一 文件操作
一 介绍
计算机系统分为:计算机硬件,操作系统,应用程序三部分。
我们用python或其他语言编写的应用程序若想要把数据永久保存下来,必须要保存于硬盘中,这就涉及到应用程序要操作硬件,众所周知,应用程序是无法直接操作硬件的,这就用到了操作系统。操作系统把复杂的硬件操作封装成简单的接口给用户/应用程序使用,其中文件就是操作系统提供给应用程序来操作硬盘虚拟概念,用户或应用程序通过操作文件,可以将自己的数据永久保存下来。
有了文件的概念,我们无需再去考虑操作硬盘的细节,只需要关注操作文件的流程:
#1. 打开文件,得到文件句柄并赋值给一个变量 #2. 通过句柄对文件进行操作 #3. 关闭文件
二 在python中
#1. 打开文件,得到文件句柄并赋值给一个变量 f=open('a.txt','r',encoding='utf-8') #默认打开模式就为r #2. 通过句柄对文件进行操作 data=f.read() #3. 关闭文件 f.close()
三 f=open('a.txt','r')的过程分析
#1、由应用程序向操作系统发起系统调用open(...) #2、操作系统打开该文件,并返回一个文件句柄给应用程序 #3、应用程序将文件句柄赋值给变量f
四 强调!!!
#强调第一点: 打开一个文件包含两部分资源:操作系统级打开的文件+应用程序的变量。在操作完毕一个文件时,必须把与该文件的这两部分资源一个不落地回收,回收方法为: 1、f.close() #回收操作系统级打开的文件 2、del f #回收应用程序级的变量 其中del f一定要发生在f.close()之后,否则就会导致操作系统打开的文件还没有关闭,白白占用资源, 而python自动的垃圾回收机制决定了我们无需考虑del f,这就要求我们,在操作完毕文件后,一定要记住f.close() 虽然我这么说,但是很多同学还是会很不要脸地忘记f.close(),对于这些不长脑子的同学,我们推荐傻瓜式操作方式:使用with关键字来帮我们管理上下文 with open('a.txt','w') as f: pass with open('a.txt','r') as read_f,open('b.txt','w') as write_f: data=read_f.read() write_f.write(data) 强调第一点:资源回收
#强调第二点: f=open(...)是由操作系统打开文件,那么如果我们没有为open指定编码,那么打开文件的默认编码很明显是操作系统说了算了,
操作系统会用自己的默认编码去打开文件,在windows下是gbk,在linux下是utf-8。 这就用到了上节课讲的字符编码的知识:若要保证不乱码,文件以什么方式存的,就要以什么方式打开。 f=open('a.txt','r',encoding='utf-8')
五 python2中的file与open
#首先在python3中操作文件只有一种选择,那就是open() #而在python2中则有两种方式:file()与open() 两者都能够打开文件,对文件进行操作,也具有相似的用法和参数,但是,这两种文件打开方式有本质的区别,file为文件类,用file()来打开文件,
相当于这是在构造文件类,而用open()打开文件,是用python的内建函数来操作,我们一般使用open()打开文件进行操作,而用file当做一个类型,
比如type(f) is file
二 打开文件的模式
文件句柄 = open('文件路径', '模式')
模式可以是以下方式以及他们之间的组合:
|
Character |
Meaning |
| ‘r' | open for reading (default) |
| ‘w' | open for writing, truncating the file first |
| ‘a' | open for writing, appending to the end of the file if it exists |
| ‘b' | binary mode |
| ‘t' | text mode (default) |
| ‘+' | open a disk file for updating (reading and writing) |
