5.Flink DataStream API
5.1 Flink 运行模型
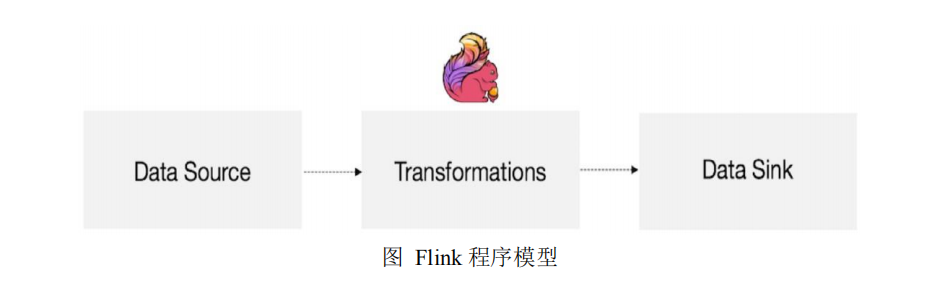
以上为 Flink 的运行模型,Flink 的程序主要由三部分构成,分别为 Source、
Transformation、Sink。DataSource 主要负责数据的读取,Transformation 主要负责对
属于的转换操作,Sink 负责最终数据的输出。
5.2 Flink 程序架构
每个 Flink 程序都包含以下的若干流程:
获得一个执行环境;(Execution Environment)
加载/创建初始数据;(Source)
指定转换这些数据;(Transformation)
指定放置计算结果的位置;(Sink)
触发程序执行。
以下在 idea 中 测试:
导入依赖:
<?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion> <groupId>com.atlxl</groupId> <artifactId>flink_class</artifactId> <version>1.0-SNAPSHOT</version> <dependencies> <dependency> <groupId>org.scala-lang</groupId> <artifactId>scala-library</artifactId> <version>2.11.8</version> </dependency> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-core</artifactId> <version>1.6.1</version> </dependency> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-clients_2.11</artifactId> <version>1.6.1</version> </dependency> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-scala_2.11</artifactId> <version>1.6.1</version> </dependency> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-streaming-scala_2.11</artifactId> <version>1.6.1</version> </dependency> <dependency> <groupId>commons-io</groupId> <artifactId>commons-io</artifactId> <version>2.1</version> </dependency> </dependencies> </project>
5.3 Environment
执行环境 StreamExecutionEnvironment 是所有 Flink 程序的基础。
创建执行环境有三种方式,分别为:
StreamExecutionEnvironment.getExecutionEnvironment
StreamExecutionEnvironment.createLocalEnvironment
StreamExecutionEnvironment.createRemoteEnvironment
5.3.1 StreamExecutionEnvironment.getExecutionEnvironment
创建一个执行环境,表示当前执行程序的上下文。 如果程序是独立调用的,则
此方法返回本地执行环境;如果从命令行客户端调用程序以提交到集群,则此方法
返回此集群的执行环境,也就是说,getExecutionEnvironment 会根据查询运行的方
式决定返回什么样的运行环境,是最常用的一种创建执行环境的方式。
val env = StreamExecutionEnvironment.getExecutionEnvironment
5.3.2 StreamExecutionEnvironment.createLocalEnvironment
返回本地执行环境,需要在调用时指定默认的并行度。
val env = StreamExecutionEnvironment.createLocalEnvironment(1)
5.3.3 StreamExecutionEnvironment.createRemoteEnvironment
返回集群执行环境,将 Jar 提交到远程服务器。需要在调用时指定 JobManager
的 IP 和端口号,并指定要在集群中运行的 Jar 包。
val env = StreamExecutionEnvironment.createRemoteEnvironment(1)
5.4 Source
5.4.1 基于 File 的数据源
1. readTextFile(path)
一列一列的读取遵循 TextInputFormat 规范的文本文件,并将结果作为 String 返回。
