矩阵图
使用矩阵图来存储有向图和无向图的信息,用无穷大表示两点之间不连通,用两点之间的距离来表示连通。无向图的矩阵图是关于主对角线对称的。
如图所示:
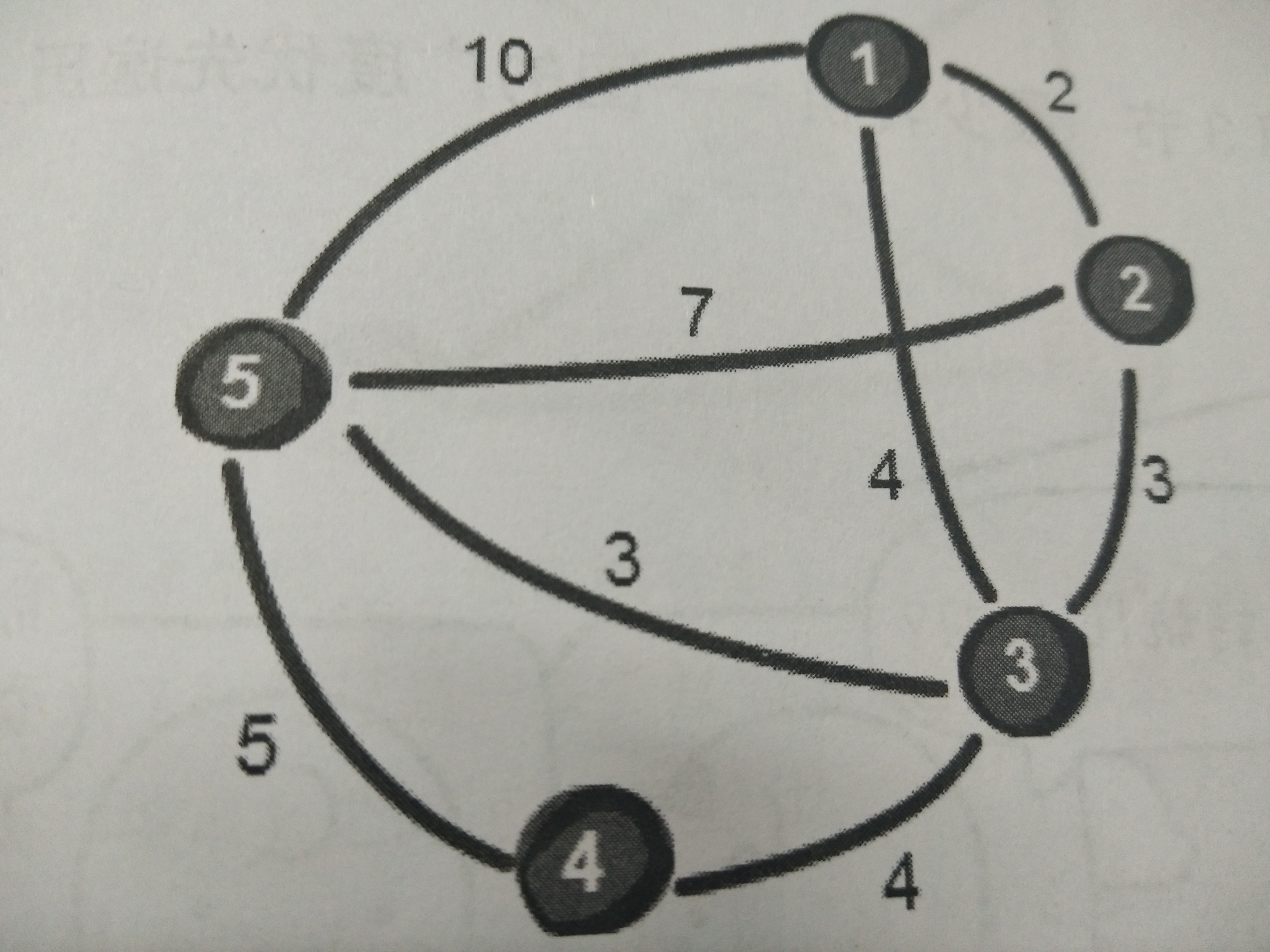
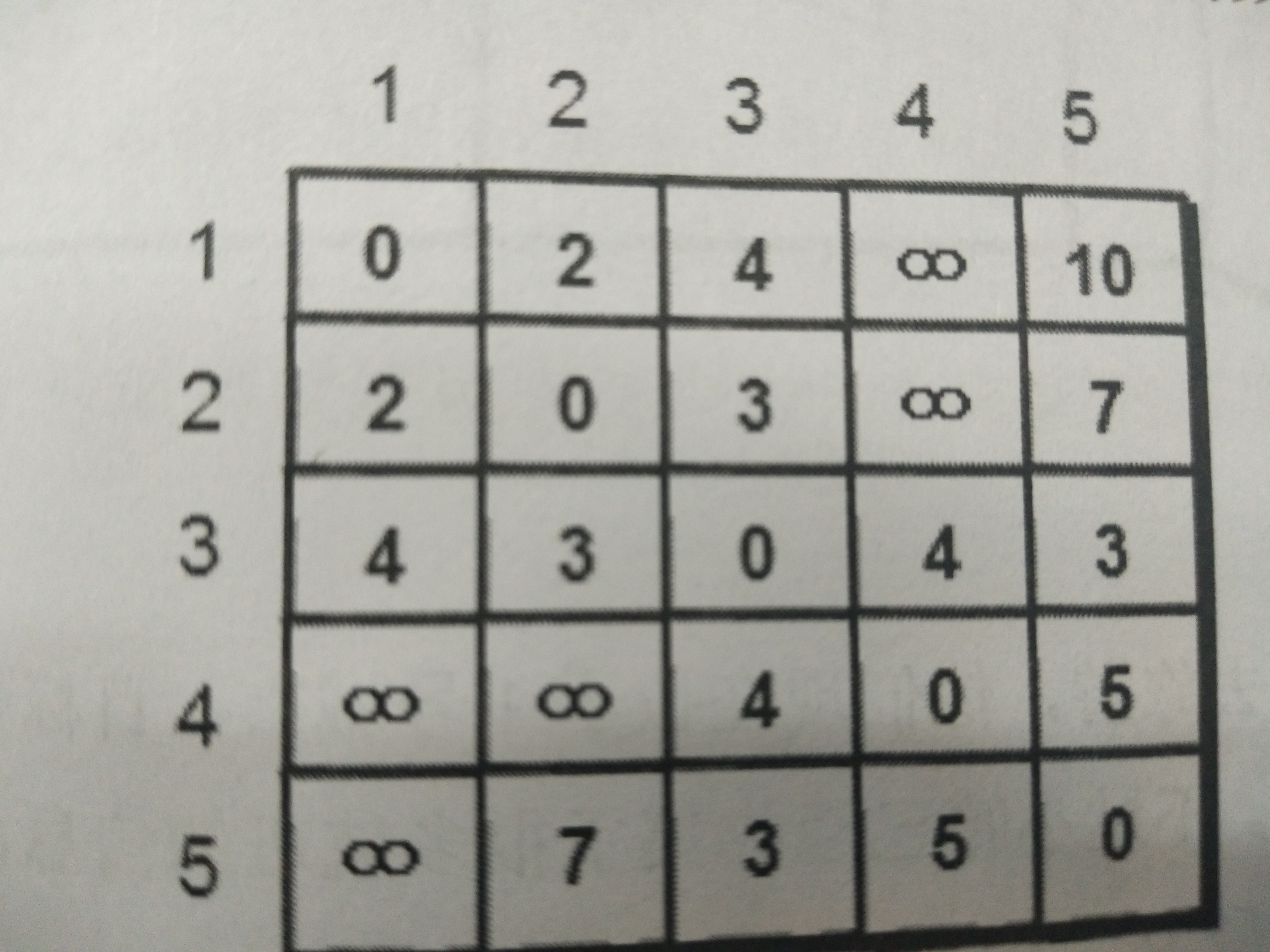
使用dfs和bfs对矩阵图进行遍历
多源最短路径问题
最短路径的方法Floyd算法:
- $n^2$遍深度或广度优先搜索 权值为一
- Floyd算法(多源最短路)是全局最优的动态规划
其核心算法如下:
for(int k=1;k<=n;k++)
{
for(int i=1;i<=n;i++)
{
for(int j=1;j<=n;j++)
{
if(G[i][j]>G[i][k]+G[k][j])
{
G[i][j]=G[i][k]+G[k][j];
}
}
}
}
单源最短路径Dijkstra算法
基本思想是每次找到一个离源点最近的一个顶点,然后以这个点为中心进行扩展,最终得到源点到其余点的最短路径。
- 顶点分为两个部分:已知最短路程的顶点集合P(确定值)和未知的集合Q(估计值)。可以简单的开设一个标记数组。
- 绘制矩阵图并初始化。
- Q中选择一个离源点最近加入到P中并对并利用这个点对其他边进行松弛。
- 当Q为空结束操作。
模板题链接题目链接
AC代码如下:
#include<iostream>
#include<cstdio>
#include<cstring>
#include<cmath>
#include<algorithm>
#include<vector>
#include<queue>
#define INF 0x3f3f3f3f
#define MAXN 200000
using namespace std;
vector<int> G[MAXN];
vector<int> M[MAXN];
