%matplotlib inline 是一个魔法函数(Magic Functions)。
官方给出的定义是:IPython有一组预先定义好的所谓的魔法函数(Magic Functions),你可以通过命令行的语法形式来访问它们。可见“%matplotlib inline”就是模仿命令行来访问magic函数的在IPython中独有的形式。
magic函数分两种:一种是面向行的,另一种是面向单元型的。
行magic函数 是用前缀“%”标注的,很像我们在系统中使用命令行时的形式,例如在Mac中就是你的用户名后面跟着“$”。“%”后面就是magic函数的参数了,但是它的参数是没有被写在括号或者引号中来传值的。
单元型magic函数 是由两个“%%”做前缀的,它的参数不仅是当前“%%”行后面的内容,也包括了在当前行以下的行。
注意:既然是IPython的内置magic函数,那么在Pycharm中是不会支持的。所以,大多数错误,主要是这个原因。
什么是Seaborn
Seaborn是基于matplotlib的图形可视化python包。它提供了一种高度交互式界面,便于用户能够做出各种有吸引力的统计图表。
Seaborn是在matplotlib的基础上进行了更高级的API封装,从而使得作图更加容易,在大多数情况下使用seaborn能做出很具有吸引力的图,而使用matplotlib就能制作具有更多特色的图。
应该把Seaborn视为matplotlib的补充,而不是替代物。同时它能高度兼容numpy与pandas数据结构以及scipy与statsmodels等统计模式。
pip安装seaborn:
C:Usersjason> pip install seaborn
import seaborn as sns import numpy as np import matplotlib as mpl import matplotlib.pyplot as plt %matplotlib inline
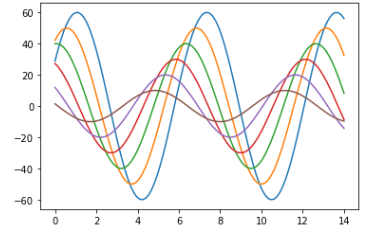
# 自定义函数:6条正弦函数曲线 def sinplot(flip=10): x = np.linspace(0, 14, 100) for i in range(1, 7): plt.plot(x, np.sin(x + i * .5) * (7 - i) * flip)
# 调用自定义函数 sinplot()
设置x轴标注的显示角度rotation=90度
plt.xticks(rotation=90) sns.violinplot(y='is_cos',x='dest_aoi',data=yyds_df,saturation=1.75)
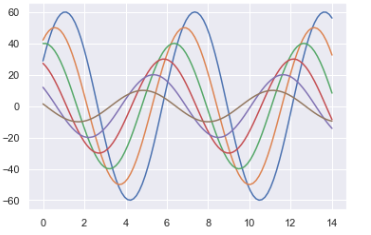
1、sns.set()设置风格
seaborn.set()函数参数:seaborn.set(context=‘notebook’, style=‘darkgrid’, palette=‘deep’, font=‘sans-serif’, font_scale=1, color_codes=True, rc=None)
set()函数,通过它我们可以设置背景色、风格、字型、字体等。
sns.set()
sinplot()
2、 sns.set_style('xx') 设置主题风格
5种主题风格¶
- darkgrid
- whitegrid
- dark
- white
- ticks
sns.set_style('whitegrid') sinplot()
sns.set_style('darkgrid') sinplot()
sns.set_style('dark') sinplot()
sns.set_style('white') sinplot()
sns.set_style('ticks') sinplot()
2.1 sns.boxplot() # 箱型图:它能显示出一组数据的最大值、最小值、中位数及上下四分位数
# sns.set_style('xx') # 设置主题风格:白色网格 sns.set_style('whitegrid') # np.random.normal(size=(n*m*k)) # 生成正太分布值,n*m*k的矩阵 # arange([start=0,] stop[, step=1,], dtype=None, *, like=None) # 生成[0,stop)步长为1的数组,如[0,1,2,3,4,5] data = np.random.normal(size=(20, 6)) + np.arange(6) / 2 print(data) # sns.boxplot() # 箱型图:它能显示出一组数据的最大值、最小值、中位数及上下四分位数 sns.boxplot(data=data)
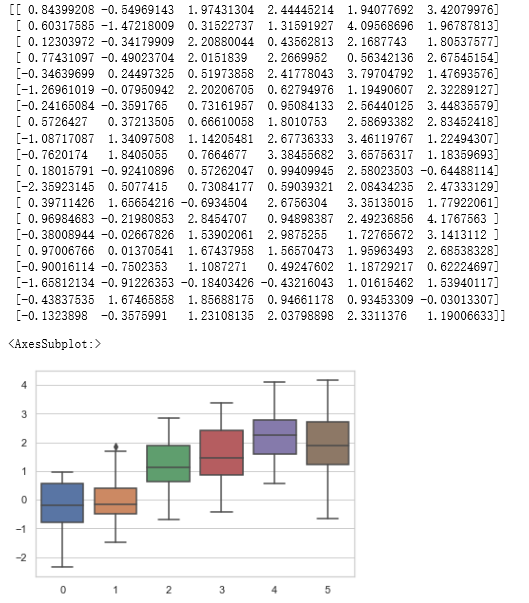
2.2 sns.violinplot() 小提琴绘图以基础分布的核密度估计为特征
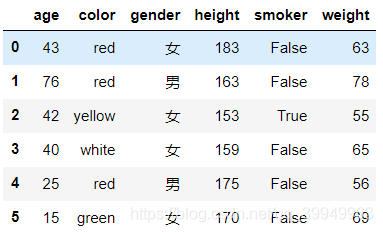
data.head(6)
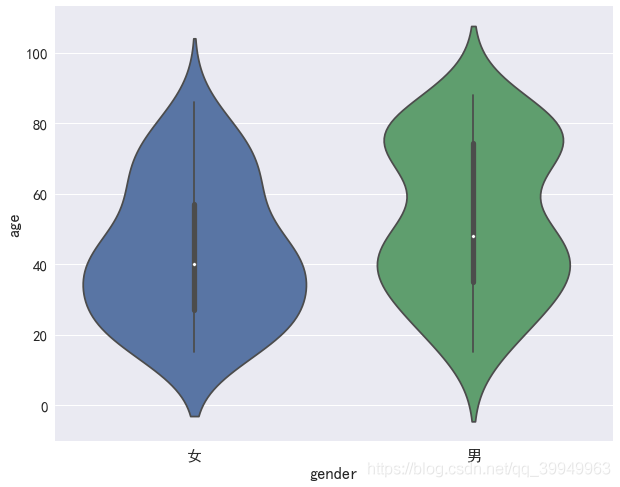
sns.violinplot(x='gender', y='age', data=data)
2.3 sns.despine() 是否隐藏轴线
sns.despine()会删除上、右坐标轴;
sns.despine(offset=200, trim=True) 只展示下坐标轴,图与轴线偏移200;
sns.despine(left=True, right = False) #left=True是左边不显示;right=False是显示;
sns.violinplot(data)

sns.violinplot(data)
sns.despine(offset=200, trim=True)
2.4 sns.boxplot() 箱线图
# palette 默认6种颜色:deep, muted, pastel, bright, dark, colorblind
sns.set_style('whitegrid') # sns.boxplot() 箱线图 # palette 默认6种颜色:deep, muted, pastel, bright, dark, colorblind sns.boxplot(data=data, palette='pastel') sns.despine(left=True) # 隐藏左坐标轴,ps:despine默认会隐藏上、右坐标轴
# sns.boxplot() 箱线图 # IQR: 统计学概念,四分位距,第(1/4)分位与第(3/4)分位之间的距离 # N= 1.5 * IQR 如果一个值>Q3+N 或 <Q1-N,则为离群点 sns.boxplot(x='day', y='total_bill', hue='time', data=tips)
# 箱线图 iris sns.boxplot(data=iris.data, orient='h')

