MapReduce:
是一种编程模型,用于大规模数据集(大于1TB)的并行运算。概念"Map(映射)"和"Reduce(归约)",是它们的主要思想,都是从函数式编程语言里借来的,还有从矢量编程语言里借来的特性。它极大地方便了编程人员在不会分布式并行编程的情况下,将自己的程序运行在分布式系统上。 当前的软件实现是指定一个Map(映射)函数,用来把一组键值对映射成一组新的键值对,指定并发的Reduce(归约)函数,用来保证所有映射的键值对中的每一个共享相同的键组。









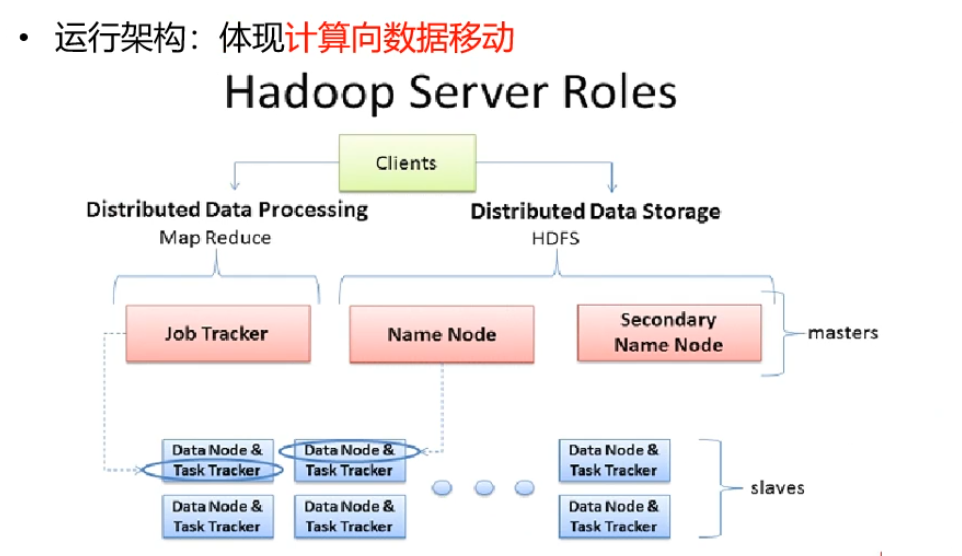

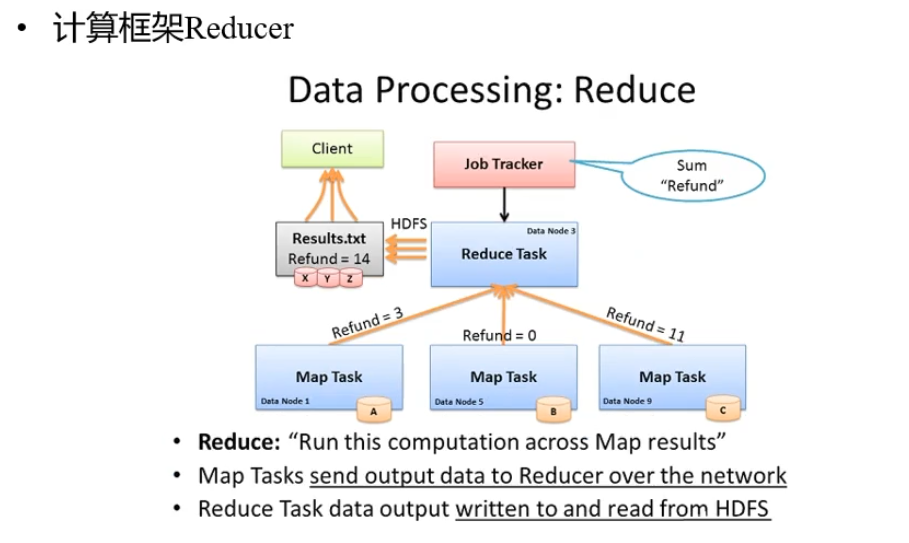

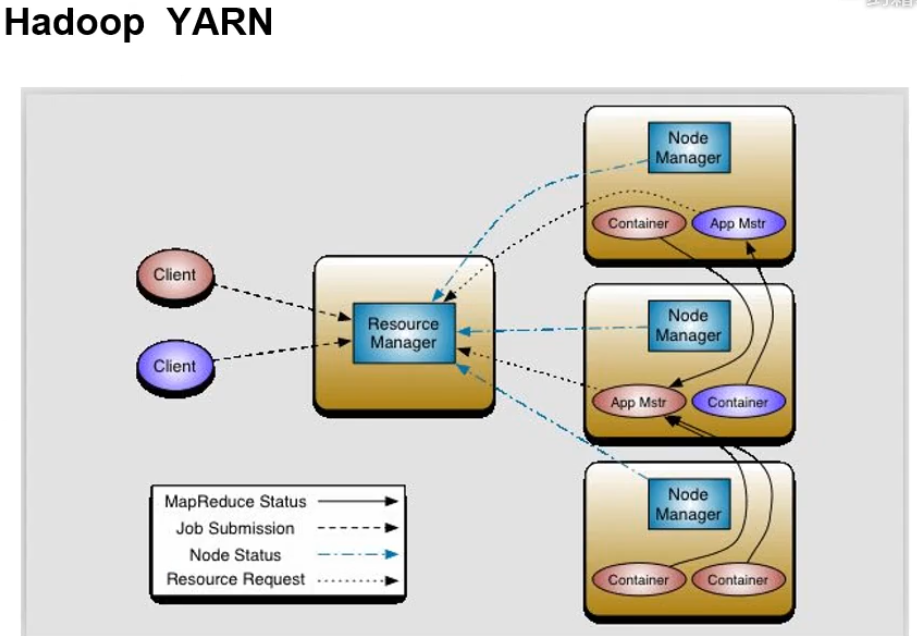
深入剖析MapReduce架构及原理
MapReduce应用场景
MapReduce 定义
Hadoop 中的 MapReduce 是一个使用简单的软件框架,基于它写出来的应用程序能够运行在由上千个商用机器组成的大型集群上,并以一种可靠容错式并行处理TB级别的数据集。
MapReduce 来源
Hadoop MapReduce 源于 Google 在2004年12月份发表的 MapReduce 论文。 Hadoop MapReduce 其实就是 Google MapReduce 的一个克隆版本。
MapReduce 特点
MapReduce 为什么如此受欢迎?尤其现在互联网+时代,互联网+公司都在使用MapReduce。MapReduce 之所以如此受欢迎,它主要有以下几个特点。
MapReduce 易于编程 。
它简单的实现一些接口,就可以完成一个分布式程序,这个分布
式程序可以分布到大量廉价的 PC 机器运行。也就是说你写一个分布式程序,跟写一个简单的串行程序是一模一样的。就是因为这个特点使得 MapReduce 编程变得非常流行。
2、良好的 扩展性 。当你的计算资源不能得到满足的时候,你可以通过简单的增加机器来扩展