int dis[MAXN];
int done[MAXN];
struct item
{
int u;
int dis;
friend bool operator < (struct item x,struct item y)
{
return x.dis>y.dis;
}
};
priority_queue<item>q;
int main()
{
memset(dis,0x3f,sizeof(dis));
int N,m,S;
scanf("%d%d%d",&N,&m,&S);
for(int i=1;i<=m;i++)
{
int x,y,z;
scanf("%d%d%d",&x,&y,&z);
G[x].push_back(y);
M[x].push_back(z);
}
q.push((item){S,0});
dis[S]=0;
while(!q.empty())
{
item t;
t=q.top();
q.pop();
int au=t.u;
if(done[au]) continue;
done[au]=1;
for(int i=0;i<G[au].size() ;i++)
{
int p=G[au][i];
int c=dis[au]+M[au][i];
if(dis[p]>c)
{
dis[p]=c;
q.push((item){p,c});
}
}
}
for(int i=1;i<=N;i++)
{
if(i==S) printf("0 ");
else
{
printf("%d ",dis[i]);
}
}
return 0;
}
Bellman-Ford——解决负权边
对所有边进行n-1次松弛操作
使用v和u数组存边,用w数组存权值
核心代码如下:
for(int k=1;k<=n-1;k++)//进行n-1次松弛操作
{
for(int i=1;i<=m;i++)//枚举每一条边
{