val env = StreamExecutionEnvironment.getExecutionEnvironment val stream = env.readTextFile("/opt/modules/test.txt") stream.print() env.execute("FirstJob")
注意:stream.print():每一行前面的数字代表这一行是哪一个并行线程输出的。
2. readFile(fileInputFormat, path)
按照指定的文件格式读取文件。
val env = StreamExecutionEnvironment.getExecutionEnvironment val path = new Path("/opt/modules/test.txt") val stream = env.readFile(new TextInputFormat(path), "/opt/modules/test.txt") stream.print() env.execute("FirstJob")
5.4.2 基于 Socket 的数据源
1. socketTextStream
从 Socket 中读取信息,元素可以用分隔符分开。
先在 windows 下开启 netcat 服务
安装教程:
开启一个端口:
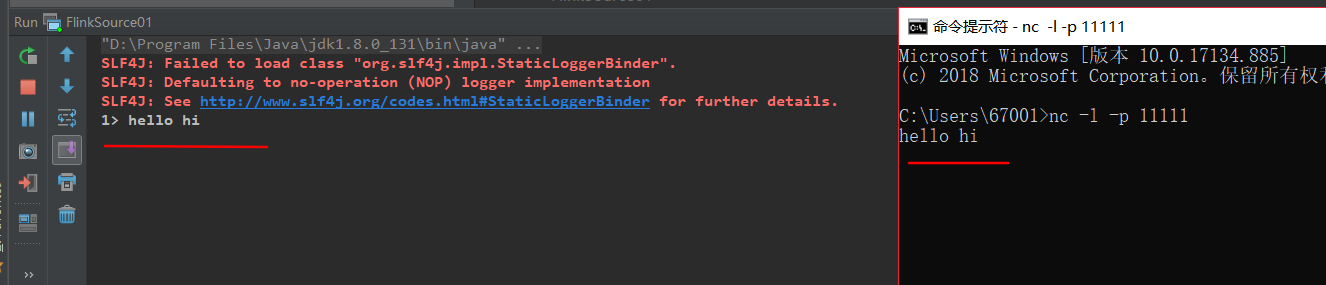
val env = StreamExecutionEnvironment.getExecutionEnvironment val stream = env.socketTextStream("localhost", 11111) stream.print() env.execute("FirstJob")
5.4.3 基于集合(Collection)的数据源
1. fromCollection(seq)
从集合中创建一个数据流,集合中所有元素的类型是一致的。
val env = StreamExecutionEnvironment.getExecutionEnvironment val list = List(1,2,3,4) val stream = env.fromCollection(list) stream.print() env.execute("FirstJob")
2. fromCollection(Iterator)
从迭代(Iterator)中创建一个数据流,指定元素数据类型的类由 iterator 返回。
val env = StreamExecutionEnvironment.getExecutionEnvironment val iterator = Iterator(1,2,3,4) val stream = env.fromCollection(iterator) stream.print() env.execute("FirstJob")
3. fromElements(elements:_*)
从一个给定的对象序列中创建一个数据流,所有的对象必须是相同类型的。
val env = StreamExecutionEnvironment.getExecutionEnvironment val list = List(1,2,3,4) val stream = env.fromElement(list) stream.print() env.execute("FirstJob")
4. generateSequence(from, to)
从给定的间隔中并行地产生一个数字序列。
val env = StreamExecutionEnvironment.getExecutionEnvironment val stream = env.generateSequence(1,10) stream.print() env.execute("FirstJob")
测试代码:
package source import org.apache.flink.streaming.api.scala._ object FlinkSource01 { def main(args: Array[String]): Unit = { //1. 创建环境 val env = StreamExecutionEnvironment.getExecutionEnvironment // //2. 获取数据源(Source) // val stream = env.readTextFile("test00.txt") // //基于 Socket 获取数据源 // val stream = env.socketTextStream("localhost", 11111) // //基于集合(Collection)的数据源 // val list = List(1,2,3,4) // val stream = env.fromCollection(list) fromCollection(seq) // val iterator = Iterator(1,2,3,4) // val stream = env.fromCollection(iterator) //fromCollection(Iterator) val stream = env.generateSequence(1,10) //generateSequence(from, to) //3. 打印数据(Sink) stream.print() //4. 执行任务 env.execute("FristJob") } }
