pandas是python的第三方库所以使用前需要安装一下,直接使用pip install pandas 就会自动安装pandas以及相关组件。
1、Series模块
1.1 Series的索引默认是从 0 开始的整数。
from pandas import Series import pandas as pd s = Series([1,4,'ww','tt']) s.index # RangeIndex(start=0, stop=4, step=1) s.values # array([1, 4, 'ww', 'tt'], dtype=object) s
0 1 1 4 2 ww 3 tt dtype: object
1.2 Series 可以自定义索引:
s2 = Series(['wangxing','man',24],index=['name','sex','age']) s2
name wangxing sex man age 24 dtype: object
1.3 Series值引用
s2['name'] # 'wangxing' s2['sex'] # 'man' s2['age'] # 24
1.4 传入字典,定义Series的索引与值
# 传入字典,定义Series的索引与值 sd = {'python':9000,'c++':9001,'c#':9000} # s3 = Series(sd) s3 = Series({'python':9000,'c++':9001,'c#':9000}) s3
python 9000 c++ 9001 c# 9000 dtype: int64
1.5 索引“自动对齐”:如果自定义了索引,自定的索引会自动寻找原来的索引,如果一样的,就取原来索引对应的值
如果没有值(null),都对齐赋给 NaN
sd = {'python':9000,'c++':9001,'c#':9000}
# 如果没有值(null),都对齐赋给 NaN
s4 = Series(sd, index=['java','c++','c#'])
s4
java NaN c++ 9001.0 c# 9000.0 dtype: float64
1.6 Pandas 有专门的方法来判断值是否为空 Series 对象也有同样的方法
#pd.isnull(s4) s4.isnull()
java True c++ False c# False dtype: bool
2、DataFrame
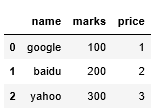
from pandas import Series,DataFrame data = {"name":['google','baidu','yahoo'],"marks":[100,200,300],"price":[1,2,3]} f1 = DataFrame(data) # 按照惯例默认索引就是从 0 开始的整数 f1
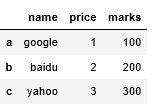
# DataFrame 中,columns 其顺序可以被规定 # 且 DataFrame 数据的索引也能够自定义 f2 = DataFrame(data,columns=['name','price','marks'], index=['a','b','c']) f2
2.1 pandas.read_csv() 从文件中读取数据,生成DataFrame
import pandas # 从文件中读取数据,生成DataFrame food_info=pandas.read_csv("G:\python\库应用(4个)\2-数据分析处理库pandas\food_info.csv")
2.1.1 pd.to_datetime() 将int、float、str、datetime类型等数据转换为datetime
import pandas as pd unrate = pd.read_csv('unrate.csv') # pd.to_datetime() 将int、float、str、datetime类型等数据转换为datetime unrate['DATE'] = pd.to_datetime(unrate['DATE']) help(pd.to_datetime) #unrate.head(12)
2.2 df.head(2) 头部2行的数据
# 打印头1行数据 food_info.head(1)
2.3 food_info.columns获取DataFrame的列名
# 获取DataFrame的所有列名 col_names = food_info.columns.tolist() col_names
2.4 访问"Iron_(mg)"列的第[6]位数据 / 访问"Iron_(mg)"列的[2,6,8]位数据
# 访问"Iron_(mg)"列的第[6]位数据 food_info["Iron_(mg)"][6] # 访问"Iron_(mg)"列的[2,6,8]位数据 food_info["Iron_(mg)"][[2,6,8]]
2.5 DataFrame的加、减、乘、除
# DataFrame的加、减、乘、除 # food_info["Iron_(mg)"] / 1000 div_1000 = food_info["Iron_(mg)"] / 1000 add_100 = food_info["Iron_(mg)"] + 100 sub_100 = food_info["Iron_(mg)"] - 100 mult_2 = food_info["Iron_(mg)"] * 2 water_energy = food_info["Water_(g)"] * food_info["Energ_Kcal"]
# 通过蛋白质和脂肪,计算失误的评分,评分公式:Score=2×(Protein_(g))−0.75×(Lipid_Tot_(g)) weighted_protein = food_info["Protein_(g)"] * 2 weighted_fat = -0.75 * food_info["Lipid_Tot_(g)"] initial_rating = weighted_protein + weighted_fat initial_rating