它的计算能力。
3、 高容错性 。MapReduce 设计的初衷就是使程序能够部署在廉价的 PC 机器上,这就要求
它具有很高的容错性。比如其中一台机器挂了,它可以把上面的计算任务转移到另外一个节点上面上运行,不至于这个任务运行失败,而且这个过程不需要人工参与,而完全是由
Hadoop 内部完成的。
4、适合 PB 级以上海量数据的 离线处理 。这里加红字体离线处理,说明它适合离线处理而不
适合在线处理。比如像毫秒级别的返回一个结果,MapReduce 很难做到。
MapReduce 虽然具有很多的优势,但是它也有不擅长的地方。这里的不擅长不代表它不能做,而是在有些场景下实现的效果差,并不适合 MapReduce 来处理,主要表现在以下几个方面。
1、实时计算。MapReduce 无法像 Mysql 一样,在毫秒或者秒级内返回结果。
2、流式计算。流式计算的输入数据时动态的,而 MapReduce 的输入数据集是静态的,不能动态变化。这是因为 MapReduce 自身的设计特点决定了数据源必须是静态的。
3、DAG(有向图)计算。多个应用程序存在依赖关系,后一个应用程序的输入为前一个的输出。在这种情况下,MapReduce 并不是不能做,而是使用后,每个MapReduce 作业的输出结果都会写入到磁盘,会造成大量的磁盘IO,导致性能非常的低下。
MapReduce的编程模型
MapReduce 实例
为了分析 MapReduce 的编程模型,这里我们以 WordCount 为实例。就像 Java、C++等编程语言的入门程序 hello word 一样,WordCount 是 MapReduce 最简单的入门程序。
下面我们就来逐步分析。
1、场景:假如有大量的文件,里面存储的都是单词。
类似应用场景:WordCount 虽然很简单,但它是很多重要应用的模型。
搜索引擎中,统计最流行的 K 个搜索词。
统计搜索词频率,帮助优化搜索词提示。
2、任务:我们该如何统计每个单词出现的次数?