if(dis[v[i]]>dis[u[i]]+w[i])//尝试对每一条边进行松弛
{
dis[v[i]]=dis[u[i]]+w[i];
}
}
}
判断是否存在负权回路的代码:
flag=1;
for(int i=1;i<=m;i++)
{
if(dis[v[i]]>dis[u[i]]+w[i])
{
flag=1;
}
}
if(flag==1) printf("xxxxxxx");
因为n-1遍是最大值所以我们可以通过添加一个一位数组对dis 进行备份,如果新一轮的松弛中没有发生变化那就可以提前跳出循环。
优化后的核心代码如下:
for(int k=1;k<=n-1;k++)//进行n-1次松弛操作
{
for(int i=1;i<=n;i++)
{
bak[i]=dis[i];//备份数据
}
for(int i=1;i<=m;i++)//枚举每一条边
{
if(dis[v[i]]>dis[u[i]]+w[i])//尝试对每一条边进行松弛
{
dis[v[i]]=dis[u[i]]+w[i];
}
}
bool check=0;
for(int i=1;i<=n;i++)
{
if(bak[i]!=dis[i])
{
check=1;
break;
}
}
if(!check)
{
break;
}
}
SPFA——队列优化的bellman-ford
每次仅对最短路径估计值发生变化了的顶点的所有出边执行松弛操作,实现上和BFS十分类似,但是区别在于BFS时一个顶点出队后不会再进队,但是这里会的,如果某个点进入队列次数超过n次则证明存在负环。
核心代码如下:
inline bool spfa()
{
queue<int>q;
memset(dis,0x3f,sizeof(dis));
memset(done,0,sizeof(done));
q.push(1); done[1]=1; dis[1]=0;
while(!q.empty())
{