#“Vit_A_IU”列的范围从0到100000,而“Fiber_TD_(g)”列的范围从0到79 #对于某些计算,因为值的规模,像“Vit_A_IU”这样的列对结果有更大的影响 # "Energ_Kcal"列的最大值 max_calories = food_info["Energ_Kcal"].max() # 902 # 标准化:"Energ_Kcal"列除以该列最大值 normalized_calories = food_info["Energ_Kcal"] / max_calories normalized_protein = food_info["Protein_(g)"] / food_info["Protein_(g)"].max() normalized_fat = food_info["Lipid_Tot_(g)"] / food_info["Lipid_Tot_(g)"].max() # 新增特征:“Normalized_Protein”和“Normalized_Fat” food_info["Normalized_Protein"] = normalized_protein food_info["Normalized_Fat"] = normalized_fat
2.6 DataFrame新增和修改列
# DataFrame增加新column food_info["water_energy"] = water_energy # Iron单位mg转换为g iron_grams = food_info["Iron_(mg)"] / 1000 # 增加列"Iron_(g)" food_info["Iron_(g)"] = iron_grams food_info["Iron_(g)"]
2.7 df.sort_values()排序
# 默认情况下,pandas将按我们指定的列升序排列数据,并返回一个新的DataFrame # inplace参数,是否自排序DataFrame,而不返回新DataFrame # inplace=False,非自排序,返回新DataFrame # a = food_info.sort_values("Sodium_(mg)",inplace=False) # inplace=True,自排序,不返回新DataFrame food_info.sort_values("Sodium_(mg)",inplace=True) # ascending=False,升序等于False,即降序 food_info.sort_values("Sodium_(mg)",inplace=True,ascending=False) # 降序
2.8 type() 查看数据类型
type(food_info) # pandas.core.frame.DataFrame print(type(food_info)) # <class 'pandas.core.frame.DataFrame'> #print (food_info.dtypes) # 所有columns的数据类型
2.9 DataFrame行、列访问
# df.loc[] DataFrame行访问 # df.loc[3:6] 访问df的[3-6行] food_info.loc[3:6] # df.loc[[3,7,9]] 访问列表[]中的行:3,7,9行 food_info.loc[[3,7,9]] # df[["Zinc_(mg)", "Copper_(mg)"]]列访问 food_info[["Zinc_(mg)", "Copper_(mg)"]] # 访问列表[]中的行:3,7,9行,["Shrt_Desc","Water_(g)","Energ_Kcal"]列 #food_info.loc[[3,7,9]][["Shrt_Desc","Water_(g)","Energ_Kcal"]]
# 访问885行Age的值 row_index_885_age = titanic_survival.loc[885,"Age"] # 39.0 row_index_885_age # 访问886行Pclass的值 titanic_survival.loc[886,"Pclass"]
2.10 DataFrame查看头3行,所有单位为(g)的列数据
# 查看头3行,所有单位为(g)的列数据 col_names = food_info.columns.tolist() gram_columns = [] for c in col_names: if c.endswith("(g)"): gram_columns.append(c) food_info[gram_columns].head(3)
food_info.head(1) food_info.loc[[0,2,4]] food_info.loc[0:3]
2.11 泰坦尼克号数据试验
2.11.1 所有age为null的值被选择出来
# 泰坦尼克号数据试验 import pandas as pd import numpy as np titanic_survival = pd.read_csv("titanic_train.csv") titanic_survival.head() null_indexs = pd.isnull(titanic_survival)["Age"] null_df = titanic_survival[null_indexs]["Age"] null_df # age = titanic_survival["Age"] age.loc[0:22] type(age) # pandas.core.series.Series age_is_null = pd.isnull(age) age_is_null type(age_is_null) # pandas.core.series.Series # 所有age为null的值被选择出来 age_null_true = age[age_is_null] age_null_true # Name: Age, Length: 177, dtype: float64 age_null_count = len(age_null_true) age_null_count # 177
行列访问