5.5 Sink
Data Sink 消费 DataStream 中的数据,并将它们转发到文件、套接字、外部系
统或者打印出。
Flink 有许多封装在 DataStream 操作里的内置输出格式。
5.6.1 writeAsText
将元素以字符串形式逐行写入(TextOutputFormat),这些字符串通过调用每个
元素的 toString()方法来获取。
5.6.2 WriteAsCsv
将元组以逗号分隔写入文件中(CsvOutputFormat),行及字段之间的分隔是可
配置的。每个字段的值来自对象的 toString()方法。
5.6.3 print/printToErr
打印每个元素的 toString()方法的值到标准输出或者标准错误输出流中。或者也
可以在输出流中添加一个前缀,这个可以帮助区分不同的打印调用,如果并行度大
于 1,那么输出也会有一个标识由哪个任务产生的标志。
5.6.4 writeUsingOutputFormat
自定义文件输出的方法和基类(FileOutputFormat),支持自定义对象到字节的转换。
5.6.5 writeToSocket
根据 SerializationSchema 将元素写入到 socket 中。
5.6 Transformation
5.6.1 Map
DataStream → DataStream:输入一个参数产生一个参数。
val env = StreamExecutionEnvironment.getExecutionEnvironment
val stream = env.generateSequence(1,10) val streamMap = stream.map { x => x * 2 } streamFilter.print()
env.execute("FirstJob")
5.6.2 FlatMap
DataStream → DataStream:输入一个参数,产生 0 个、1 个或者多个输出。
val env = StreamExecutionEnvironment.getExecutionEnvironment
val stream = env.readTextFile("test.txt") val streamFlatMap = stream.flatMap{ x => x.split(" ") } streamFilter.print()
env.execute("FirstJob")
5.6.3 Filter
DataStream → DataStream:结算每个元素的布尔值,并返回布尔值为 true 的
元素。下面这个例子是过滤出非 0 的元素:
val env = StreamExecutionEnvironment.getExecutionEnvironment
val stream = env.generateSequence(1,10) val streamFilter = stream.filter{ x => x == 1 } streamFilter.print()
env.execute("FirstJob")
5.6.4 Connect
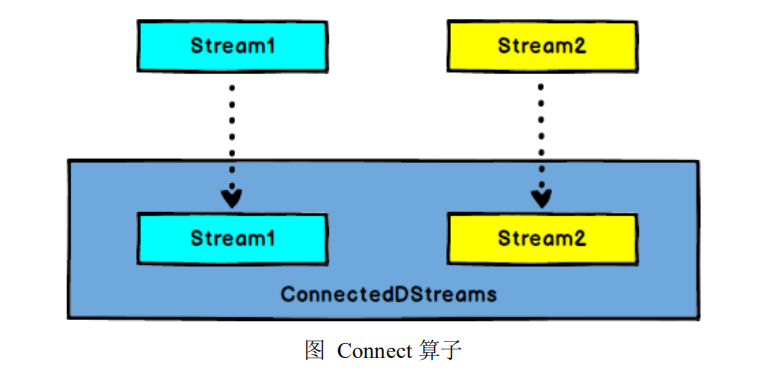
DataStream,DataStream → ConnectedStreams:连接两个保持他们类型的数据流,
两个数据流被 Connect 之后,只是被放在了一个同一个流中,内部依然保持各自的
数据和形式不发生任何变化,两个流相互独立。
val env = StreamExecutionEnvironment.getExecutionEnvironment
val stream = env.readTextFile("test.txt")
val streamMap = stream.flatMap(item => item.split(" ")).filter(item => item.equals("hadoop")) val streamCollect = env.fromCollection(List(1,2,3,4))
val streamConnect = streamMap.connect(streamCollect)
streamConnect.map(item=>println(item), item=>println(item))
env.execute("FirstJob")
5.6.5 CoMap,CoFlatMap
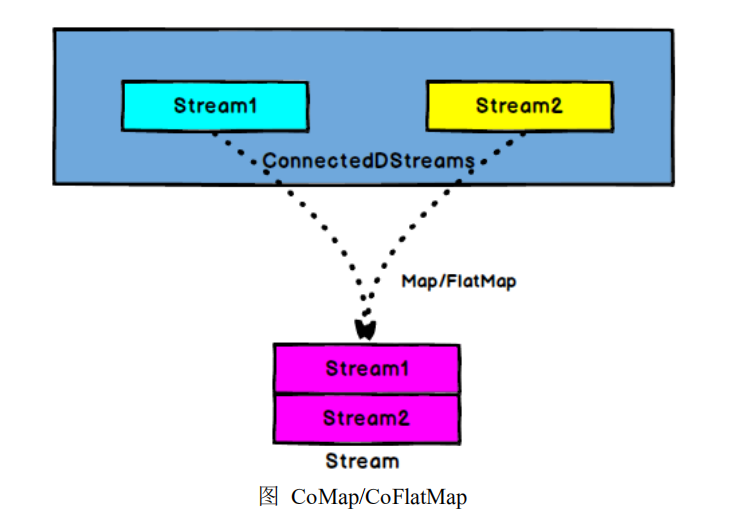
ConnectedStreams → DataStream:作用于 ConnectedStreams 上,功能与 map
和 flatMap 一样,对 ConnectedStreams 中的每一个 Stream 分别进行 map 和 flatMap处理。
val env = StreamExecutionEnvironment.getExecutionEnvironment