3、将问题规范为:有一批文件(规模为 TB 级或者 PB 级),如何统计这些文件中所有单词出现的次数。
4、解决方案:首先,分别统计每个文件中单词出现的次数;然后,累加不同文件中同一个单词出现次数。
MapReduce 执行流程
通过上面的分析可知,它其实就是一个典型的 MapReduce 过程。下面我们通过示意图来分析 MapReduce 过程
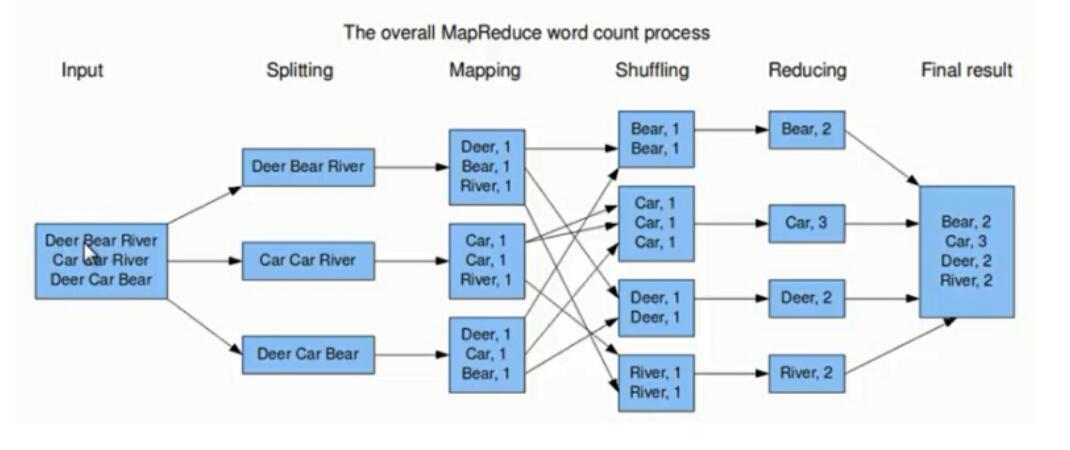
上图的流程大概分为以下几步。
第一步:假设一个文件有三行英文单词作为 MapReduce 的Input(输入),这里经过 Splitting 过程把文件分割为3块。分割后的3块数据就可以并行处理,每一块交给一个 map 线程处理。
第二步:每个 map 线程中,以每个单词为key,以1作为词频数value,然后输出。
第三步:每个 map 的输出要经过 shuffling(混洗),将相同的单词key放在一个桶里面,然后交给 reduce 处理。
第四步:reduce 接受到 shuffling 后的数据,会将相同的单词进行合并,得到每个单词的词频数,最后将统计好的每个单词的词频数作为输出结果。
上述就是 MapReduce 的大致流程,前两步可以看做 map 阶段,后两步可以看做 reduce 阶段。下面我们来看看 MapReduce 大致实现。
1、Input:首先 MapReduce 输入的是一系列key/value对。key表示每行偏移量,value代
表每行输入的单词。
2、用户提供了 map 函数和 reduce 函数的实现:

map 函数将每个单词转化为key/value对输出,这里key为每个单词,value为词频1。(k1,v1)是 map 输出的中间key/value结果对。reduce 将相同单词的所有词频进行合并,比如将单词k1,词频为list(v1),合并为(k2,v2)。reduce 合并完之后,最终输出一系列(k2,v2)
键值对。
下面我们来看一下 MapReduce 的伪代码。

我们可以对 MapReduce 做一个总结。MapReduce 将 作业 的整个运行过程分
为两个阶段:Map 阶段和Reduce 阶段。
1、Map 阶段
Map 阶段是由一定数量的 Map Task 组成。这些 Map Task 可以同时运行,每个 Map Task
又是由以下三个部分组成。
1) 对输入数据格式进行解析的一个组件: InputFormat 。因为不同的数据可能存储的数据格
式不一样,这就需要有一个 InputFormat 组件来解析这些数据的存放格式。默认情况下,它
提供了一个 TextInputFormat 来解释数据格式。TextInputFormat 就是我们前面提到的文
本文件输入格式,它会将文件的每一行解释成(key,value),key代表每行偏移量,value代表每行数据内容。通常情况我们不需要自定义 InputFormat,因为 MapReduce 提供了很多种InputFormat的实现,我们根据不同的数据格式,选择不同的 InputFormat 来解释就可以了。这一点我们后面会讲到。
1) 输入数据处理: Mapper
这个 Mapper 是必须要实现的,因为根据不同的业务对数据有不
同的处理。
2) 数据分组: Partitioner
Mapper 数据处理之后输出之前,输出key会经过 Partitioner
分组或者分桶选择不同的reduce。默认的情况下,Partitioner 会对 map 输出的key进行hash取模,比如有6个Reduce Task,它就是模(mod)6,如果key的hash值为0,就选择第0个 Reduce Task,如果key的hash值为1,就选择第一个 Reduce Task。这样不同的 map 对相同单词key,它的 hash 值取模是一样的,所以会交给同一个 reduce 来处理。
2、Reduce 阶段
Reduce 阶段由一定数量的 Reduce Task 组成。这些 Reduce Task 可以同时运行,每个
Reduce Task又是由以下四个部分组成。
1) 数据运程拷贝。Reduce Task 要运程拷贝每个 map 处理的结果,从每个 map 中读取一部分结果。每个 Reduce Task 拷贝哪些数据,是由上面 Partitioner 决定的
2) 数据按照key排序。Reduce Task 读取完数据后,要按照key进行排序。按照key排序后,相同的key被分到一组,交给同一个 Reduce Task 处理。
3) 数据处理: Reducer 。以WordCount为例,相同的单词key分到一组,交个同一个
Reducer处理,这样就实现了对每个单词的词频统计。
4) 数据输出格式: OutputFormat 。Reducer 统计的结果,将按照 OutputFormat 格式输出。默认情况下的输出格式为 TextOutputFormat,以WordCount为例,这里的key为单
词,value为词频数。
InputFormat、Mapper、Partitioner、Reducer和OutputFormat 都是用户可以实现的。通常情况下,用户只需要实现 Mapper和Reducer,其他的使用默认实现就可以了。
