ascii
A : 00000010 8位 一个字节
unicode A : 00000000 00000001 00000010 00000100 32位 四个字节
中:00000000 00000001 00000010 00000110 32位 四个字节
utf-8 A : 00100000 8位 一个字节
中 : 00000001 00000010 00000110 24位 三个字节
gbk A : 00000110 8位 一个字节
中 : 00000010 00000110 16位 两个字节
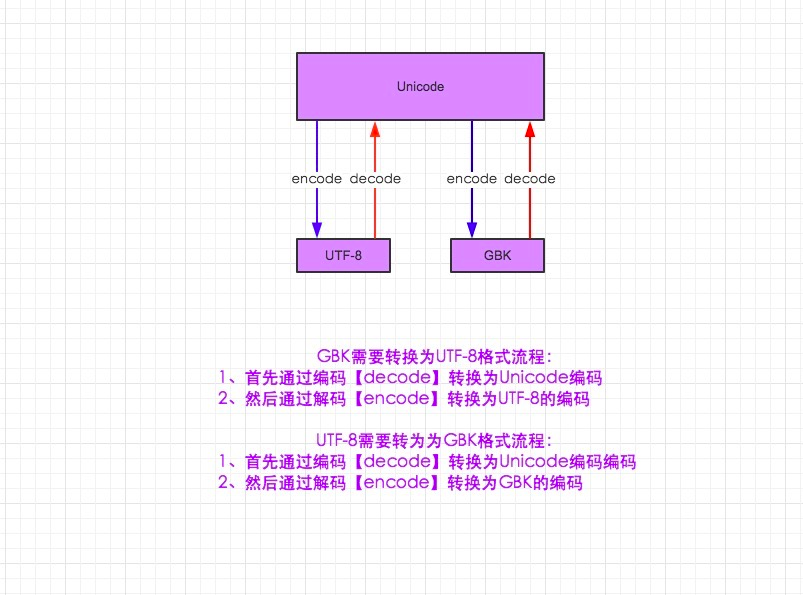
1,各个编码之间的二进制,是不能互相识别的,会产生乱码。
2,文件的储存,传输,不能是unicode(只能是utf-8 utf-16 gbk,gb2312,asciid等)
py3:

str 在内存中是用unicode编码。
bytes类型
对于英文:
str :表现形式:s = 'alex'
编码方式: 010101010 unicode
bytes :表现形式:s = b'alex'
编码方式: 000101010 utf-8 gbk。。。。
对于中文:
str :表现形式:s = '中国'
编码方式: 010101010 unicode
bytes :表现形式:s = b'xe91e91e01e21e31e32'
编码方式: 000101010 utf-8 gbk。。。。
#str --->byte encode 编码 s = '二哥' b = s.encode('utf-8') print(b) # b'xe4xbax8cxe5x93xa5' #byte --->str decode 解码 s1 = b.decode('utf-8') print(s1) # 二哥 s = 'abf' b = s.encode('utf-8') print(b) # b'abf' #byte --->str decode 解码 s1 = b.decode('gbk') print(s1) # abf
Python3的执行过程:
- 解释器找到代码文件,把代码字符串按文件头定义的编码加载到内存,转成unicode
- 把代码字符串按照语法规则进行解释,
- 所有的变量字符都会以unicode编码声明,默认文件编码是utf-8
str=u'好好学习天天向上' #加u表示unicode,默认也是unicode
utf-8_to _gbk = str.decode('utf-8').encode('gbk')
待补充。。。。。。。。。