2.5.1 sns.set_style() 设置图表风格
sns.set_style('whitegrid') # sns.boxplot() 箱线图 # palette 默认6种颜色:deep, muted, pastel, bright, dark, colorblind sns.boxplot(data=data, palette='bright') sns.despine(left=True) # 隐藏左坐标轴,ps:despine默认会隐藏上、右坐标轴
- with 语句适用于对资源进行访问的场合,确保不管使用过程中是否发生异常都会执行必要的“清理”操作,释放资源,比如文件使用后自动关闭/线程中锁的自动获取和释放等。
2.5.2 sns.axes_style
with open('1.txt') as file: data = file.read()
# with 语句适用于对资源进行访问的场合, # 确保不管使用过程中是否发生异常都会执行必要的“清理”操作,释放资源, # 比如文件使用后自动关闭/线程中锁的自动获取和释放等。 # sns.axes_style('darkgrid') 设置seaborn绘图风格 # 五种seaborn的style风格:darkgrid, whitegrid, dark, white, tick。默认的主题是darkgrid。 # plt.figure(figsize=(x,y)) # 设置画板尺寸 plt.figure(figsize=(12,8)) with sns.axes_style('darkgrid'): # plt.subplot(n,m,k) # 绘制n*m子图的第k个子图 plt.subplot(2,1,1) sinplot() plt.subplot(2,1,2) sinplot()
2.5.3 sns.set()设置风格
seaborn.set()函数参数:seaborn.set(context=‘notebook’, style=‘darkgrid’, palette=‘deep’, font=‘sans-serif’, font_scale=1, color_codes=True, rc=None)
从这个set()函数,可以看出,通过它我们可以设置背景色、风格、字型、字体等。
- context 四种预设,按相对尺寸的顺序(线条越来越粗),分别是paper,notebook, talk, and poster。notebook的样式是默认的。
- style 五种seaborn的style风格:darkgrid, whitegrid, dark, white, ticks。默认的主题是darkgrid。
# 定义画板尺寸 plt.figure(figsize=(10,8)) context_cats = ['paper', 'notebook', 'talk', 'poster'] for i in range(0,4): plt.subplot(4,1,i+1) sns.set_context(context_cats[i]) sinplot() # 线条越来越粗
# 定义画板尺寸 plt.figure(figsize=(18,16)) context_cats = ['paper', 'notebook', 'talk', 'poster'] style_cats = ['darkgrid', 'whitegrid', 'dark', 'white', 'ticks'] k = 0 for i in range(0,4): for j in range(0,5): k += 1 # context=context_cats[i],style=style_cats[j] #plt.figure(figsize=(12,10)) sns.set_context(context=context_cats[i]) with sns.axes_style(style=style_cats[j]): plt.subplot(20,1,k) sinplot()
二、调色板
调色板
- 颜色很重要
- color_palette()能传入任何Matplotlib所支持的颜色
- color_palette()不写参数则默认颜色
- set_palette()设置所有图的颜色
颜色空间 {'rgb', 'hls', 'husl', xkcd'}
RGB = seaborn.color_palette(palette = None, n_colors = None, desat = None) 调色盘
RGB 6个默认的颜色循环主题: deep, muted, pastel, bright, dark, colorblind
import numpy as np import seaborn as sns import matplotlib.pyplot as plt %matplotlib inline sns.set(rc={'figure.figsize':(6,6)})
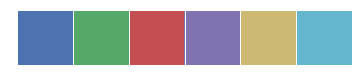
# sns.color_palette() 设置调色盘,返回颜色值数组 current_palette = sns.color_palette() # sns.palplot() 将调色板中的数组值水平绘制颜色块 sns.palplot(current_palette)
1、 hls 颜色空间
1.1 sns.color_palette()
# hls 颜色空间 #help(sns.palplot) # 查看hls颜色空间的12个颜色 sns.palplot(sns.color_palette('hls',12))

1.2 sns.color_palette('hls',8) # ‘hls’颜色空间的8个颜色值
# np.random.normal(size=(x,y)) # 生成正态分布矩阵x*y data = np.random.normal(size=(20,8)) + np.arange(8)/2 # print(data) # help(sns.color_palette) # sns.boxplot() # 箱线图 # sns.color_palette('hls',8) # ‘hls’颜色空间的8个颜色值 sns.boxplot(data=data, palette=sns.color_palette('hls',8))
1.3 sns.hls_palette(num, l=lightValue, s=saturationValue) # 控制颜色的亮度和饱和度
hls_palette()函数来控制颜色的亮度和饱和
- l-亮度 lightness
- s-饱和 saturation
# sns.hls_palette(num, l=lightValue, s=saturationValue) # 控制颜色的亮度和饱和度 sns.palplot(sns.hls_palette(8, l=0.6, s=0.8))

2、Paired 颜色空间
# Paired 颜色空间 sns.palplot(sns.color_palette('Paired', 8))

3、xkcd 颜色空间
# xkcd 颜色空间
# xkcd包含954个可以随时通过xdcd_rgb字典中调用的命名颜色。
# xkcd 颜色空间 # xkcd包含954个可以随时通过xdcd_rgb字典中调用的命名颜色。 plt.plot([0,1],[0,1], sns.xkcd_rgb['pale red'],lw=3) # lw设置线粗细 plt.plot([0,1],[0,2], sns.xkcd_rgb['medium green']) plt.plot([0,1],[0,3], sns.xkcd_rgb['denim blue'],lw=6)
3.1 sns.xkcd_palett(arr) # 获取xkcd颜色空间的某些颜色值
# type(sns.xkcd_rgb) # dict # sns.xkcd_palett(arr) # 获取xkcd颜色空间的某些颜色值 colors = ['windows blue', 'amber', 'greyish', 'faded green', 'dusty purple'] sns.palplot(sns.xkcd_palette(colors))

4、 连续色板.
'Blues'、'BuGn'
# 连续色板 sns.palplot(sns.color_palette('Blues')) # 如果想要翻转渐变,可以在面板名称中添加一个_r后缀 sns.palplot(sns.color_palette('Blues_r')) sns.palplot(sns.color_palette('BuGn')) sns.palplot(sns.color_palette('BuGn_r'))

4.1 light_palette() 和dark_palette()
sns.palplot(sns.light_palette('green')) sns.palplot(sns.light_palette('purple')) sns.palplot(sns.light_palette('red')) sns.palplot(sns.light_palette('blue')) sns.palplot(sns.light_palette('orange'))

sns.palplot(sns.light_palette('navy')) sns.palplot(sns.light_palette('navy',n_colors=8, reverse=True))

sns.palplot(sns.dark_palette('green')) sns.palplot(sns.dark_palette('purple')) sns.palplot(sns.dark_palette('orange')) sns.palplot(sns.dark_palette('orange', reverse=True))

5、cubehelix_palette() # 色调变换
# cubehelix_palette() # 色调变换 sns.palplot(sns.color_palette('cubehelix', 8)) sns.palplot(sns.color_palette('cubehelix_r',8))
# sns.cubehelix_palette() sns.palplot(sns.cubehelix_palette(8, start=0.95, rot=-0.830)) # 0 <= start <= 3 sns.palplot(sns.cubehelix_palette(8, start=0.55, rot=-0.15))

6、输入颜色元组,定义调色板
sns.palplot(sns.light_palette((210, 90, 60), input="husl"))