MapReduce 内部逻辑
下面我们通过 MapReduce 的内部逻辑,来分析 MapReduce的数据处理过程。我们以
WordCount为例,来看一下mapreduce 内部逻辑,如下图所示。
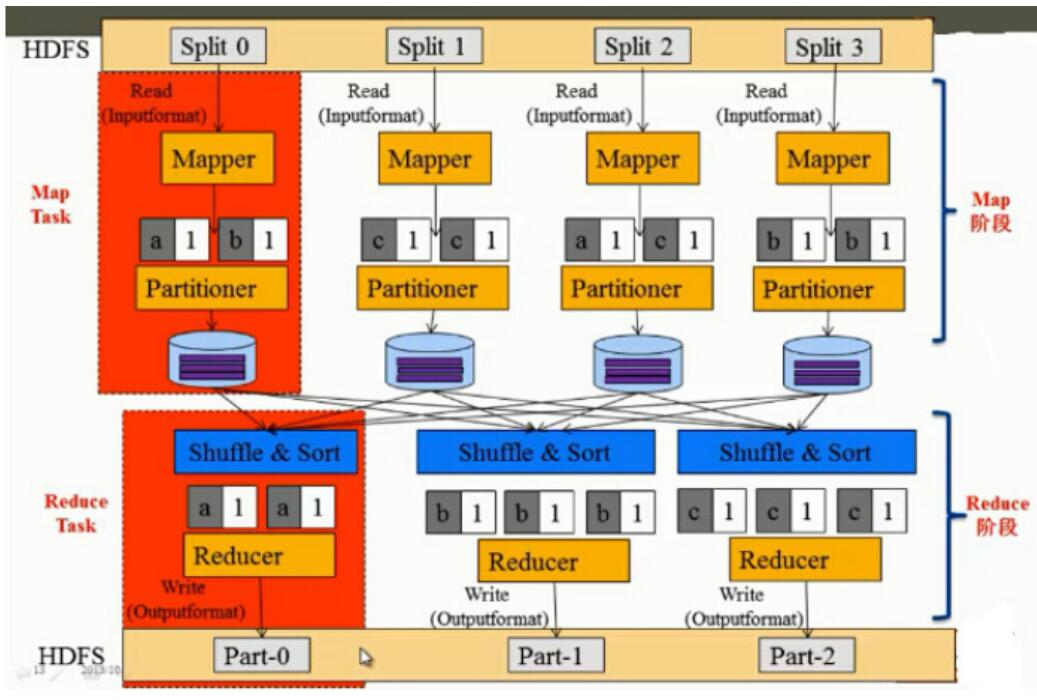
MapReduce 内部逻辑的大致流程主要由以下几步完成。
1、首先将 HDFS 中的数据以 Split 方式作为 MapReduce 的输入。前面我们提到,HDFS中的数据是以 block存储,这里怎么又变成了以Split 作为输入呢?其实 block 是 HDFS 中的术语,Split 是 MapReduce 中的术语。默认的情况下,一个 Split 可以对应一个 block,当然也可以对应多个block,它们之间的对应关系是由 InputFormat 决定的。默认情况下,使用
的是 TextInputFormat,这时一个Split对应一个block。假设这里有4个block,也就是4个
Split,分别为Split0、Split1、Split2和Split3。这时通过 InputFormat 来读每个Split里面的数据,它会把数据解析成一个个的(key,value),然后交给已经编写好的Mapper 函数来处
理。
2、每个Mapper 将输入(key,value)数据解析成一个个的单词和词频,比如(a,1)、(b,1)和(c,1)等等。
3、Mapper解析出的数据,比如(a,1),经过 Partitioner之后,会知道该选择哪个Reducer来
处理。每个 map 阶段后,数据会输出到本地磁盘上。
4、在reduce阶段,每个reduce要进行 shuffle 读取它所对应的数据。当所有数据读取完之后,要经过Sort全排序,排序之后再交给 Reducer 做统计处理。比如,第一个Reducer读取了两个的(a,1)键值对数据,然后进行统计得出结果(a,2)。
5、将 Reducer 的处理结果,以OutputFormat数据格式输出到 HDFS 的各个文件路径下。这里的OutputFormat默认为TextOutputFormat,key为单词,value为词频数,key和value之间的分割符为" ab"。由上图所示,(a 2)输出到Part-0,(b 3)输出到Part-1,(c 3) 输出到Part-2。
原文:https://blog.csdn.net/wypersist/article/details/79783872