作业要求:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE2/homework/3339
1.将爬虫大作业产生的csv文件上传到HDFS
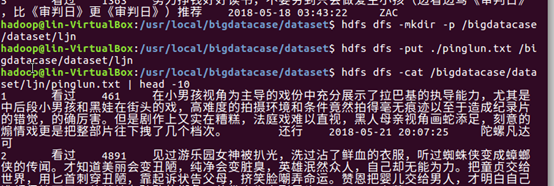
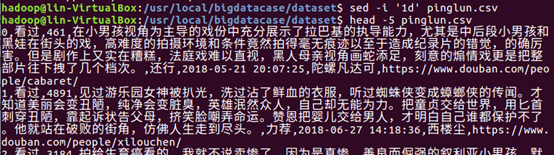
2.对CSV文件进行预处理生成无标题文本文件
3.打开数据仓库Hive
4.把hdfs中的文本文件最终导入到数据仓库Hive中

5.在Hive中查看并分析数据
查看用户名:

查看用户是否观看过电影:
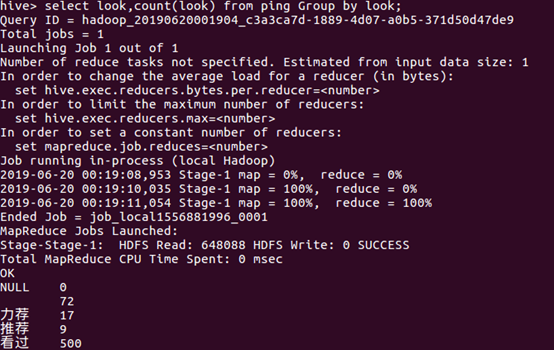
查看从热到冷的评论的用户名及查看人数:
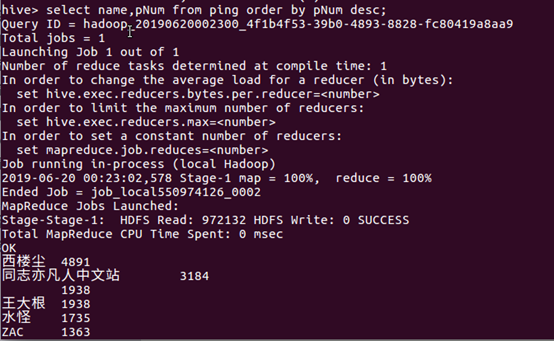
查看用户对这部电影的态度:

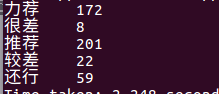
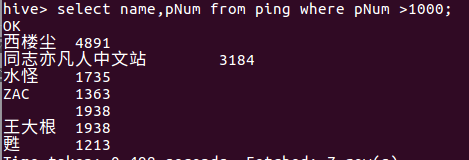
查看评论热度大于1000的用户名及人数:
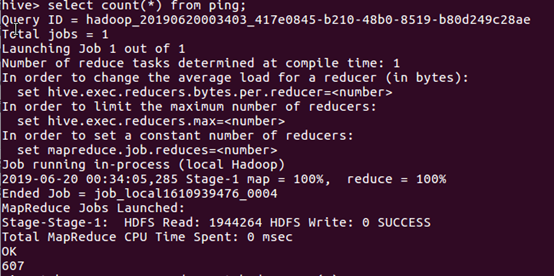
查看表格的用户个数:
查看看过电影的用户人数:
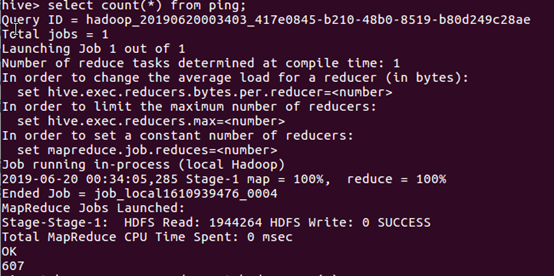
查看热度超过1000的评论:

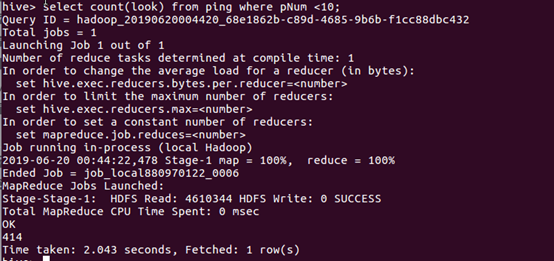
查看热度低于10的评论的条数:
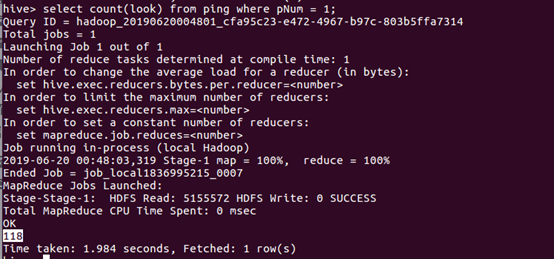
查看热度为1的评论的条数:
6.分析过程。
下图为书写评论的人中看没看过电影的人数的扇形图,如图显示虽然大部分人都是看过电影的,但是还是有相当一部分人是在没有看过电影的情况下胡说八道的。

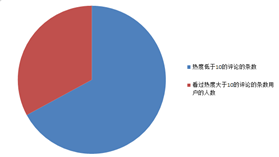
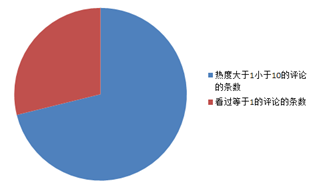
下图为热度低于10的评论条数占评论总数的扇形图,从评论中可以看出,热度低于10也就是只有极少数人认同的评论占据了评论的绝大多数。
下图为热度等于1的评论条数占评论总数的扇形图,从评论中可以看出,热度等于1也就是几乎没人认同的评论占据了评论的一个不小的比例。
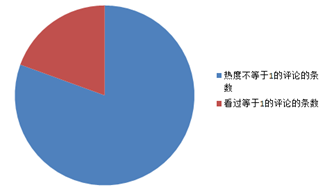
下图为热度等于1的评论条数占热度小于10的评论条数数的扇形图,从评论中可以看出,热度等于1也就是只有几乎没人认同的评论占据了热度小于10的评论的绝大多数。
7.分析结果:
观看这部电影没有必要看评论,因为绝大多数评论是没有意义的,无人认同的评论占据了大多数。