一、前述
经过之前的训练数据的构建可以得到所有特征值为1的模型文件,本文将继续构建训练数据特征并构建模型。
二、详细流程
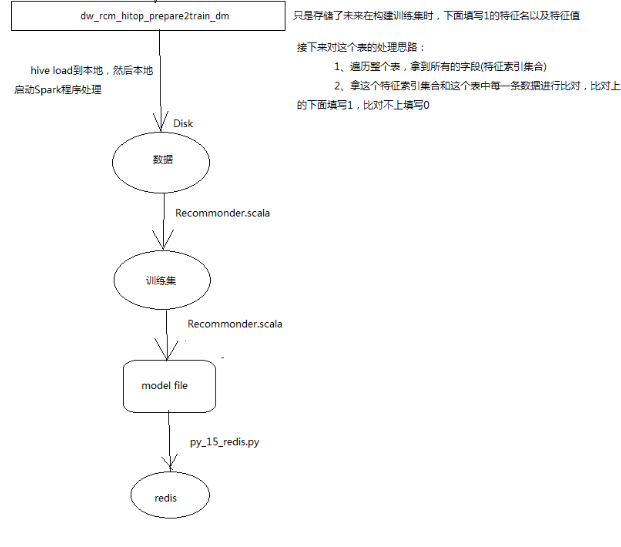
将处理完成后的训练数据导出用做线下训练的源数据(可以用Spark_Sql对数据进行处理)
insert overwrite local directory '/opt/data/traindata' row format delimited fields terminated by ' ' select * from dw_rcm_hitop_prepare2train_dm;
注:这里是将数据导出到本地,方便后面再本地模式跑数据,导出模型数据。这里是方便演示真正的生产环境是直接用脚本提交spark任务,从hdfs取数据结果仍然在hdfs,再用ETL工具将训练的模型结果文件输出到web项目的文件目录下,用来做新的模型,web项目设置了定时更新模型文件,每天按时读取新模型文件
三、代码详解
package com.bjsxt.data
import java.io.PrintWriter
import org.apache.log4j.{ Level, Logger }
import org.apache.spark.mllib.classification.{ LogisticRegressionWithLBFGS, LogisticRegressionModel, LogisticRegressionWithSGD }
import org.apache.spark.mllib.linalg.SparseVector
import org.apache.spark.mllib.optimization.SquaredL2Updater
import org.apache.spark.mllib.regression.LabeledPoint
import org.apache.spark.mllib.util.MLUtils
import org.apache.spark.rdd.RDD
import org.apache.spark.{ SparkContext, SparkConf }
import scala.collection.Map
/**
* Created by root on 2016/5/12 0012.
*/
class Recommonder {
}
object Recommonder {
def main(args: Array[String]) {
Logger.getLogger("org.apache.spark").setLevel(Level.ERROR)
val conf = new SparkConf().setAppName("recom").setMaster("local[*]")
val sc = new SparkContext(conf)
//加载数据,用 分隔开
val data: RDD[Array[String]] = sc.textFile("d:/result").map(_.split(" "))
println("data.getNumPartitions:" + data.getNumPartitions) //如果文件在本地的话,默认是32M的分片
// -1 Item.id,hitop_id85:1,Item.screen,screen2:1 一行数据格式
//得到第一列的值,也就是label
val label: RDD[String] = data.map(_(0))
println(label)
//sample这个RDD中保存的是每一条记录的特征名
val sample: RDD[Array[String]] = data.map(_(1)).map(x => {
val arr: Array[String] = x.split(";").map(_.split(":")(0))
arr
})
println(sample)
// //将所有元素压平,得到的是所有分特征,然后去重,最后索引化,也就是加上下标,最后转成map是为了后面查询用
val dict: Map[String, Long] = sample.flatMap(x =>x).distinct().zipWithIndex().collectAsMap()
//得到稀疏向量
val sam: RDD[SparseVector] = sample.map(sampleFeatures => {
//index中保存的是,未来在构建训练集时,下面填1的索引号集合
val index: Array[Int] = sampleFeatures.map(feature => {
//get出来的元素程序认定可能为空,做一个类型匹配