| ‘U' | universal newline mode (for backwards compatibility; should not be used in new code) |
#1. 打开文件的模式有(默认为文本模式): r ,只读模式【默认模式,文件必须存在,不存在则抛出异常】 w,只写模式【不可读;不存在则创建;存在则清空内容】 a, 之追加写模式【不可读;不存在则创建;存在则只追加内容】 #2. 对于非文本文件,我们只能使用b模式,"b"表示以字节的方式操作(而所有文件也都是以字节的形式存储的,使用这种模式无需考虑文本文件的字符编码、图片文件的jgp格式、视频文件的avi格式) rb wb ab 注:以b方式打开时,读取到的内容是字节类型,写入时也需要提供字节类型,不能指定编码 #3. 了解部分 "+" 表示可以同时读写某个文件 r+, 读写【可读,可写】 w+,写读【可读,可写】 a+, 写读【可读,可写】 x, 只写模式【不可读;不存在则创建,存在则报错】 x+ ,写读【可读,可写】 xb
# 回车与换行的来龙去脉 http://www.cnblogs.com/linhaifeng/articles/8477592.html # U模式 'U' mode is deprecated and will raise an exception in future versions of Python. It has no effect in Python 3. Use newline to control universal newlines mode. # 总结: 在python3中使用默认的newline=None即可,换行符无论何种平台统一用 即可 了解U模式与换行符
三 操作文件的方法
#掌握 f.read() #读取所有内容,光标移动到文件末尾 f.readline() #读取一行内容,光标移动到第二行首部 f.readlines() #读取每一行内容,存放于列表中 f.write('1111 222 ') #针对文本模式的写,需要自己写换行符 f.write('1111 222 '.encode('utf-8')) #针对b模式的写,需要自己写换行符 f.writelines(['333 ','444 ']) #文件模式 f.writelines([bytes('333 ',encoding='utf-8'),'444 '.encode('utf-8')]) #b模式 #了解 f.readable() #文件是否可读 f.writable() #文件是否可读 f.closed #文件是否关闭 f.encoding #如果文件打开模式为b,则没有该属性 f.flush() #立刻将文件内容从内存刷到硬盘 f.name
练习,利用b模式,编写一个cp工具,要求如下:
1. 既可以拷贝文本又可以拷贝视频,图片等文件
2. 用户一旦参数错误,打印命令的正确使用方法,如usage: cp source_file target_file
提示:可以用import sys,然后用sys.argv获取脚本后面跟的参数


import sys if len(sys.argv) != 3: print('usage: cp source_file target_file') sys.exit() source_file,target_file=sys.argv[1],sys.argv[2] with open(source_file,'rb') as read_f,open(target_file,'wb') as write_f: for line in read_f: write_f.write(line)
四 文件内光标移动
一: read(3):
1. 文件打开方式为文本模式时,代表读取3个字符
2. 文件打开方式为b模式时,代表读取3个字节
二: 其余的文件内光标移动都是以字节为单位如seek,tell,truncate
注意:
1. seek有三种移动方式0,1,2,其中1和2必须在b模式下进行,但无论哪种模式,都是以bytes为单位移动的
2. truncate是截断文件,所以文件的打开方式必须可写,但是不能用w或w+等方式打开,因为那样直接清空文件了,所以truncate要在r+或a或a+等模式下测试效果