val stream1 = env.readTextFile("test.txt") val streamFlatMap = stream1.flatMap(x => x.split(" ")) val stream2 = env.fromCollection(List(1,2,3,4)) val streamConnect = streamFlatMap.connect(stream2) val streamCoMap = streamConnect.map( (str) => str + "connect", (in) => in + 100 )
env.execute("FirstJob")
val env = StreamExecutionEnvironment.getExecutionEnvironment
val stream1 = env.readTextFile("test.txt") val stream2 = env.readTextFile("test1.txt") val streamConnect = stream1.connect(stream2) val streamCoMap = streamConnect.flatMap( (str1) => str1.split(" "), (str2) => str2.split(" ") ) streamConnect.map(item=>println(item), item=>println(item))
env.execute("FirstJob")
5.6.6 Split
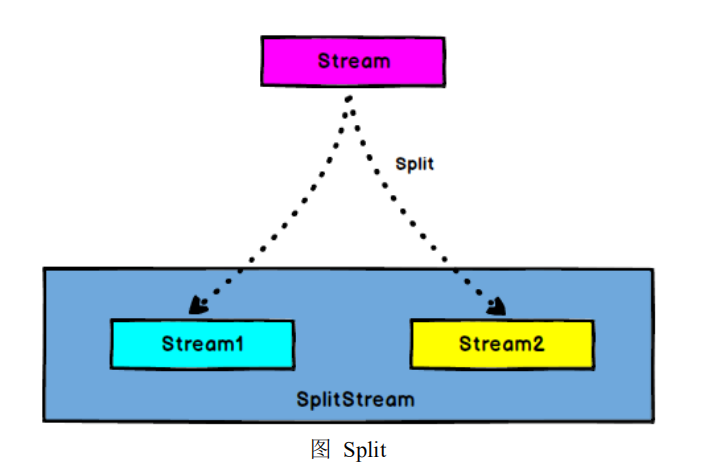
DataStream → SplitStream:根据某些特征把一个 DataStream 拆分成两个或者
多个 DataStream。
val env = StreamExecutionEnvironment.getExecutionEnvironment
val stream = env.readTextFile("test.txt") val streamFlatMap = stream.flatMap(x => x.split(" ")) val streamSplit = streamFlatMap.split( num => # 字符串内容为 hadoop 的组成一个 DataStream,其余的组成一个 DataStream (num.equals("hadoop")) match{ case true => List("hadoop") case false => List("other") } )
env.execute("FirstJob")
5.6.7 Select
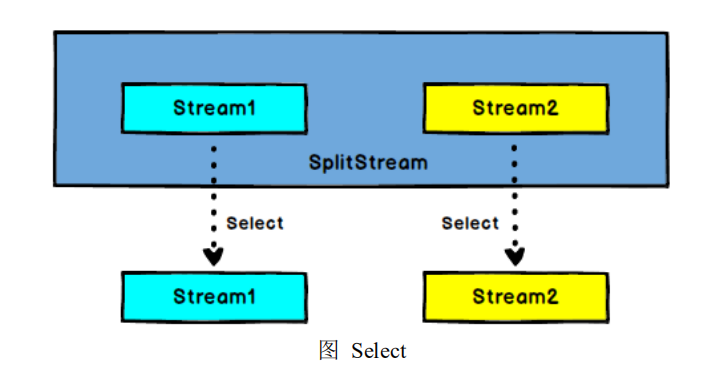
SplitStream→DataStream:从一个 SplitStream 中获取一个或者多个 DataStream。
val env = StreamExecutionEnvironment.getExecutionEnvironment
val stream = env.readTextFile("test.txt") val streamFlatMap = stream.flatMap(x => x.split(" ")) val streamSplit = streamFlatMap.split( num => (num.equals("hadoop")) match{ case true => List("hadoop") case false => List("other") } )
val hadoop = streamSplit.select("hadoop") val other = streamSplit.select("other") hadoop.print()
env.execute("FirstJob")
5.6.8 Union
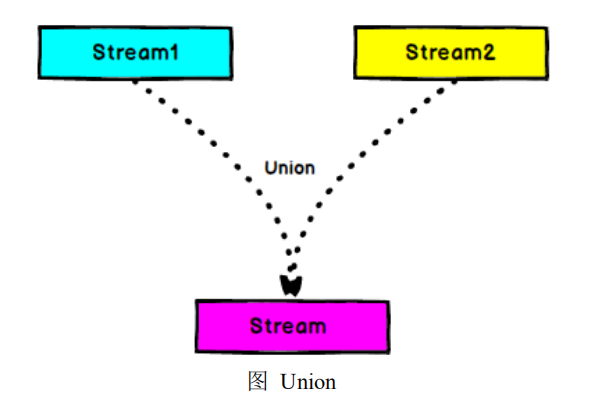
DataStream → DataStream:对两个或者两个以上的 DataStream 进行 union 操
作,产生一个包含所有 DataStream 元 素 的 新 DataStream。注意 :如果你将一个
DataStream 跟它自己做 union 操作,在新的 DataStream 中,你将看到每一个元素都
出现两次。
val env = StreamExecutionEnvironment.getExecutionEnvironment
val stream1 = env.readTextFile("test.txt") val streamFlatMap1 = stream1.flatMap(x => x.split(" ")) val stream2 = env.readTextFile("test1.txt") val streamFlatMap2 = stream2.flatMap(x => x.split(" ")) val streamConnect = streamFlatMap1.union(streamFlatMap2)
env.execute("FirstJob")
5.6.9 KeyBy
DataStream → KeyedStream:输入必须是 Tuple 类型,逻辑地将一个流拆分成
不相交的分区,每个分区包含具有相同 key 的元素,在内部以 hash 的形式实现的。