三、图表
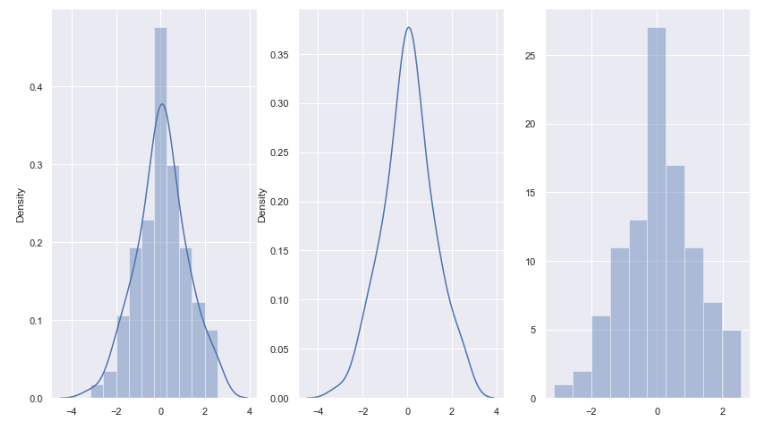
1、 sns.distplot() 绘制直方图
np.random.seed(8) # # 传入seed一个固定值参数,会得到固定的random随机返回值 # np.random.normal(size=n) # 生产包含n个正态分布值的数组 x = np.random.normal(size=100) fig,axes = plt.subplots(1,3) # 创建一个1行3列的图表 fig.set_size_inches((14,8)) # 绘制直方图axes[0] sns.distplot(x, ax=axes[0]) # sns.distplot() 绘制直方图axes[1] sns.distplot(x, ax=axes[1], hist=False) # hist=False 不显示直方图 # 绘制直方图axes[2] sns.distplot(x, ax=axes[2], kde=False) # kde=False 不显示核密度
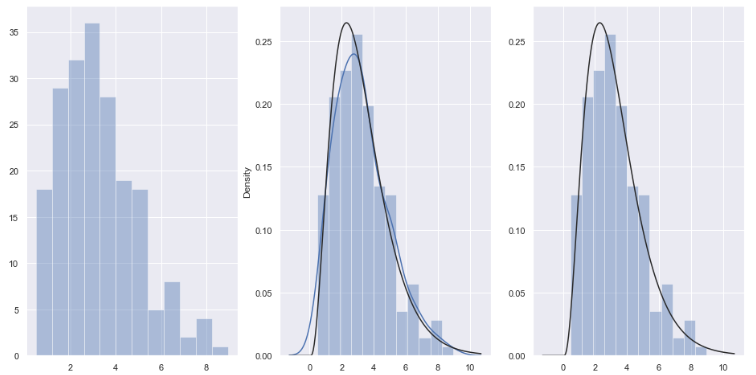
# numpy.random.gamma(shape, scale=1.0, size=None) 从伽玛分布中获取随机样本,并使用此方法返回随机样本。 x = np.random.gamma(3, size=200) fig,axes = plt.subplots(1,3) fig.set_size_inches(16,8) sns.distplot(x, ax=axes[0], kde=False) # kde=False 不显示核密度 sns.distplot(x, ax=axes[1], fit=stats.gamma) # 显示gamma曲线、和 核密度曲线 sns.distplot(x, ax=axes[2], kde=False, fit=stats.gamma) # 不显示核密度, 显示gamma曲线 plt.show()
2、sns.jointplot() 散点图
np.random.multivariate_normal 方法用于根据实际情况生成一个多元正态分布矩阵
numpy.random.multivariate_normal(mean, cov[, size, check_valid, tol])
- mean:均值,n维分布的平均值,是一个一维数组长度为N.在标准正态分布里对应的就是图形的峰值。
- cov:分布的协方差矩阵,它的形状必须是(n,n),也就是必须是一个行数和列数相等的类似正方形矩阵,它必须是对称的和正半定的,才能进行适当的采样。
- size:指定生成样本的大小,是一个int类型或者int类型的元组。可选。例如,给定(m,n,k)的形状,则会生成m*n*k样本,并按m-x-n-x-k排列打包。因为每个样本都是N维的,所以输出形状是(m,n,k,N)。如果未指定形状,则返回单个(N-d)样本。
- 在这里需要说明的是mean和cov必须有相同的长度,否则编译的时候会报错。比如mean=[0,0],cov=[[1,0,0],[0,1,0],[0,0,1]],这样是不可以的因为mean的长度为2,而cov的形状是(3,3),这样在编译的时候会产生一个ValueError: mean and cov must have same length错误。再结合size中的例子,如果size指定(3,3)的元组,mean=[1,2],cov=[[1,0],[0,100]],那么输出的形状就是(3,3,2).(例:若size=(1, 1, 2),则输出的矩阵的shape即形状为 1X1X2XN(N为mean的长度))。
- check_valid:可以为{'warn'、'raise'、'ignore'},可选,来指定协方差矩阵非正半定时的行为。
- tol:浮点型,可选。检查协方差矩阵中的奇异值时的公差。
x, y = np.random.multivariate_normal(mean, cov, 1000).T # kind:{ “scatter” | “kde” | “hist” | “hex” | “reg” | “resid” } # kind:{ “散点” | “核密度” | “方块” | “六边” | “线性回归” | “resid” } sns.jointplot(x=x, y=y, kind='hex') # 绿色 # sns.jointplot(x=x, y=y, color='g') sns.jointplot(x=x, y=y, color='g', kind='kde') sns.jointplot(x=x, y=y, color='g')
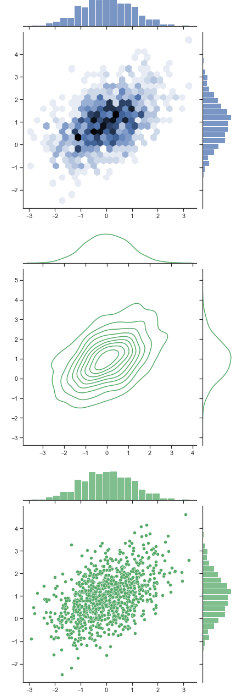
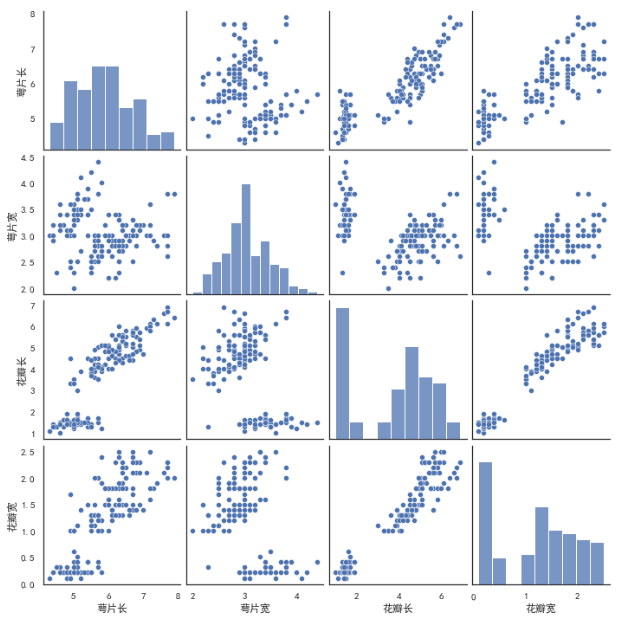
3、sns.pairplot() 多变量图
# sns.pairplot import pandas as pd from sklearn import datasets import seaborn as sns import matplotlib.pyplot as plt %matplotlib inline sns.set_style('white',{'font.sans-serif':['simhei','Arial']}) # 解决中文不能显示问题 # iris = sns.load_dataset("iris") # 数据导入方式1 iris = datasets.load_iris() # 数据导入方式2 # type(iris) # sklearn.utils.Bunch #print(iris.data[:3,:]) #print(iris.feature_names) # ['sepal length (cm)', 'sepal width (cm)', 'petal length (cm)', 'petal width (cm)'] #print(iris.target) # 种类:0,1,2 #print(iris.target_names) # ['setosa' 'versicolor' 'virginica'] iris_df = pd.DataFrame(iris.data, columns=iris.feature_names) iris_df['species'] = iris.target_names[iris.target] iris_df.rename(columns={ "sepal length (cm)":"萼片长", "sepal width (cm)":"萼片宽", "petal length (cm)":"花瓣长", "petal width (cm)":"花瓣宽", "species":"种类" }, inplace=True) kind_dict = { "setosa":"山鸢尾", "versicolor":"杂色鸢尾", "virginica":"维吉尼亚鸢尾" } iris_df['种类'] = iris_df['种类'].map(kind_dict)
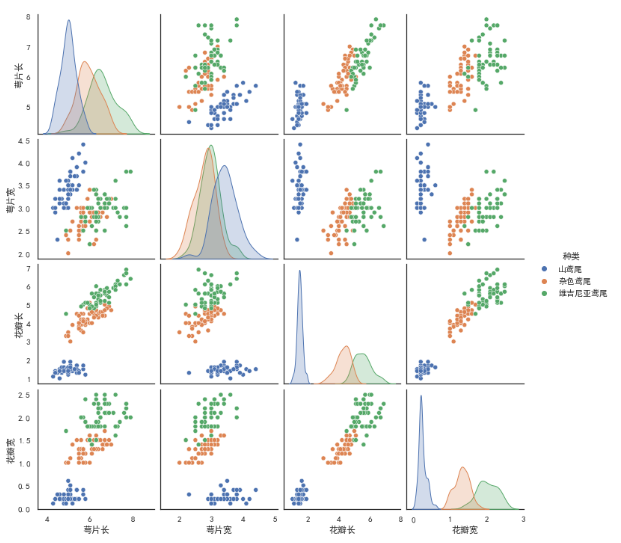
sns.pairplot(iris_df)
可以看到对角线上是各个属性的直方图(分布图),而非对角线上是两个不同属性之间的相关图,
从图中我们发现,花瓣的长度和宽度之间以及萼片的长短和花瓣的长、宽之间具有比较明显的相关关系
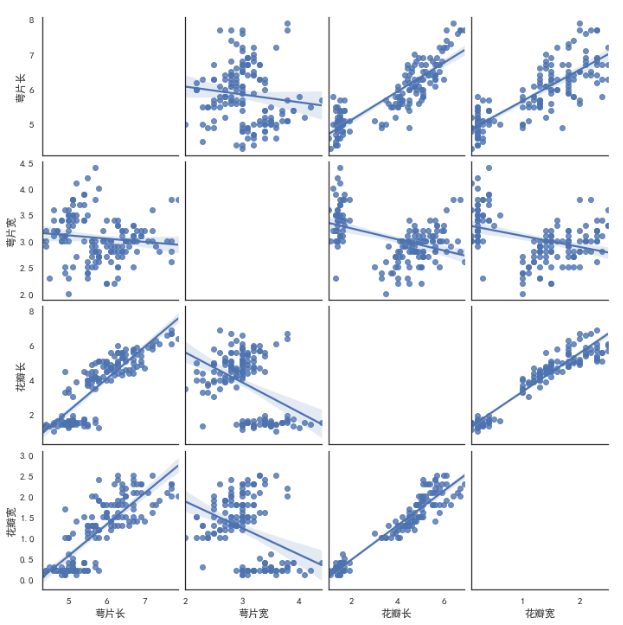
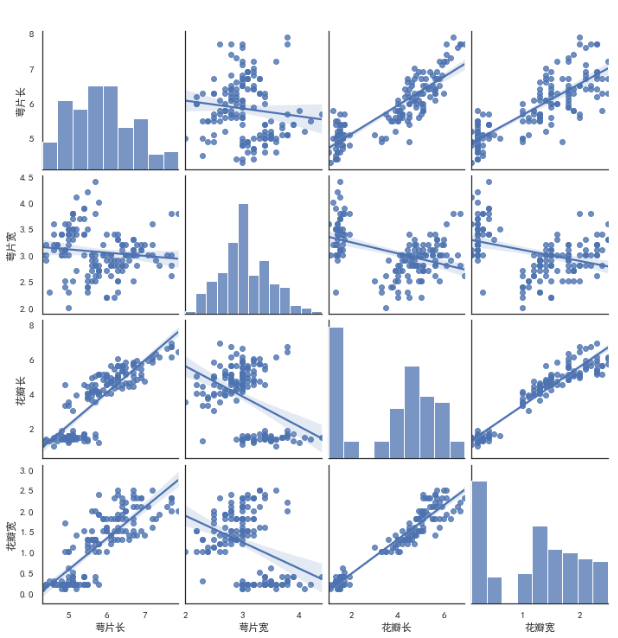
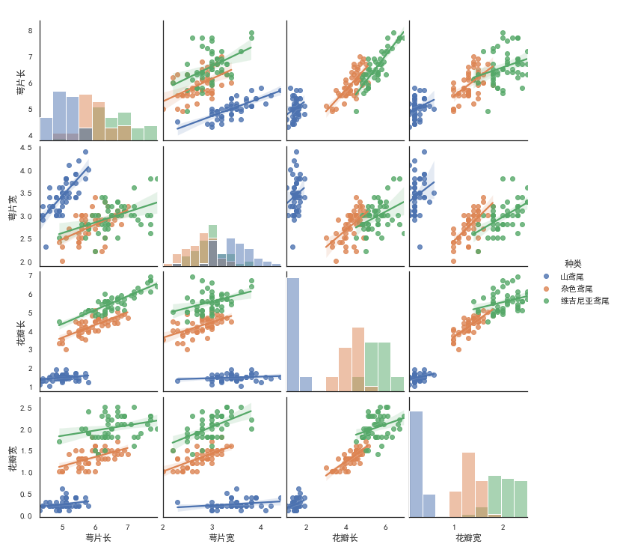
# kind: 用于控制非对角线上图的类型,可选'scatter'与'reg' # diag_kind:用于控制对角线上的图类型,可选'hist' 与 'kde' sns.pairplot(iris_df, kind='reg', diag_kind='ked') sns.pairplot(iris_df, kind='reg', diag_kind='hist')
# hue: 按指定字段进行分类 sns.pairplot(iris_df, hue='种类') sns.pairplot(iris_df, hue='种类', diag_kind='hist',kind='reg')
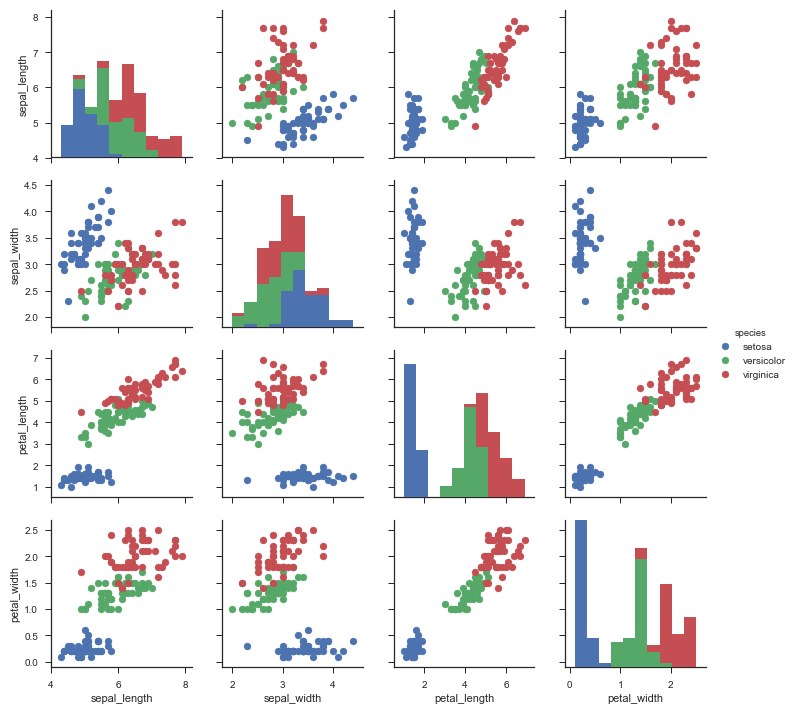
经过hue分类后的pairplot中发现,不论是从对角线上的分布图还是从分类后的散点图,
都可以看出对于不同种类的花,其萼片长、花瓣长、花瓣宽的分布差异较大,换句话说,
这些属性是可以帮助我们去识别不同种类的花的。
比如,对于萼片、花瓣长度较短,花瓣宽度较窄的花,那么它大概率是山鸢尾。
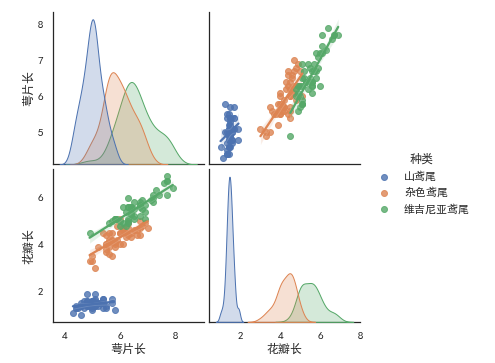
# vars:研究某2个或者多个变量之间的关系vars,
# x_vars,y_vars:选择数据中的特定字段,以list形式传入需要注意的是,x_vars和y_vars要同时指定
# vars: 研究某2个或者多个变量之间的关系。 # x_vars,y_vars: 选择数据中的特定字段,以list形式传入需要注意的是:x_vars和y_vars要同时指定 sns.pairplot(iris_df, vars=["萼片长","花瓣长"], hue='种类',kind='reg') sns.pairplot(iris_df,x_vars=["萼片长","花瓣宽"],y_vars=["萼片宽","花瓣长"],hue='种类',kind='reg')
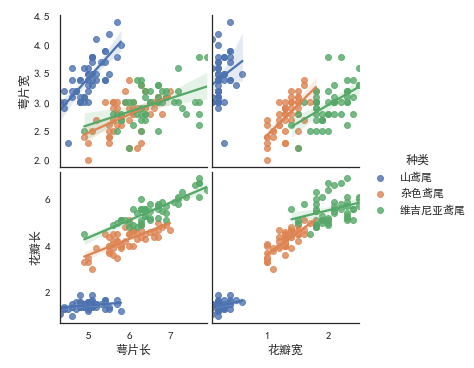
四、sns.heatmap() 变量关系热度图
import pandas as pd import numpy as np from sklearn.datasets import load_diabetes from sklearn.model_selection import train_test_split,RandomizedSearchCV from sklearn.metrics import accuracy_score,precision_score,recall_score,f1_score from sklearn.ensemble import RandomForestClassifier,AdaBoostClassifier import matplotlib.pyplot as plt from sklearn.svm import SVC import seaborn as sns sns.set(style='ticks') #import check_file as ch %matplotlib inline food_df = pd.read_csv('..//2-数据分析处理库pandas//food_info.csv') food_df = food_df.drop('Shrt_Desc', axis=1) food_df.head(1)
food_df.count() print(food_df.columns)
Index(['NDB_No', 'Water_(g)', 'Energ_Kcal', 'Protein_(g)', 'Lipid_Tot_(g)',
'Ash_(g)', 'Carbohydrt_(g)', 'Fiber_TD_(g)', 'Sugar_Tot_(g)',
'Calcium_(mg)', 'Iron_(mg)', 'Magnesium_(mg)', 'Phosphorus_(mg)',
'Potassium_(mg)', 'Sodium_(mg)', 'Zinc_(mg)', 'Copper_(mg)',
'Manganese_(mg)', 'Selenium_(mcg)', 'Vit_C_(mg)', 'Thiamin_(mg)',
'Riboflavin_(mg)', 'Niacin_(mg)', 'Vit_B6_(mg)', 'Vit_B12_(mcg)',
'Vit_A_IU', 'Vit_A_RAE', 'Vit_E_(mg)', 'Vit_D_mcg', 'Vit_D_IU',
'Vit_K_(mcg)', 'FA_Sat_(g)', 'FA_Mono_(g)', 'FA_Poly_(g)',
'Cholestrl_(mg)'],
dtype='object')
查看各个字段数据情况:非空总数,均值、标准差、最小值、1/4中位数、中位数、3/4中位数、最大值
food_df.describe()
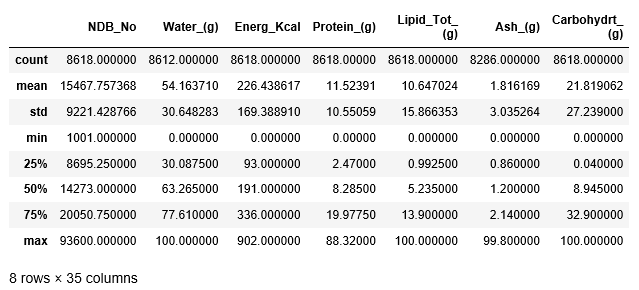
#food_df = food_df.drop('Shrt_Desc', axis=1) #food_df.head(1) cols = ['NDB_No','Water_(g)', 'Energ_Kcal', 'Protein_(g)'] sns.pairplot(food_df[cols]) plt.savefig('./pairplot01.png')
查看两两字段间的关系
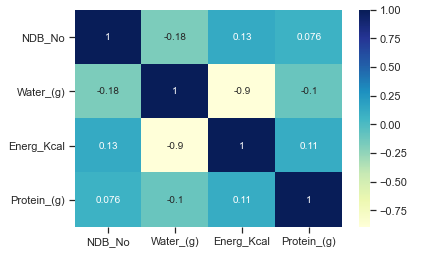
查看两两字段间的关系热度图
sns.heatmap(food_df[cols].corr(), annot=True, cmap='YlGnBu') plt.savefig('./heatmap01.png')
五、图表类别
%matplotlib inline import numpy as np import pandas as pd import matplotlib as mpl import matplotlib.pyplot as plt import seaborn as sns sns.set(style='whitegrid', color_codes=True) # D:pythonmlseaborn-data-master np.random.seed(sum(map(ord, 'categorical'))) # pandas的api: https://pandas.pydata.org/pandas-docs/stable/reference/io.html#excel titanic = pd.read_table('D:\python\ml\seaborn-data-master\titanic.csv',sep=',') tips = pd.read_csv('D:\python\ml\seaborn-data-master\tips.csv',sep=',') # seaborn的api网址:http://seaborn.pydata.org/api.html iris = sns.load_dataset('iris',data_home='D:\python\ml\seaborn-data-master')
1、 sns.tripplot() 分布散点图
jitter:当数据点重合较多时,该参数可打散数据
# sns.tripplot() 分布散点图,jitter:当数据点重合较多时,该参数可打散数据 sns.stripplot(x='day', y='total_bill', data=tips, jitter=False)
# sns.tripplot() 分布散点图,jitter:当数据点重合较多时,该参数可打散数据 sns.stripplot(x='day', y='total_bill', data=tips, jitter=True)
2、sns.swarmplot() 分簇散点图
# sns.swarmplot() 分簇散点图 sns.swarmplot(x='day', y='total_bill', hue='sex', data=tips)
# sns.swarmplot() 分簇散点图 sns.swarmplot(x='total_bill', y='day', hue='time', data=tips)
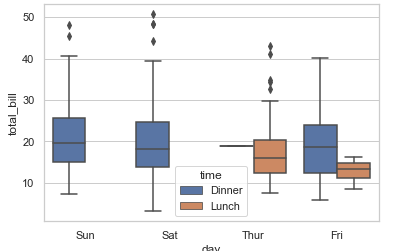
3、sns.boxplot() 箱线图