import time with open('test.txt','rb') as f: f.seek(0,2) while True: line=f.readline() if line: print(line.decode('utf-8')) else: time.sleep(0.2) 练习:基于seek实现tail -f功能
五 文件的修改
文件的数据是存放于硬盘上的,因而只存在覆盖、不存在修改这么一说,我们平时看到的修改文件,都是模拟出来的效果,具体的说有两种实现方式:
方式一:将硬盘存放的该文件的内容全部加载到内存,在内存中是可以修改的,修改完毕后,再由内存覆盖到硬盘(word,vim,nodpad++等编辑器)
import os with open('a.txt') as read_f,open('.a.txt.swap','w') as write_f: data=read_f.read() #全部读入内存,如果文件很大,会很卡 data=data.replace('alex','SB') #在内存中完成修改 write_f.write(data) #一次性写入新文件 os.remove('a.txt') os.rename('.a.txt.swap','a.txt')
方式二:将硬盘存放的该文件的内容一行一行地读入内存,修改完毕就写入新文件,最后用新文件覆盖源文件
import os with open('a.txt') as read_f,open('.a.txt.swap','w') as write_f: for line in read_f: line=line.replace('alex','SB') write_f.write(line) os.remove('a.txt') os.rename('.a.txt.swap','a.txt')
六 用代码演示文件操作
首先新建一个的文件‘wenjian’,文件内容如下:

文件的读模式,这种模式下只能读
f = open('e:wenjian.txt', 'r', encoding='utf8') # open打开这个文件,r是读模式,后面的是编码 # 并且把句柄赋值给变量f,可以通过f对文件进行操作 print(f.read()) # 读取所有内容 #输出: # 1*1=1 # 1*2=2 2*2=4 # 1*3=3 2*3=6 3*3=9 # 1*4=4 2*4=8 3*4=12 4*4=16 # 1*5=5 2*5=10 3*5=15 4*5=20 5*5=25 # 1*6=6 2*6=12 3*6=18 4*6=24 5*6=30 6*6=36 # 1*7=7 2*7=14 3*7=21 4*7=28 5*7=35 6*7=42 7*7=49 print(f.readline()) # 读取第一行内容,光标移动到第二行首部 #输出:1*1=1 print(f.readlines()) # 读取每一行内容,存放于列表中 #输出:['1*1=1 ', '1*2=2 2*2=4 ', '1*3=3 2*3=6 3*3=9 ', '1*4=4 2*4=8 3*4=12 4*4=16 ', '1*5=5 2*5=10 3*5=15 4*5=20 5*5=25 ', '1*6=6 2*6=12 3*6=18 4*6=24 5*6=30 6*6=36 ', '1*7=7 2*7=14 3*7=21 4*7=28 5*7=35 6*7=42 7*7=49 '] print(f.read(5)) # 输出5个字符,如果是英语一个字母一个字符,在Py3中一个汉字其实是三个字符,但在这里依旧是一个汉字一个字符 #输出:1*1=1 f.close()
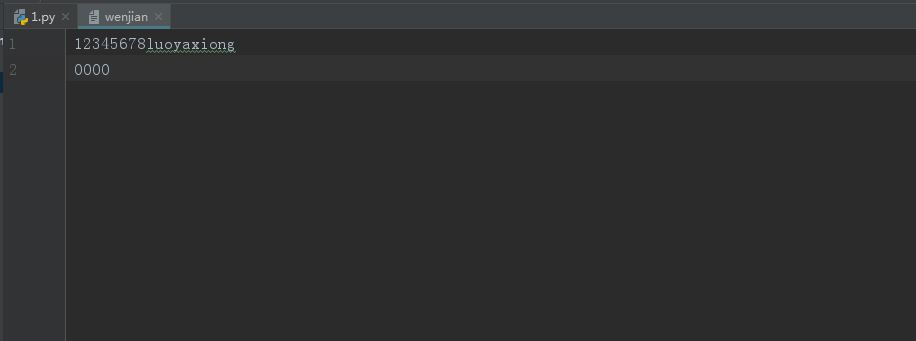
文件的写模式,这种模式下只能写
f=date=open('wenjian', 'w', encoding='utf8')#在这个模式下,文件内容已经清空,如果没有这个文件名就会创建这个文件 f.write('12345678')#向文件中写入,但是里面原有的内容会消失,先清空,再写入 f.write('luoyaxiong')#紧贴着上面的内容,不会换行 f.write(' 0000 ')#换行 f.close()