# 访问885行Age的值 row_index_885_age = titanic_survival.loc[885,"Age"] # 39.0 row_index_885_age # 访问886行Pclass的值 titanic_survival.loc[886,"Pclass"]
2.11.2 python内置函数,进行数学运算时,一旦任意一个值为NaN,则结果为NaN
# 进行数学运算时,一旦任意一个值为NaN,则结果为NaN mean_age = sum(titanic_survival['Age']) / len(titanic_survival['Age']) # sum函数,返回NaN # pandas的sum方法自动过滤null,正常 #mean_age = titanic_survival['Age'].sum() / len(titanic_survival['Age']) mean_age # 人工筛选出非空age good_ages = titanic_survival['Age'][age_is_null == False] good_ages correct_mean_age = sum(good_ages) / len(good_ages) correct_mean_age # pandas自带的数学运算方法,可以自动过滤掉空值 correct_mean_age = titanic_survival["Age"].mean() correct_mean_age
2.11.3 泰坦尼克号之均值
# 按类,求fare的均值 # 数据可按“Pclass”列,分为3类:1,2,3 passenger_classes = [1, 2, 3] fares_by_class = {} for this_class in passenger_classes: # 按“Pclass”依次取出1,2,3类数据 pclass_rows = titanic_survival[titanic_survival["Pclass"] == this_class] # 取出“Fare”列的数据 pclasses_fares = pclass_rows["Fare"] # pandas内部数学函数mean求均值 fare_for_class = pclasses_fares.mean() # 将不同类的均值,添加进字典fares_by_class fares_by_class[this_class] = fare_for_class fares_by_class # {1: 84.15468749999992, 2: 20.66218315217391, 3: 13.675550101832997}
#help(titanic_survival.pivot_table) # Pclass三类人获救的概率均值 passenger_survival = titanic_survival.pivot_table(index="Pclass",values="Survived",aggfunc=np.mean) passenger_survival # Pclass三类人年纪均值 passenger_age = titanic_survival.pivot_table(index="Pclass",values="Age") # aggfunc默认为mean求均值 passenger_age # 按Embarked分组,求和Fare和Survived两列 port_stats = titanic_survival.pivot_table(index="Embarked", values=["Fare","Survived"], aggfunc=np.sum) port_stats
2.11.4 df.dropna() 移除缺失的值
# df.dropna() 移除缺失的值 # 指定axis=1或axis='columns'将删除任何具有null值的列 # 指定axis=0或axis='index'将删除任何具有null值的行,默认0 titanic_survival.dropna(axis=1) # 'Age','Sex'两列不为空的所有行 titanic_survival.dropna(axis=0, subset=['Age','Sex']) #titanic_survival.dropna(axis=0) #help(titanic_survival.dropna)
2.11.5 df.sort_values() 对DataFrame进行排序,按Age降序排列
# df.sort_values() 对DataFrame进行排序,按Age降序排列 new_titanic_survival = titanic_survival.sort_values("Age", ascending=False) # reset_index 重置新DataFrame的索引 new_titanic_survival.reset_index(drop=True) # 索引从0开始自然递增 #help(new_titanic_survival.reset_index)
2.11.6 DataFrame.apply( func ) 函数应用于每列或每行,执行自定义函数func
# hundredth_row函数返回Series序列的第一百项 def hundredth_row(column): #提取第一百项 hundredth_item = column.iloc[99] return hundredth_item # df.apply(func)函数应用于每列或每行,执行自定义函数func。 # 返回每一列的第一百项 hundredth_row = titanic_survival.apply(hundredth_row) hundredth_row #help(titanic_survival.apply)
# 每列非空总数 def not_null_count(column): column_null = pd.isnull(column) not_null = column[column_null == False] return len(not_null) column_null_count = titanic_survival.apply(not_null_count) column_null_count
# df.apply(func,axis=1) #通过传入axis=1参数,我们可以使用DataFrame.apply()方法遍历行而不是列。 # 1、根据Pclass的值进行分类 def which_class(row): pclass = row['Pclass'] if pd.isnull(pclass): # pclass为空,则返回Unknown return "Unknown" elif pclass == 1: return "First Class" elif pclass == 2: return "Second Class" elif pclass == 3: return "Third Class" classes = titanic_survival.apply(which_class, axis=1) classes
# df.apply(func,axis=1) #通过传入axis=1参数,我们可以使用DataFrame.apply()方法遍历行而不是列。 # 2、根据年龄判断是否成年 def is_minor(row): if row["Age"] < 18: return True else: return False titanic_survival.apply(is_minor, axis=1) def generate_age_label(row): age = row["Age"] if pd.isnull(age): return "unknown" elif age < 18: return "minor" else : return "adult" age_labels = titanic_survival.apply(generate_age_label, axis=1) # titanic_survival添加“age_labels”列 titanic_survival['age_labels'] = age_labels titanic_survival.pivot_table(index="age_labels", values="Survived")
2.12 电影评分
2.12.1 pandas.read_csv()从文件生成DataFrame
#FILM - film name #RottenTomatoes - Rotten Tomatoes 影评人的平均得分 #RottenTomatoes_User - Rotten Tomatoes 用户平均得分 #RT_norm - Rotten Tomatoes 影评人的平均得分(归一化为0 - 5分) #RT_user_norm - Rotten Tomatoes 用户平均得分(归一化到0 - 5分系统) #Metacritic - Metacritic 评论家的平均得分 #Metacritic_User - Metacritic 用户的平均得分 import pandas as pd #从csv文件中读取数据,生成DataFrame fandango = pd.read_csv('G:\python\库应用(4个)\3-可视化库matpltlib\fandango_scores.csv') #读取'FILM'列的[0~5)的值 fandango['FILM'][0:5] #访问'RottenTomatoes'列的[0~5)的值 fandango['RottenTomatoes'][0:5]
2.13 Series的使用示例
from pandas import Series # 从DataFrame中获取series:“FILM”列,得到Series film_series = fandango['FILM'] # series.values属性,获取所有值列表 film_names = film_series.values # type(film_names) 返回numpy.ndarray type(film_names) rt_series = fandango['RottenTomatoes'] rt_scores = rt_series.values # type(rt_scores) 返回numpy.ndarray type(rt_scores) # 构建Series,值为rt_scores,索引为film_names custom_series = Series(rt_scores, index=film_names) # 通过数字进行访问 custom_series[[3,5,8]] # 通过索引名进行访问 custom_series[['Minions (2015)', 'Leviathan (2014)']] # series.index属性,获取所有值列表 type(custom_series.index) # pandas.core.indexes.base.Index type(custom_series.index.tolist()) # list original_index = custom_series.index.tolist() # sorted(iterable)内置函数,对list进行排序 sorted_index = sorted(original_index) #help(custom_series.reindex) # series.reindex(index_arr_like)重置series的索引 sorted_by_index = custom_series.reindex(sorted_index) # series按索引排序sort_index、按值排序sort_values custom_series.sort_index() custom_series.sort_values() np.add(custom_series,custom_series) # 等同于 custom_series + custom_series np.sin(custom_series) np.max(custom_series) custom_series > 98 greater_than_98_series = custom_series[custom_series > 98] condition_one = custom_series > 60 condition_two = custom_series < 66 custom_series[condition_one & condition_two]