val env = StreamExecutionEnvironment.getExecutionEnvironment val stream = env.readTextFile("test.txt") val streamFlatMap = stream.flatMap{ x => x.split(" ") } val streamMap = streamFlatMap.map{ x => (x,1) } val streamKeyBy = streamMap.keyBy(0) env.execute("FirstJob")
5.6.10 Reduce
KeyedStream → DataStream:一个分组数据流的聚合操作,合并当前的元素
和上次聚合的结果,产生一个新的值,返回的流中包含每一次聚合的结果,而不是
只返回最后一次聚合的最终结果。
val env = StreamExecutionEnvironment.getExecutionEnvironment
val stream = env.readTextFile("test.txt").flatMap(item => item.split(" ")).map(item => (item, 1)).keyBy(0)
val streamReduce = stream.reduce( (item1, item2) => (item1._1, item1._2 + item2._2) )
streamReduce.print()
env.execute("FirstJob")
5.6.11 Fold
KeyedStream → DataStream:一个有初始值的分组数据流的滚动折叠操作,
合并当前元素和前一次折叠操作的结果,并产生一个新的值,返回的流中包含每一
次折叠的结果,而不是只返回最后一次折叠的最终结果。
val env = StreamExecutionEnvironment.getExecutionEnvironment
val stream = env.readTextFile("test.txt").flatMap(item => item.split(" ")).map(item => (item, 1)).keyBy(0) val streamReduce = stream.fold(100)( (begin, item) => (begin + item._2) ) streamReduce.print()
env.execute("FirstJob")
5.6.12 Aggregations
KeyedStream → DataStream:分组数据流上的滚动聚合操作。min 和 minBy 的
区别是 min 返回的是一个最小值,而 minBy 返回的是其字段中包含最小值的元素(同
样原理适用于 max 和 maxBy),返回的流中包含每一次聚合的结果,而不是只返回
最后一次聚合的最终结果。
keyedStream.sum(0) keyedStream.sum("key") keyedStream.min(0) keyedStream.min("key") keyedStream.max(0) keyedStream.max("key") keyedStream.minBy(0) keyedStream.minBy("key") keyedStream.maxBy(0) keyedStream.maxBy("key")
val env = StreamExecutionEnvironment.getExecutionEnvironment
val stream = env.readTextFile("test02.txt").map(item => (item.split(" ")(0), item.split(" ")(1).toLong)).keyBy(0)
val streamReduce = stream.sum(1)
streamReduce.print()
env.execute("FirstJob")
在 2.3.10 之前的算子都是可以直接作用在 Stream 上的,因为他们不是聚合类型
的操作,但是到 2.3.10 后你会发现,我们虽然可以对一个无边界的流数据直接应用
聚合算子,但是它会记录下每一次的聚合结果,这往往不是我们想要的,其实,
reduce、fold、aggregation 这些聚合算子都是和 Window 配合使用的,只有配合
Window,才能得到想要的结果。
测试笔记:
package transformation import org.apache.flink.streaming.api.scala._ object Transformation01 { def main(args: Array[String]): Unit = { val env = StreamExecutionEnvironment.getExecutionEnvironment /* Map */ // val stream = env.generateSequence(1, 10) // val streamMap = stream.map(item => item * 2) // streamMap.print() /* FlatMap */ // val stream = env.readTextFile("test00.txt") // val