int u=q.front(); q.pop(); done[u]=0;
for(int i=head[u];i;i=edge[i].nxt)
{
int v=edge[i].to;
if(dis[v]>dis[u]+edge[i].dis)
{
dis[v]=dis[u]+edge[i].dis;
siz[v]=siz[u]+1;
if(siz[v]>=n)
return false;
if(!done[v])
{
q.push(v);
done[v]=1;
}
}
}
}
return true;
}
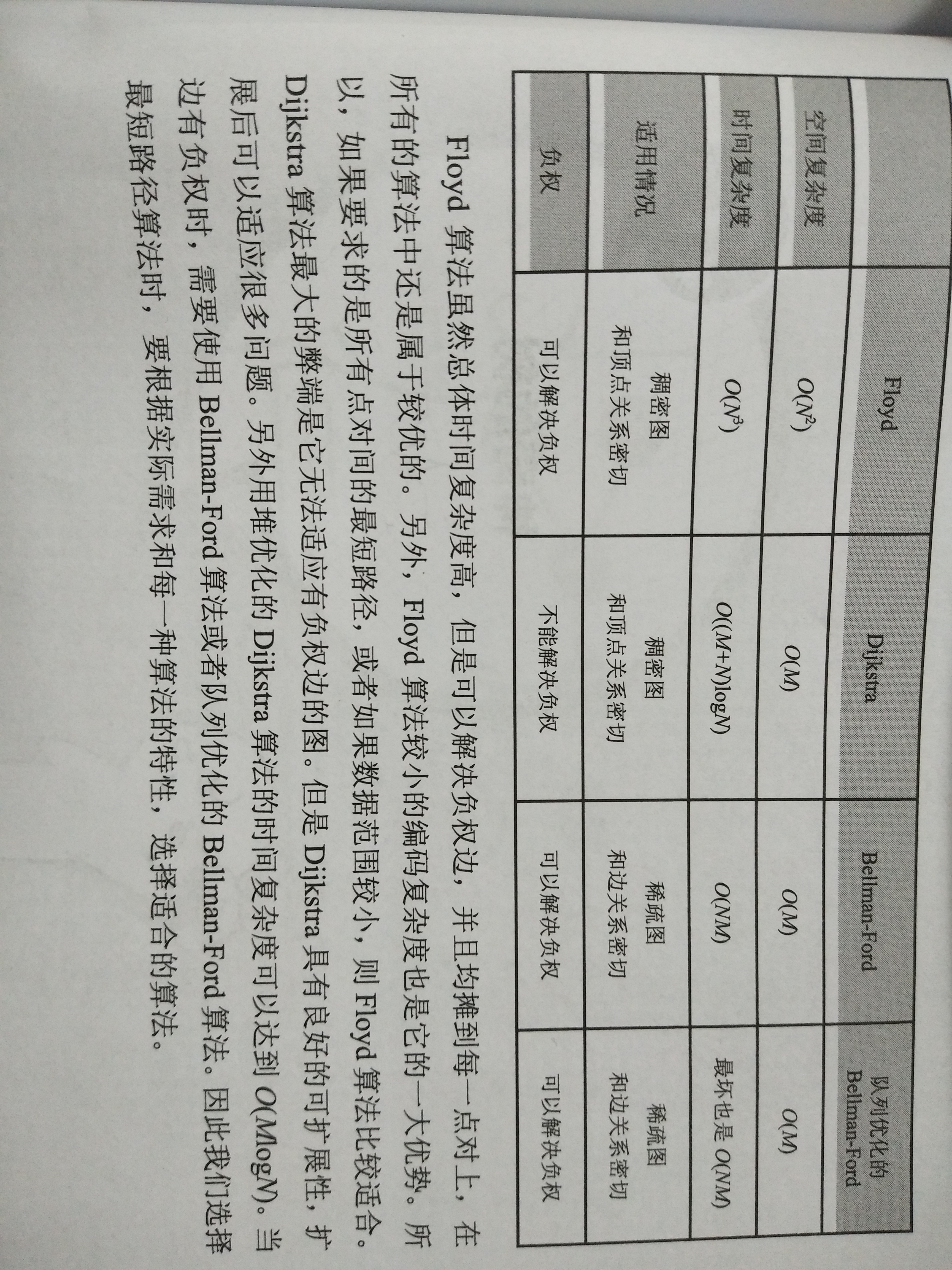
对四种最短路径算法的对比图(摘自《啊哈!算法》)
欧拉回路
- 欧拉通路、欧拉回路、欧拉图
- 设G是连通无向图,则称经过G的每条边一次并且仅一次的路径为欧拉通路;
- 如果欧拉通路是回路(起点和终点是同一个顶点),则称此回路为欧拉回路;
- 具有欧拉回路的无向图G称为欧拉图。
- 一些推论
一.无向图
1.存在欧拉通路的条件是:该图为连通图且有两个奇数度数的点或者没有奇数度数的点。
2.该图为欧拉图(存在欧拉回路)的充分必要条件是:G为无奇度结点的连通图。
二.有向图
1.存在欧拉通路的条件是:所有顶点的出度与入度都相等;或者除两个顶点外,其余顶点的出度与入度都相等,而这两个顶点中一个顶点的出度与入度之差为1,另一个顶点的出度与入度之差为-1。
2.该图为欧拉图(存在欧拉回路)的充分必要条件是:所有顶点的出、入度都相等。
-
判断该图是否为欧拉回路的思路:
如果是无向图就开一个记录度数的数组在读入边的时候+1,然后根据上述判断条件进行判定。
如果是有向图就开两个数组一个纪录进入的度数,一个记录出的度数根据上述判断条件进行判定。 -
输出欧拉回路的路径
核心代码如下:
void dfs(int u)
{
for (int v = 0; v < n; v++)