3.1.箱子的大小取决于数据的四分位距,即IQR = Q3 - Q1(Q3: 75%分位数 , Q1: 25%分位数 , Q3和Q1为四分位数)。50%的数据集中于箱体,若箱体太大即数据分布离散,数据波动较大,箱体小表示数据集中。
3.2.箱子的上边为上四分位数Q3,下边为下四分位数Q1,箱体中的横线为中位数Q2(50%分位数)
3.3.箱子的上触须为数据的最大值Max,下触须为数据的最小值Min(注意是非离群点的最大最小值,称为上下相邻值)
3.4.若数据值 > Q3+1.5 * IQR(上限值) 或 数据值 < Q1-1.5 * IQR(下限值) ,均视为异常值。数据值 > Q3+3 * IQR 或 数据值 < Q1-3 * IQR ,均视为极值。在实际应用中,不会显示异常值与极值的界限,而且一般统称为异常值。
- 也表明上下触须不一定是数据的最大最小值,
- (1)若数据的最大值比上限值小的,那么上触须顶点就是观察到的最大的;若数据的最大值比上限值大的,那么上触须顶点就是上限值,观察到的最大值就是异常点。
- (2)若数据的最小值比下限值大的,那么下触须顶点就是观察到的最小值;若数据的最小值比下限值小的,那么下触须顶点就是下限值,观察到的最小值就是异常点。
- 上述情况复杂,在线范围外的,直接理解成异常值即可
3.5.偏度:
- 对称分布:中位线在箱子中间,上下相邻值到箱子的距离等长,离群点在上下限值外的分布也大致相同。
- 右偏分布:中位数更靠近下四分位数,上相邻值到箱子的距离比下相邻值到箱子的距离长,离群点多数在上限值之外。
- 左偏分布:中位数更靠近上四分位数,下相邻值到箱子的距离比上相邻值到箱子的距离长,离群点多数在下限值之外。
# sns.boxplot() 箱线图 # IQR: 统计学概念,四分位距,第(1/4)分位与第(3/4)分位之间的距离 # N= 1.5 * IQR 如果一个值>Q3+N 或 <Q1-N,则为离群点 sns.boxplot(x='day', y='total_bill', hue='time', data=tips)
# sns.boxplot() 箱线图 # IQR: 统计学概念,四分位距,第(1/4)分位与第(3/4)分位之间的距离 # N= 1.5 * IQR 如果一个值>Q3+N 或 <Q1-N,则为离群点 sns.boxplot(x='day', y='total_bill', hue='time', data=tips)
# 箱线图 iris sns.boxplot(data=iris.data, orient='h')
4、violinplot() 小提琴图
小提琴图,其外围的曲线宽度代表数据点分布的密度,中间的箱线图则和普通箱线图表征的意义是一样的,代表着中位数、上下分位数、极差等。
# sns.violinplot() 小提琴图 # 小提琴图,其外围的曲线宽度代表数据点分布的密度, # 中间的箱线图则和普通箱线图表征的意义是一样的,代表着中位数、上下分位数、极差等。 sns.violinplot(x='total_bill', y='day', hue='time', data=tips)
# sns.violinplot() 小提琴图 # 小提琴图,其外围的曲线宽度代表数据点分布的密度, # 中间的箱线图则和普通箱线图表征的意义是一样的,代表着中位数、上下分位数、极差等。 plt.figure(figsize=(10,6)) sns.violinplot(x='total_bill', y='day', hue='time', data=tips)