val rs: Long = dict.get(feature) match {
case Some(x) => x
}
//非零元素下标,转int符合SparseVector的构造函数
rs.toInt
})
//SparseVector创建一个向量
new SparseVector(dict.size, index, Array.fill(index.length)(1.0)) //通过这行代码,将哪些地方填1,哪些地方填0
})
//mllib中的逻辑回归只认1.0和0.0,这里进行一个匹配转换
val la: RDD[LabeledPoint] = label.map(x => {
x match {
case "-1" => 0.0
case "1" => 1.0
}
//标签组合向量得到labelPoint
}).zip(sam).map(x => new LabeledPoint(x._1, x._2))
// val splited = la.randomSplit(Array(0.1, 0.9), 10)
//
// la.sample(true, 0.002).saveAsTextFile("trainSet")
// la.sample(true, 0.001).saveAsTextFile("testSet")
// println("done")
//逻辑回归训练,两个参数,迭代次数和步长,生产常用调整参数
val lr = new LogisticRegressionWithSGD()
// 设置W0截距
lr.setIntercept(true)
// // 设置正则化
// lr.optimizer.setUpdater(new SquaredL2Updater)
// // 看中W模型推广能力的权重
// lr.optimizer.setRegParam(0.4)
// 最大迭代次数
lr.optimizer.setNumIterations(10)
// 设置梯度下降的步长,学习率
lr.optimizer.setStepSize(0.1)
val model: LogisticRegressionModel = lr.run(la)
//模型结果权重
val weights: Array[Double] = model.weights.toArray
//将map反转,weights相应下标的权重对应map里面相应下标的特征名
val map: Map[Long, String] = dict.map(_.swap)
//模型保存
// LogisticRegressionModel.load()
// model.save()
//输出
val pw = new PrintWriter("model");
//遍历
for(i<- 0 until weights.length){
//通过map得到每个下标相应的特征名
val featureName = map.get(i)match {
case Some(x) => x
case None => ""
}
//特征名对应相应的权重
val str = featureName+" " + weights(i)
pw.write(str)
pw.println()
}
pw.flush()
pw.close()
}
}
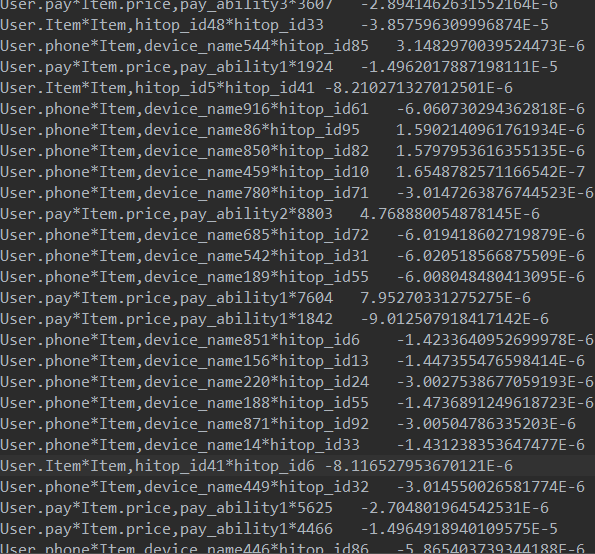
model文件截图如下:
各个特征下面对应的权重:
将模型文件和用户历史数据,和商品表数据加载到redis中去。
代码如下:
# -*- coding=utf-8 -*- import redis pool = redis.ConnectionPool(host='node05', port='6379',db=2) r = redis.Redis(connection_pool=pool) f1 = open('../data/ModelFile.txt') f2 = open('../data/UserItemsHistory.txt') f3 = open('../data/ItemList.txt') for i in list: lines = i.readlines(100) if not lines: break for line in lines: kv = line.split(' ') if i==f1: r.hset("rcmd_features_score", kv[0], kv[1]) if i == f2: r.hset('rcmd_user_history', kv[0], kv[1]) if i==f3: r.hset('rcmd_item_list', kv[0], line[:-2]) f1.close()
最终redis文件中截图如下:
