比一元线性回归的实际应用更广

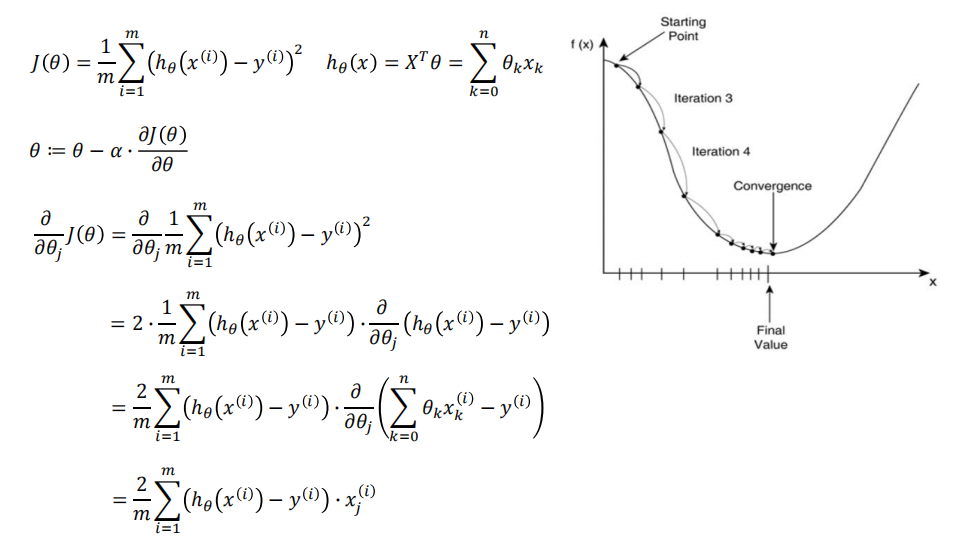
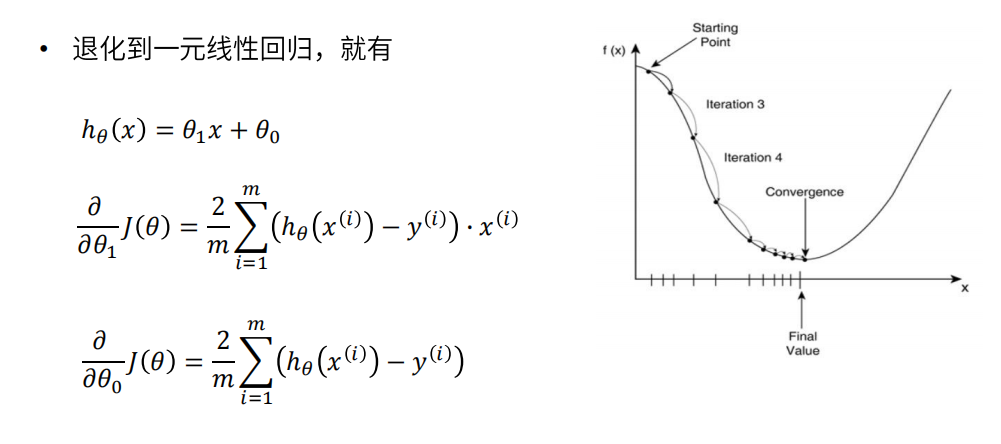
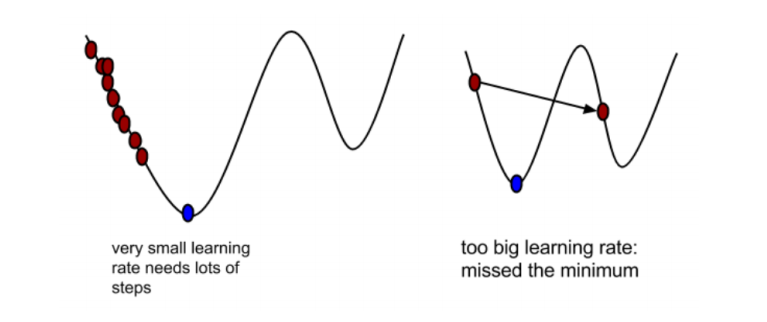
• a在梯度下降算法中被称作为学习率或者步长
• 这意味着我们可以通过a来控制每一步走的距离,以保证不要走太快,错 过了最低点;
同时也要保证收敛速度不要太慢
• 所以a的选择在梯度下降法中往往是很重要的,不能太大也不能太小
代码实现:
简单线性回归(梯度下降法) 0.引入依赖 import numpy as np import matplotlib.pyplot as plt 1.导入数据(data.csv) points = np.genfromtxt("data.csv", delimiter=",") #points # 提取 points 中的两列数据,分别作为 x,y x = points[:, 0] y = points[:, 1] # 用 plt 画出散点图 plt.scatter(x, y) plt.show()
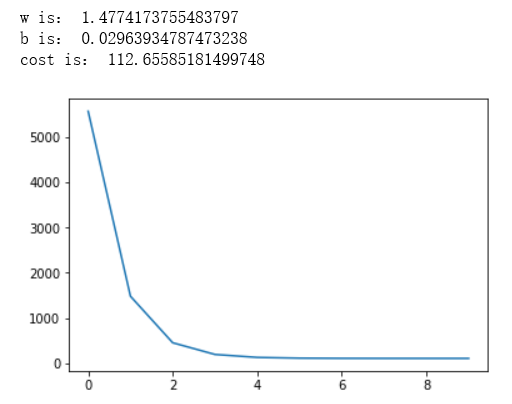
2.定义损失函数 # 损失函数是系数的函数 def compute_cost(w, b, points): total_cost = 0 M = len(points) # 逐点计算平方损失误差,然而求平均数 for i in range(M): x = points[i, 0] y = points[i, 1] total_cost += ( y - w * x - b ) ** 2 return total_cost/M 3.定义模型的超参数 alpha = 0.0001 initial_w = 0 initial_b = 0 num_iter = 10 4.定义核心梯度下降算法函数 def grad_desc(points, initial_b, initial_w, alpha, num_iter): w = initial_w b = initial_b # 定义一个列表保存所有的损失函数值,用来显示下降的过程 cost_list = [] for i in range(num_iter): cost_list.append(compute_cost(w, b, points)) w, b = step_grad_desc(w, b, alpha, points) return [w, b, cost_list] def step_grad_desc(current_w, current_b, alpha, points): sum_grad_w = 0 sum_grad_b = 0 M = len(points) # 对每个点,带入公式求和 for i in range(M): x = points[i, 0] y = points[i, 1] sum_grad_w += (current_w * x + current_b - y) * x sum_grad_b += current_w * x + current_b - y # 用公式求当前梯度 grad_w = 2/M * sum_grad_w grad_b = 2/M * sum_grad_b # 梯度下降,更新当前的 w 和 b updated_w = current_w - alpha * grad_w updated_b = current_b - alpha * grad_b return updated_w, updated_b 5.测试:运行梯度下降算法计算最优的 w 和 b w, b, cost_list = grad_desc(points, initial_b, initial_w, alpha, num_iter) print("w is:", w) print("b is:", b) cost = compute_cost(w, b, points) print("cost is:", cost) plt.plot(cost_list) plt.show()
6.画出拟合曲线 plt.scatter(x, y) # 针对每一个 x,计算出预测的 y 值 pred_y = w * x + b plt.plot(x, pred_y, c='r') plt.show()

梯度下降法和最小二乘法
• 相同点
- 本质和目标相同:两种方法都是经典的学习算法,在给定已知数据的前提下利用求导算
出一个模型(函数),使得损失函数最小,然后对给定的新数据进行估算预测
• 不同点
- 损失函数:梯度下降可以选取其它损失函数,而最小二乘一定是平方损失函数
- 实现方法:最小二乘法是直接求导找出全局最小;而梯度下降是一种迭代法
- 效果:最小二乘找到的一定是全局最小,但计算繁琐,且复杂情况下未必有解;
梯度下 降迭代计算简单,但找到的一般是局部最小,只有在目标函数是凸函数时才是全局最小;
到最小点附近时收敛速度会变慢,且对初始点的选择极为敏感
Python 自带线性回归库(sklearn)(最小二乘法):
import numpy as np import matplotlib.pyplot as plt points = np.genfromtxt("data.csv", delimiter=",") #points # 提取 points 中的两列数据,分别作为 x,y x = points[:, 0] y = points[:, 1] # 用 plt 画出散点图 plt.scatter(x, y) plt.show()
# 损失函数是系数的函数 def compute_cost(w, b, points): total_cost = 0 M = len(points) # 逐点计算平方损失误差,然而求平均数 for i in range(M): x = points[i, 0] y = points[i, 1] total_cost += ( y - w * x - b ) ** 2 return total_cost/M from sklearn.linear_model import LinearRegression lr = LinearRegression() x_new = x.reshape(-1, 1) y_new = y.reshape(-1, 1) lr.fit(x_new, y_new)
# 从训练好的模型中提取系数和截距 w = lr.coef_ b = lr.intercept_ print("w is:", w) print("b is:", b) cost = compute_cost(w, b, points) print("cost is:", cost)

w = w[0][0] b = b[0] plt.scatter(x, y) # 针对每一个 x,计算出预测的 y 值 pred_y = w * x + b plt.plot(x, pred_y, c='r') plt.show()