# sns.violinplot() 小提琴图 plt.figure(figsize=(10,6)) sns.violinplot(x='day', y='total_bill', hue='sex', data=tips, split=True)

# 小提琴图 和 分簇散点图 # 不带装饰的小提琴图:inner=None sns.violinplot(x='day', y='total_bill', data=tips, inner=None) sns.swarmplot(x='day', y='total_bill', data=tips, color='w', alpha=0.6)
5、sns.barplot() 条形图
# 条形图 # 显示值的集中趋势可以用条形图 sns.barplot(x='Sex', y='Survived', hue='Pclass', data=titanic)
6、sns.pointplot() 点图
# sns.pointplot() 点图: 可以更好的描述一个类别的变化差异 sns.pointplot(x='Sex', y='Survived', hue='Pclass', data=titanic)
# 点图:palette调色盘; marker:'^'箭头标记,'o'圆点标记;linestyles:'-'虚线、'--'实线 sns.pointplot(x='Pclass', y='Survived', hue='Sex', data=titanic, palette={'male': 'g', 'female': 'm'}, markers=['^', 'o'], linestyles=['-', '--'])
7、sns.factorplot() 多层面板分类图
seaborn.factorplot(x=None, y=None, hue=None, data=None, row=None, col=None, col_wrap=None, estimator=, ci=95, n_boot=1000, units=None, order=None, hue_order=None, row_order=None, col_order=None, kind='point', size=4, aspect=1, orient=None, color=None, palette=None, legend=True, legend_out=True, sharex=True, sharey=True, margin_titles=False, facet_kws=None, **kwargs)
Parameters:¶
- x,y,hue 数据集变量 变量名
- date 数据集 数据集名
- row,col 更多分类变量进行平铺显示 变量名
- col_wrap 每行的最高平铺数 整数
- estimator 在每个分类中进行矢量到标量的映射 矢量
- ci 置信区间 浮点数或None
- n_boot 计算置信区间时使用的引导迭代次数 整数
- units 采样单元的标识符,用于执行多级引导和重复测量设计 数据变量或向量数据
- order, hue_order 对应排序列表 字符串列表
- row_order, col_order 对应排序列表 字符串列表
- kind : 可选:point 默认, bar 柱形图, count 频次, box 箱体, violin 提琴, strip 散点,swarm 分散点 size 每个面的高度(英寸) 标量 aspect 纵横比 标量 orient 方向 "v"/"h" color 颜色 matplotlib颜色 palette 调色板 seaborn颜色色板或字典 legend hue的信息面板 True/False legend_out 是否扩展图形,并将信息框绘制在中心右边 True/False share{x,y} 共享轴线 True/False
# order 指定坐标标签顺序
# sns.factorplot() 多层面板分类图:点图 # order 指定坐标标签顺序: order=['Thur','Fri','Sat','Sun'] sns.factorplot(x='day', y='total_bill', hue='smoker', data=tips, order=['Thur','Fri','Sat','Sun'])
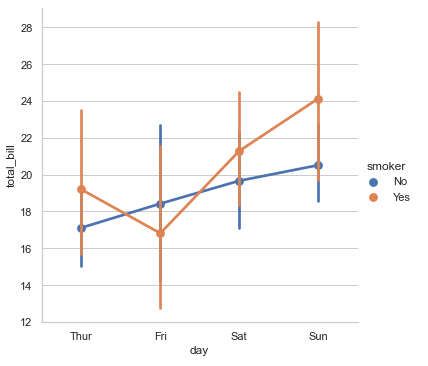
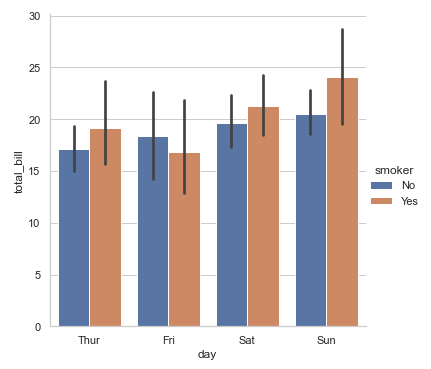
# 多层面板: 柱形图 sns.factorplot(x='day', y='total_bill', hue='smoker', data=tips, kind='bar',order=['Thur','Fri','Sat','Sun'])
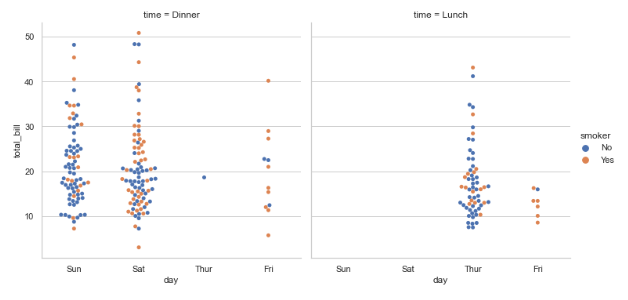
# 多层面板:分簇散点图swarm sns.factorplot(x='day', y='total_bill', hue='smoker', col='time', data=tips, kind='swarm')
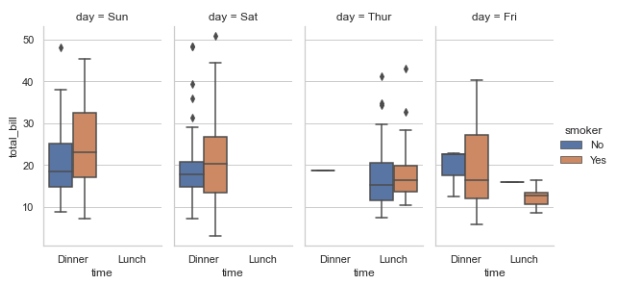
# 多层面板: 箱线图 sns.factorplot(x='time', y='total_bill', hue='smoker', col='day', data=tips, kind='box', size=4, aspect=.5)
8、sns.FacetGrid 多绘图网格
%matplotlib inline import numpy as np import pandas as pd import seaborn as sns from scipy import stats import matplotlib as mpl import matplotlib.pyplot as plt sns.set(style='ticks') np.random.seed(sum(map(ord, 'axis_grids')))
tips = sns.load_dataset('tips', data_home='D:\python\ml\seaborn-data-master') tips.head()
# sns.FacetGrid() 多绘图网格 sns.FacetGrid(tips, col='time')
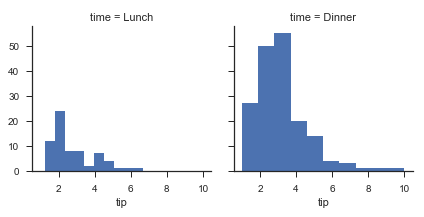
# sns.FacetGrid 多绘图网格 g = sns.FacetGrid(tips, col='time') g.map(plt.hist, 'tip')
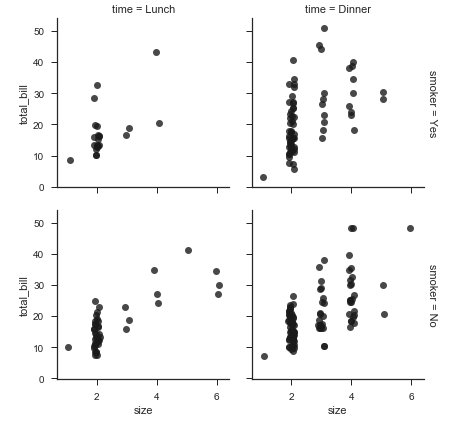
# sns.FacetGrid 多绘图网格: 散点图plt.scatter g = sns.FacetGrid(tips, col='sex', hue='smoker') # matplotlib.pyplot的aip:https://matplotlib.org/stable/api/pyplot_summary.html # plt.scatter: aplpha透明度 g.map(plt.scatter, 'total_bill', 'tip',alpha=.6)

# sns.FacetGrid 多绘图网格:sns.regplot 回归图 g = sns.FacetGrid(tips, row='smoker', col='time', margin_titles=True) g.map(sns.regplot, 'size', 'total_bill', color='.1', fit_reg=False, x_jitter=.1)
# sns.FacetGrid() 多绘图网格:直方图 sns.barplot g = sns.FacetGrid(tips, col='day', size=5, aspect=.4) g.map(sns.barplot, 'sex', 'total_bill')
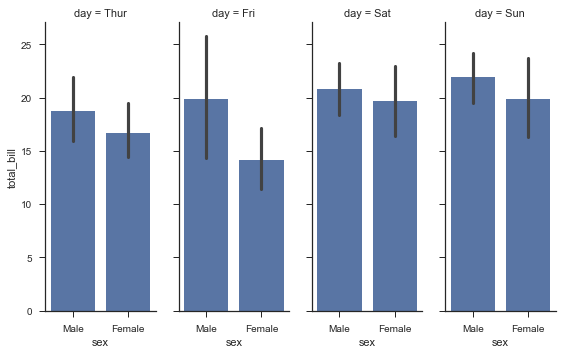
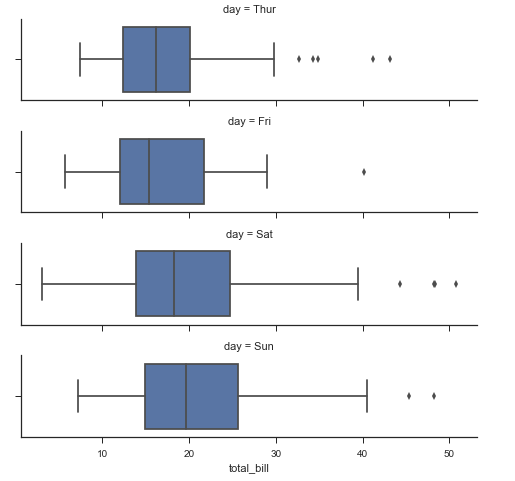
from pandas import Categorical ordered_days = tips.day.value_counts().index print(ordered_days) ordered_days = Categorical(['Thur', 'Fri', 'Sat', 'Sun']) # 自定义顺序 # sns.FacetGrid的api: http://seaborn.pydata.org/generated/seaborn.FacetGrid.html#seaborn.FacetGrid g = sns.FacetGrid(tips, row='day', row_order=ordered_days, size=1.7, aspect=4) # sns.boxplot箱线图:http://seaborn.pydata.org/generated/seaborn.boxplot.html#seaborn.boxplot g.map(sns.boxplot, 'total_bill')
CategoricalIndex(['Sat', 'Sun', 'Thur', 'Fri'], categories=['Thur', 'Fri', 'Sat', 'Sun'], ordered=False, dtype='category')
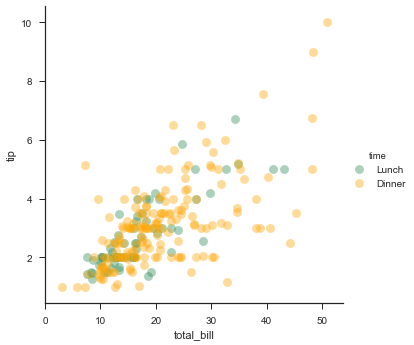
# 自定义调色板 pal = dict(Lunch='seagreen', Dinner='orange') # sns.FacetGrid的api: http://seaborn.pydata.org/generated/seaborn.FacetGrid.html#seaborn.FacetGrid g = sns.FacetGrid(tips, hue='time', palette=pal, size=5) # plt.scatter散点图:https://matplotlib.org/stable/api/pyplot_summary.html # 散点图x为total_bill,y为tip;透明度alpha, g.map(plt.scatter, 'total_bill', 'tip', s=80, alpha=.4, linewidth=.1, edgecolor='white') g.add_legend()
# sns.FacetGrid多绘图网格,按sex分类,palette定义调色,hue_kws定义分类的图案样式 g = sns.FacetGrid(tips, hue='sex', palette='Set1', size=5, hue_kws={'marker':['^', 'v']}) g.map(plt.scatter, 'total_bill', 'tip', s=100, linewidth=.7, edgecolor='white') g.add_legend()

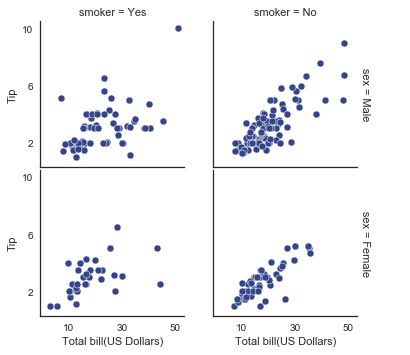
with sns.axes_style('white'): g = sns.FacetGrid(tips, row='sex',col='smoker',margin_titles=True,size=2.5) g.map(plt.scatter, 'total_bill', 'tip', color='#334488', edgecolor='white', lw=.5) # g.set_axis_labels 设置x,y轴名称 g.set_axis_labels('Total bill(US Dollars)', 'Tip') # g.set(xticks, yticks) 设置x,y轴的刻度 g.set(xticks=[10,30,50], yticks=[2,6,10]) # fig.subplots_adjust 调整子图参数 g.fig.subplots_adjust(wspace=.2, hspace=.02, left=.09)
9、sns.PairGrid多变量关系绘图网格
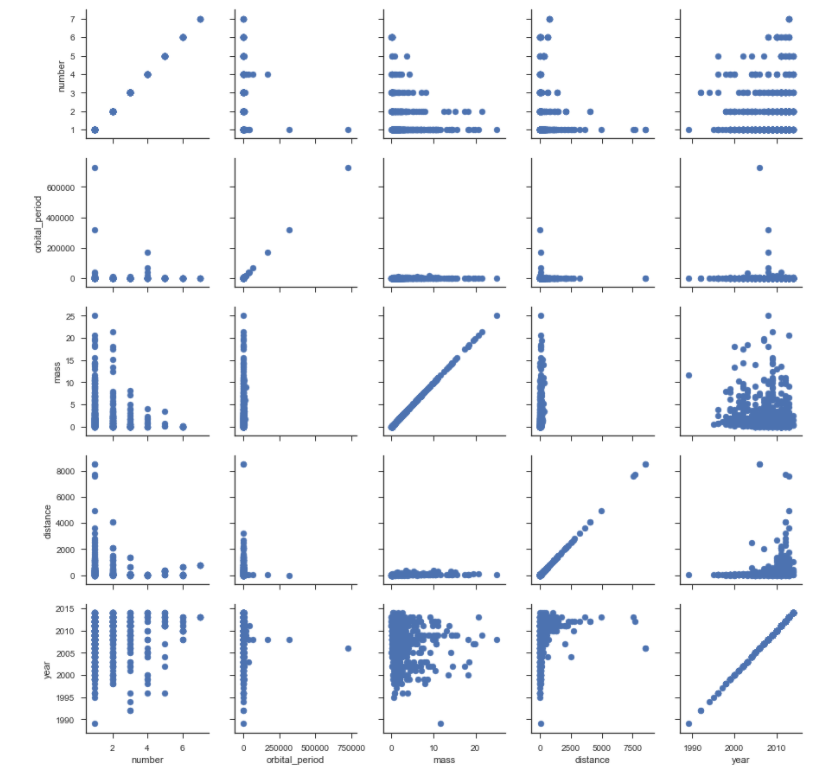
planets = sns.load_dataset('planets', data_home='D:\python\ml\seaborn-data-master\') g = sns.PairGrid(planets) g.map(plt.scatter)
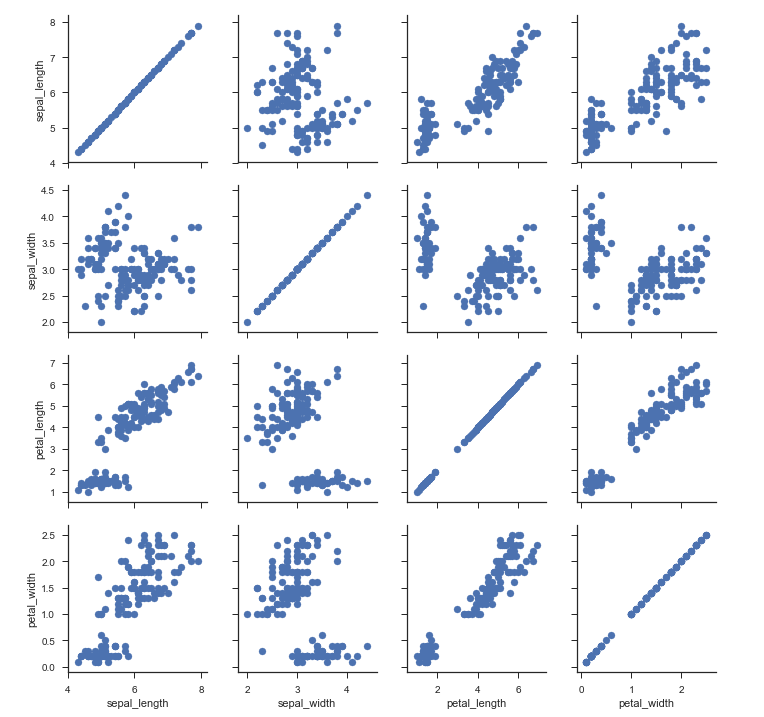
iris = sns.load_dataset('iris', data_home='D:\python\ml\seaborn-data-master\') g = sns.PairGrid(iris) g.map(plt.scatter)
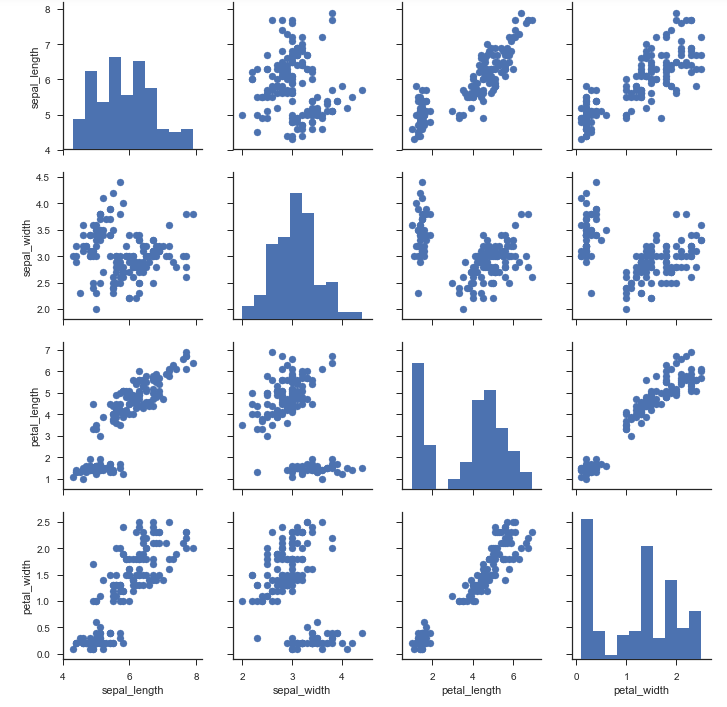
# sns.PairGrid绘制成对关系图: 用iris数据集,绘制成对关系子图 g = sns.PairGrid(iris) # g.map_diag 对角线上画图: plt.hist直方图 g.map_diag(plt.hist) # g.map_offdiag 非对角线上画图: plt.scatter散点图 g.map_offdiag(plt.scatter)
# sns.PairGrid绘制成对关系子图:用iris数据集,绘制成对关系图,用species分类 g = sns.PairGrid(iris, hue='species') # g.map_diag在对角线上绘图: 直方图plt.hist g.map_diag(plt.hist) # g.map_offdiag在非对角线上绘图:散点图plt.scatter g.map_offdiag(plt.scatter) # g.add_legend() 显示分类注解 g.add_legend()
# sns.PairGrid绘制成对关系子图:数据集iris的['sepal_length', 'sepal_width']属性对,分类hue g = sns.PairGrid(iris, vars=['sepal_length', 'sepal_width'], hue='species') # g.map绘图:plt.scatter散点图 g.map(plt.scatter)
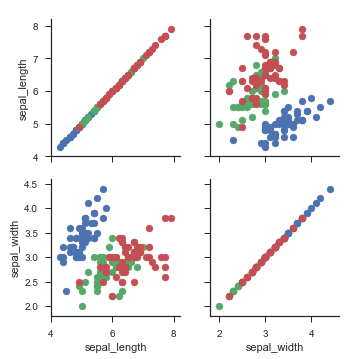
# sns.PairGrid绘制成对关系子图:tips数据集,按size分类,调色板GnBu_d g = sns.PairGrid(tips, hue='size', palette='GnBu_d') # g.map绘图:plt.scatter散点图 # plt.scatter的参数:https://matplotlib.org/stable/api/_as_gen/matplotlib.pyplot.scatter.html#matplotlib.pyplot.scatter g.map(plt.scatter, s=50, edgecolor='red') g.add_legend()

10、sns.heatmap热力图
%matplotlib inline import matplotlib.pyplot as plt import numpy as np np.random.seed(331) import seaborn as sns sns.set() uniform_data = np.random.rand(3,3) print(uniform_data)
# 安数组[n,m]的值显示颜色 heatmap = sns.heatmap(uniform_data)
[[0.94667182 0.1159915 0.703641 ] [0.19201418 0.88967771 0.608804 ] [0.93697966 0.83787054 0.55610899]]
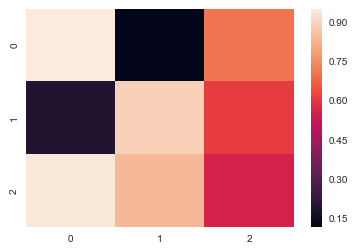
# sns.load_dataset() 加载数据到df flights = sns.load_dataset('flights',data_home='D:\python\ml\seaborn-data-master') flights.head()
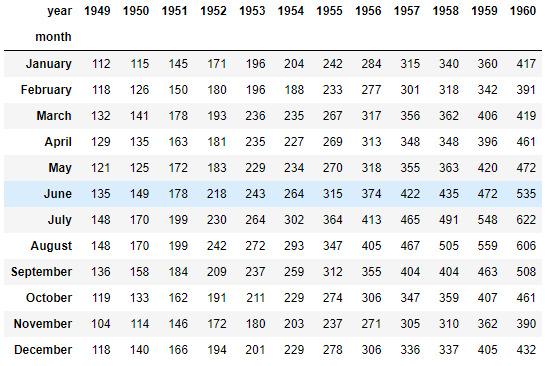
flights = sns.load_dataset('flights',data_home='D:\python\ml\seaborn-data-master') # flights[cols] # 透视表 df.pivot('index', 'columns', 'values') 透视表 # https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.pivot.html flights = flights.pivot('month', 'year', 'passengers') flights
# seaborn.heatmap热力图API: # http://seaborn.pydata.org/generated/seaborn.heatmap.html#seaborn.heatmap ax = sns.heatmap(flights)
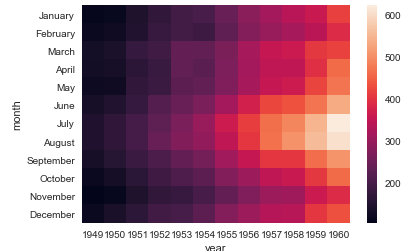
# sns.heatmap 热力图: annot=True显示各个cell数值,fmt设置字体格式 sns.heatmap(flights, annot=True, fmt='d')