源文件修改后结果:
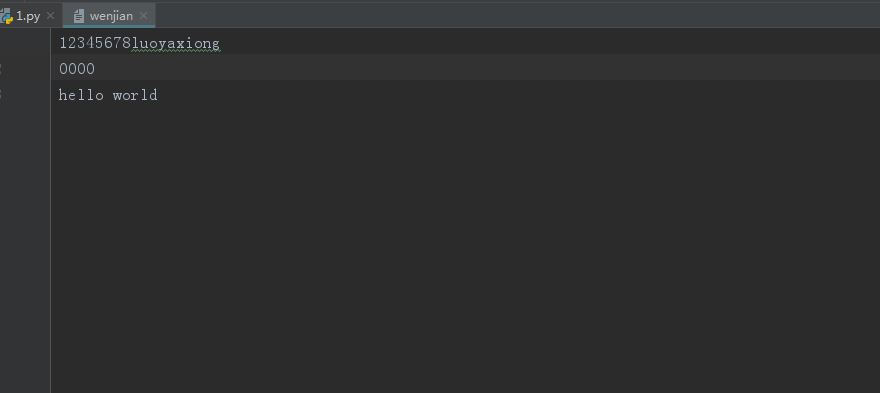
文件的增添模式(append)
f=date=open('wenjian', 'a', encoding='utf8')#文件的增补模式 f.write(' hello world')#在最下面一行增加内容 f.close()
源文件修改后结果:
文件操作的一系列方法
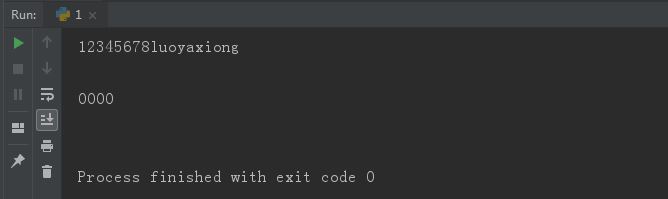
f = open('wenjian', 'r', encoding='utf8') a=f.readline() print(a)#变量接收不换行 print(f.readline())#这个就要换行 f.close()
输出:
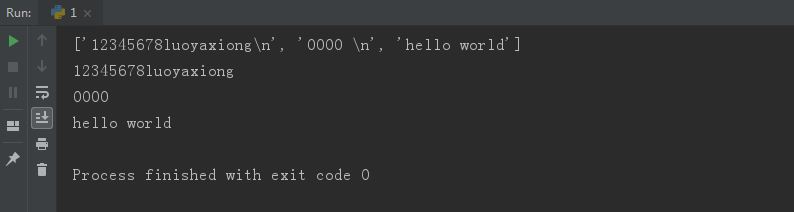
f = open('wenjian', 'r', encoding='utf8') a=f.readlines() # 把每一行的内容做成了一个列表['12345678luoyaxiong ', '0000 ', 'hello world'] print(a) # 得到一个列表,这样就可以用对列表处理的方法处理整个文本 for i in a: print(i.strip())#去除首尾字符, 即去除'12345678luoyaxiong '里的 ,本来就有一次换行,如果不.strip就会是两行一句 f.close()
输出:
现在重新把文件‘wenjian’储存成下面这样
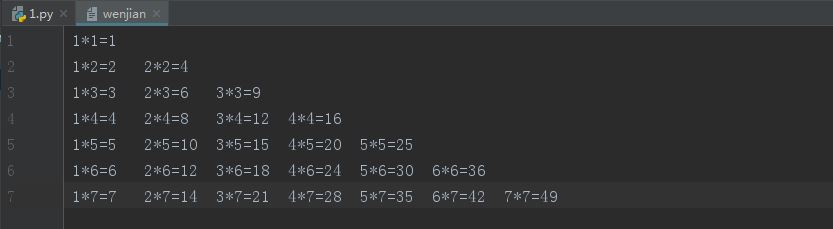
要求在第六行加上 梦想可大可小可远可近可笑可赞叹
以下两种都行(但是源文件没有任何变化...)
f = open('wenjian', 'r', encoding='utf8') a=f.readlines() number=0 for i in a: number+=1 if number==6: i=''.join([i.strip(),'梦想可大可小可远可近可笑可赞叹'])# 连接字符串的 print(i.strip()) f.close()
f = open('wenjian', 'r', encoding='utf8')#打开文件 a=f.readlines()#读取文件每行内容形成列表 f.close()#文件关闭,至此,文件操作结束,非常短的时间 a[5]=a[5].strip()+'梦想可大可小可远可近可笑可赞叹' for i in a: print(i.strip())
输出:
光标的位置
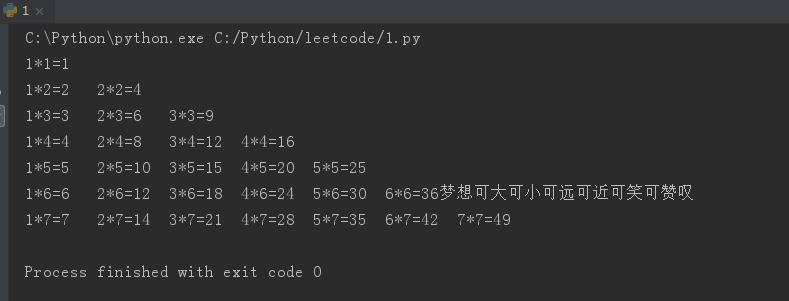
现在重新把文件‘wenjian’储存成下面这样

f = open('wenjian', 'r', encoding='utf8') print(f.read(3))#打印三个‘字符’的内容 print(f.tell())#告诉当前光标的位置,一个汉字是三个字符,所以位置是9 f.seek(2)#调整光标的位置到2(可以用此方法把光标定位到任意位置再进行操作) print(f.tell())
输出:
truncate():截断数据(只能在a模式下)
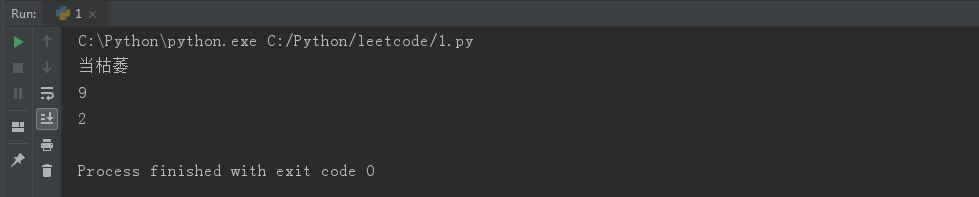
现在重新把文件‘wenjian’储存成下面这样

#truncate():截断数据(只能在a模式下) #在w模式下:先清空,再写,再截断 #在a模式下:直接将指定位置后的内容截断 f = open('wenjian', 'a', encoding='utf8') f.truncate(5)#现将光标定位在5位,然后删除后面的数据,但必须在‘a’模式下
改变后的源文件:

七 练习题
1. 文件a.txt内容:每一行内容分别为商品名字,价钱,个数,求出本次购物花费的总钱数 apple 10 3 tesla 100000 1 mac 3000 2 lenovo 30000 3 chicken 10 3 2. 修改文件内容,把文件中的alex都替换成SB