streamFlat = stream.flatMap(item => item.split(" ")) // streamFlat.print() /* Filter */ // val stream = env.generateSequence(1, 10) // val streamFilter = stream.filter(item => item != 1) // streamFilter.print() /* Connect */ /* CoMap, CoFlatMap */ // val stream01 = env.generateSequence(1, 10) // val stream02 = env.readTextFile("test00.txt").flatMap(item => item.split(" ")) // val streamConnect = stream01.connect(stream02) // streamConnect.map(item => println(item), item => print(item)) // val streamComap = streamConnect.map(item => item * 2, item => (item, 1L)) // streamComap.print() /* Split */ /* Select */ // val stream = env.readTextFile("test00.txt").flatMap(item => item.split(" ")) // val streamSplit = stream.split( // word => // ("hadoop".equals(word)) match { // case true => List("hadoop") // case false => List("other") // } // ) // val streamSelect01 = streamSplit.select("hadoop") // val streamSelect02 = streamSplit.select("other") // // streamSelect01.print() // streamSelect02.print() /* Union */ // val stream01 = env.readTextFile("test00.txt").flatMap(item => item.split(" ")) // val stream02 = env.readTextFile("test01.txt").flatMap(item => item.split(" ")) // // val streamUnion = stream01.union(stream02) // streamUnion.print() /* KeyBy */ /* Reduce */ // // 创建 SocketSource // val stream = env.socketTextStream("localhost", 11111) // // 对 stream 进行处理并按 key 聚合 //// val streamKeyBy = stream.map(item => (item.split(" ")(0), item.split(" ")(1).toLong)).keyBy(0) // val streamKeyBy = stream.flatMap(item => item.split(" ")).map(item => (item, 1)).keyBy(0) // // 引入滚动窗口 // // 这里的 5 指的是 5 个相同 key 的元素计算一次 // val streamWindow = streamKeyBy.countWindow(5) // // 执行聚合操作 // val streamReduce = streamWindow.reduce{ // (item1, item2) => (item1._1, item1._2 + item2._2) // } // // 将聚合数据写入文件 // streamReduce.print() /* Fold */ // val stream = env.readTextFile("test00.txt").flatMap(item => item.split(" ")).map(item => (item, 1)).keyBy(0) // val streamReduce = stream.fold(100)( // (begin, item) => (begin + item._2) // ) // streamReduce.print() /* Aggregations */ val stream = env.readTextFile("test02.txt").map(item => (item.split(" ")(0), item.split(" ")(1).toLong)).keyBy(0) val streamReduce = stream.sum(1) streamReduce.print() env.execute("FirstJob") } }