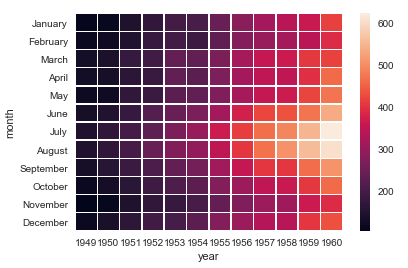
# sns.heatmap(flights, linewidths=.5) 热力图设置分割线粗细 sns.heatmap(flights, linewidths=.5)
2. 颜色效果cmap的参数如下: Accent, Accent_r, Blues, Blues_r, BrBG, BrBG_r, BuGn, BuGn_r, BuPu, BuPu_r, CMRmap, CMRmap_r, Dark2, Dark2_r, GnBu(绿到蓝), GnBu_r, Greens, Greens_r, Greys, Greys_r, OrRd(橘色到红色), OrRd_r, Oranges, Oranges_r, PRGn, PRGn_r, Paired, Paired_r, Pastel1, Pastel1_r, Pastel2, Pastel2_r, PiYG, PiYG_r, PuBu, PuBuGn, PuBuGn_r, PuBu_r, PuOr, PuOr_r, PuRd, PuRd_r, Purples, Purples_r, RdBu, RdBu_r, RdGy, RdGy_r, RdPu, RdPu_r, RdYlBu, RdYlBu_r, RdYlGn, RdYlGn_r, Reds, Reds_r, Set1, Set1_r, Set2, Set2_r, Set3, Set3_r, Spectral, Spectral_r, Wistia(蓝绿黄), Wistia_r, YlGn, YlGnBu, YlGnBu_r, YlGn_r, YlOrBr, YlOrBr_r, YlOrRd(红橙黄), YlOrRd_r, afmhot, afmhot_r, autumn, autumn_r, binary, binary_r, bone, bone_r, brg, brg_r, bwr, bwr_r, cividis, cividis_r, cool, cool_r, coolwarm(蓝到红), coolwarm_r, copper(铜色), copper_r, cubehelix, cubehelix_r, flag, flag_r, gist_earth, gist_earth_r, gist_gray, gist_gray_r, gist_heat, gist_heat_r, gist_ncar, gist_ncar_r, gist_rainbow, gist_rainbow_r, gist_stern, gist_stern_r, gist_yarg, gist_yarg_r, gnuplot, gnuplot2, gnuplot2_r, gnuplot_r, gray, gray_r, hot, hot_r(红黄), hsv, hsv_r, icefire, icefire_r, inferno, inferno_r, jet, jet_r, magma, magma_r, mako, mako_r, nipy_spectral, nipy_spectral_r, ocean, ocean_r, pink, pink_r, plasma, plasma_r, prism, prism_r, rainbow, rainbow_r, rocket, rocket_r, seismic, seismic_r, spring, spring_r, summer (黄到绿), summer_r (绿到黄), tab10, tab10_r, tab20, tab20_r, tab20b, tab20b_r, tab20c, tab20c_r, terrain, terrain_r, twilight, twilight_r, twilight_shifted, twilight_shifted_r, viridis, viridis_r, vlag, vlag_r, winter, winter_r |
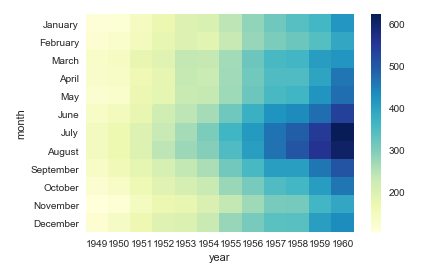
# sns.heatmap 热力图,设置调色盘 cmap # 颜色空间介绍:https://blog.csdn.net/ztf312/article/details/102474190 sns.heatmap(flights, cmap='YlGnBu')
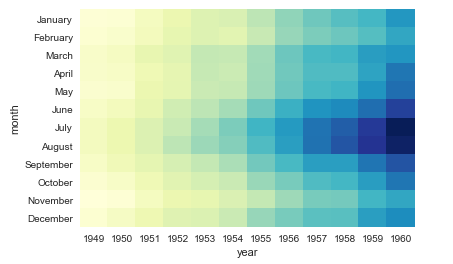
#sns.heatmap热力图: cbar是否显示颜色条 sns.heatmap(flights, cbar=False, cmap='YlGnBu')
11、sns.tsplot时间序列分析图
# help(seaborn.tsplot) # seaborn.timeseries模块下的tsplot时间序列分析图 %matplotlib inline import numpy as np import pandas as pd import seaborn as sns np.random.seed(22) # help(np.linspace) # np.linspace(start,stop,num)指定间隔内的均匀间隔的数字。 x = np.linspace(0, 15, 31) x
array([ 0. , 0.5, 1. , 1.5, 2. , 2.5, 3. , 3.5, 4. , 4.5, 5. ,
5.5, 6. , 6.5, 7. , 7.5, 8. , 8.5, 9. , 9.5, 10. , 10.5,
11. , 11.5, 12. , 12.5, 13. , 13.5, 14. , 14.5, 15. ])
data = np.sin(x) + np.random.rand(10,31) + np.random.randn(10, 1)
data
array([[ 0.6726167 , 1.42526277, 1.72616519, 2.32083315, 1.54461515,
1.40149227, 0.87580901, 0.80441429, -0.07224181, 0.29857697,
-0.48424123, 0.31981954, 0.99846686, 1.42437645, 1.31025412,
1.40829701, 2.22555828, 2.22047545, 1.57821254, 0.68658331,
0.6881278 , 0.27267873, -0.14865056, 0.20390982, 0.35513849,
0.98212391, 1.58695872, 1.37983576, 2.37803345, 2.3879375 ,
1.79185478],
.........
[ 2.75843589, 3.02276048, 3.64803647, 3.2642171 , 3.67946998,
3.74785894, 3.17628364, 2.70551084, 1.66156679, 2.19246399,
1.62189055, 1.60772731, 1.97773633, 2.89555072, 3.39132847,
3.1445841 , 3.75955263, 3.05460622, 2.76118641, 2.38280821,
2.22139674, 2.04374881, 1.87766694, 1.96670548, 2.05080123,
2.57914958, 3.18484661, 3.32652216, 4.02001749, 3.91133834,
3.13133477]])
# 查看sns.tsplot时间序列分析图手册 help(sns.tsplot)
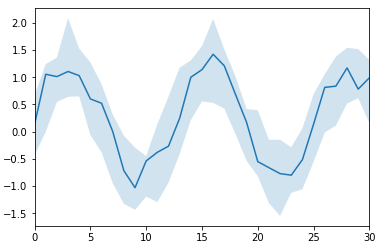
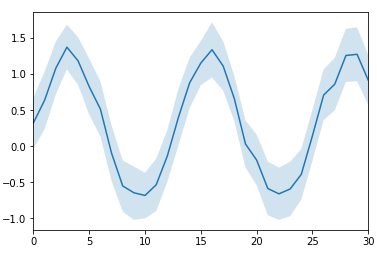
# sns.tsplot sns.tsplot(data=data)
gammas = sns.load_dataset('gammas', data_home='D:\python\ml\seaborn-data-master') gammas.head()
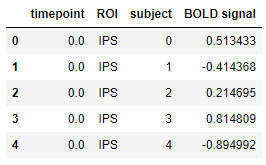
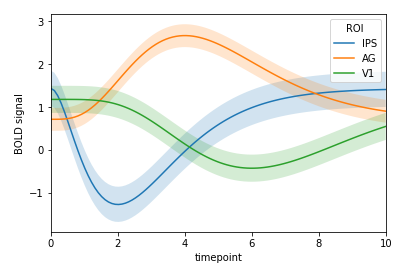
# help(sns.tsplot) 查看具体参数含义 sns.tsplot(time='timepoint', value='BOLD signal', unit='subject', condition='ROI',data=gammas)
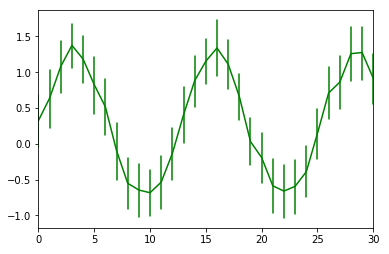
# sns.tsplot时间序列图:err_style不确定区间样式 #{ci_band, ci_bars, boot_traces, boot_kde, unit_traces, unit_points} ax = sns.tsplot(data=data, err_style='ci_bars', color='g')
ax = sns.tsplot(data=data, err_style='boot_traces', n_boot=500)

ax = sns.tsplot(data=data, err_style='unit_traces')
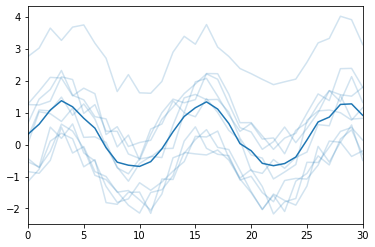
# interpolate是否显示连线 ax = sns.tsplot(data=data, err_style='ci_bars', interpolate=False)
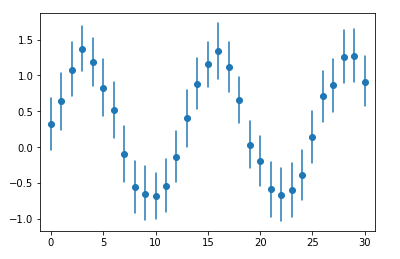
#
ax = sns.tsplot(data=data, estimator=np.median)