{if (G[u][v] && ! visit[u][v])
{
cout << u << "->" << v << endl;
visit[u][v] = visit[v][u] = 1;
dfs(v);
}
}
}
拓扑排序
有一个大佬已经讲的很详细了大家可以去看一下:拓扑排序
bfs代码如下(邻接表)
void toposort(){
queue<int> q;
for(int i = 1;i <= n;i++)
{
if(!indeg[i]) q.push(i);
}
int id = 1;
while(!q.empty())
{
int u = q.front(); q.pop();
topo[id++] = u;
for(int i = 0;i < G[u].size();i++)
{
if(--indeg[G[u][i]] == 0) q.push(G[u][i]);
}
}
}
(矩阵图)
void toposort(){
queue<int> q;
for(int i = 1;i <= n;i++)
{
if(!indeg[i]) q.push(i);
}
int id = 1;
while(!q.empty())
{
int u = q.front(); q.pop();
topo[id++] = u;
for(int i = 0;i < 26;i++)
{
if( !G[u][i] ) continue;
if(--indeg[G[u][i]] == 0) q.push(G[u][i]);
}
}
}
并查集
- 有“合并集合”和“查找集合中的元素”两种操作。
- 存在一个前提:如果A是B的子集,B是C的子集,那么A就是C的子集。
- 用集合中的某个元素来代表这个集合,该元素称为集合的代表元。
- 判断两个元素是否属于同一集合,只需要看他们的代表元是否相同即可。
- 代表元在树的根部,只要顺着树找到根部就可以找到代表元了!
- 为了加快查找速度,查找时将x到根节点路径上的所有点的parent设为根节点,该优化方法称为压缩路径。
-
代码实现并查集的操作(摘自https://segmentfault.com/a/1190000004023326)
包括对所有单个的数据建立一个单独的集合(即根据题目的意思自己建立的最多可能有的集合,为下面的合并查找操作提供操作对象)
在每一个单个的集合里面,有三个东西。
1,集合所代表的数据。(这个初始值根据需要自己定义,不固定)
2,这个集合的层次通常用rank表示(一般来说,初始化的工作之一就是将每一个集合里的rank置为0)。
3,这个集合的类别parent(有的人也喜欢用set表示)(其实就是一个指针,用来指示这个集合属于那一类,合并过后的集合,他们的parent指向的最终值一定是相同的。)
(**有的简单题里面集合的数据就是这个集合的标号,也就是说只包含2和3,1省略了)。
初始化的时候,一个集合的parent都是这个集合自己的标号。没有跟它同类的集合,那么这个集合的源头只能是自己了。
(最简单的集合就只含有这三个东西了,当然,复杂的集合就是把3指针这一项添加内容,如PKU食物链那题,我们还可以添加enemy指针,表示这个物种集合的天敌集合;food指针,表示这个物种集合的食物集合。随着指针的增加,并查集操作起来也变得复杂,题目也就显得更难了)
可以使用结构体或者数组来表示
结构体的查找代码:
/**
*查找集合i(一个元素是一个集合)的源头(递归实现)。
如果集合i的父亲是自己,说明自己就是源头,返回自己的标号;
否则查找集合i的父亲的源头。
**/
int get_parent(int x)
{
if(node[x].parent==x)
return x;
return get_parent(node[x].parent);
}
数组的查找代码:
//查找集合i(一个元素是一个集合)的源头(递归实现)
int Find_Set(int i)
{
//如果集合i的父亲是自己,说明自己就是源头,返回自己的标号
if(set[i]==i)
return set[i];
//否则查找集合i的父亲的源头
return Find_Set(set[i]);
}
优化后的路径压缩代码:
//递归形式的路径压缩
int getf(int v)
{
if(v==f[v]) return v;
return f[v]=getf(f[v]);
}
![[Y2DOZPSPRO6T22$F7]A_F6.png](https://i.loli.net/2019/04/21/5cbc737caa0dc.png)
代码如下:
void Union(int a,int b)
{
a=get_parent(a);
b=get_parent(b);
if(node[a].rank>node[b].rank)
node[b].parent=a;
else
{
node[a].parent=b;
if(node[a].rank==node[b].rank)
node[b].rank++;
}
}
最小生成树(部分摘自https://blog.csdn.net/heavenboya/article/details/6654778 )
-
什么是最小生成树?
1.生成树
如果连通图G的一个子图是一棵包含G的所有顶点的树,则该子图称为G的生成树。
生成树是连通图的包含图中的所有顶点的极小连通子图。
图的生成树不惟一。从不同的顶点出发进行遍历,可以得到不同的生成树。
2.生成树的求解方法
设图G=(V,E)是一个具有n个顶点的连通图。则从G的任一顶点(源点)出发,作一次深度优先搜索(广度优先搜索),搜索到的n个顶点和搜索过程中从一个已访问过的顶点vi搜索到一个未曾访问过的邻接点vj,所经过的边(vi,vj)(共n-1条)组成的极小连通子图就是生成树。(源点是生成树的根)
通常,由深度优先搜索得到的生成树称为深度优先生成树,简称为DFS生成树;由广度优先搜索得到的生成树称为广度优先生成树,简称为BPS生成树。
①图的广度优先生成树的树高不会超过该图其它生成树的高度
②图的生成树不惟一,从不同的顶点出发进行遍历,可以得到不同的生成树。
3.最小生成树
考虑一个实际的问题:连通n个城市需要布置n-1一条通信线路,这个时候我们如何在成本最低的情况下建立这个通信网?
构造这个连通网所花的成本最小时,搭建该连通网的生成树,就称为最小生成树。 -
最小生成树的性质
MST性质
设G=(V,E)是一个连通网络,U是顶点集V的一个真子集。若(u,v)是G中一条“一个端点在U中(例如:u∈U),另一个端点不在U中的边(例如:v∈V-U),且(u,v)具有最小权值,则一定存在G的一棵最小生成树包括此边(u,v)。
关于这个性质的证明这位大佬写的很详细,大家感兴趣可以去看一下MST性质 -
普里姆算法—Prim算法
算法思路:
首先就是从图中的一个起点a开始,把a加入U集合,然后,寻找从与a有关联的边中,权重最小的那条边并且该边的终点b在顶点集合:(V-U)中,我们也把b加入到集合U中,并且输出边(a,b)的信息,这样我们的集合U就有:{a,b},然后,我们寻找与a关联和b关联的边中,权重最小的那条边并且该边的终点在集合:(V-U)中,我们把c加入到集合U中,并且输出对应的那条边的信息,这样我们的集合U就有:{a,b,c}这三个元素了,一次类推,直到所有顶点都加入到了集合U。
简单版:
1).输入:一个加权连通图,其中顶点集合为V,边集合为E;
2).初始化:Vnew = {x},其中x为集合V中的任一节点(起始点),Enew = {},为空;
3).重复下列操作,直到Vnew = V:
a.在集合E中选取权值最小的边<u, v>,其中u为集合Vnew中的元素,而v不在Vnew集合当中,并且v∈V(如果存在有多条满足前述条件即具有相同权值的边,则可任意选取其中之一);
b.将v加入集合Vnew中,将<u, v>边加入集合Enew中;
4).输出:使用集合Vnew和Enew来描述所得到的最小生成树。
如果对于这个过程不是很理解可以去这两个大佬的博客看一下,有清楚的图解
数据结构--最小生成树详解
最小生成树-Prim算法和Kruskal算法
代码实现如下:
#define MAX 100000
#define VNUM 10+1 //这里没有ID为0的点,so id号范围1~10
int edge[VNUM][VNUM]={/*输入的邻接矩阵*/};
int lowcost[VNUM]={0}; //记录Vnew中每个点到V中邻接点的最短边
int addvnew[VNUM]; //标记某点是否加入Vnew
int adjecent[VNUM]={0}; //记录V中与Vnew最邻近的点
void prim(int start)
{
int sumweight=0;
int i,j,k=0;
for(i=1;i<VNUM;i++) //顶点是从1开始
{
lowcost[i]=edge[start][i];
addvnew[i]=-1; //将所有点至于Vnew之外,V之内,这里只要对应的为-1,就表示在Vnew之外
}
addvnew[start]=0; //将起始点start加入Vnew
adjecent[start]=start;
for(i=1;i<VNUM-1;i++)
{
int min=MAX;
int v=-1;
for(j=1;j<VNUM;j++)
{
if(addvnew[j]==-1&&lowcost[j]<min) //在Vnew之外寻找最短路径
{
min=lowcost[j];
v=j;
}
}
if(v!=-1)
{
printf("%d %d %d
",adjecent[v],v,lowcost[v]);
addvnew[v]=0; //将v加Vnew中
sumweight+=lowcost[v]; //计算路径长度之和
for(j=1;j<VNUM;j++)
{
if(addvnew[j]==-1&&edge[v][j]<lowcost[j])
{
lowcost[j]=edge[v][j]; //此时v点加入Vnew 需要更新lowcost
adjecent[j]=v;
}
}
}
}
printf("the minmum weight is %d",sumweight);
}
- Kruskal算法
Kruskal算法是一种用来寻找最小生成树的算法,在图中存在相同权值的边时也有效。
模板题
模板代码如下:
#include<iostream>
#include<cstdio>
#include<cstring>
#include<cmath>
#include<algorithm>
#include<queue>
#define INF 0x3f3f3f3f
#define MAXN 200000
using namespace std;
int ans;
int n,m;
int f[MAXN];
struct item
{
int u;
int v;
int w;
}edge[MAXN];
bool cmp( item x, item y)
{
return x.w<y.w;
}
int find(int u)
{
if(u==f[u]) return u;
else return f[u]=find(f[u]);
}
void kruskal()
{
sort(edge,edge+m,cmp);
for(int i=1;i<=m;i++)
{
int pu=find(edge[i].u);
int pv=find(edge[i].v);
if(pu!=pv)
{
f[pu]=pv;
ans+=edge[i].w;
}
}
}
int main()
{
scanf("%d%d",&n,&m);
for(int i=1;i<=m;i++)
{
scanf("%d%d%d",&edge[i].u,&edge[i].v,&edge[i].w);
}
for(int i=1;i<=n;i++)
{
f[i]=i;
}
kruskal();
printf("%d",ans);
return 0;
}