一、前述
Spark中调优大致分为以下几种 ,代码调优,数据本地化,内存调优,SparkShuffle调优,调节Executor的堆外内存。
二、具体
1、代码调优
1、避免创建重复的RDD,尽量使用同一个RDD
2、对多次使用的RDD进行持久化
如何选择一种最合适的持久化策略?
默认情况下,性能最高的当然是MEMORY_ONLY,但前提是你的内存必须足够足够大,可以绰绰有余地存放下整个RDD的所有数据。因为不进行序列化与反序列化操作,就避免了这部分的性能开销;对这个RDD的后续算子操作,都是基于纯内存中的数据的操作,不需要从磁盘文件中读取数据,性能也很高;而且不需要复制一份数据副本,并远程传送到其他节点上。但是这里必须要注意的是,在实际的生产环境中,恐怕能够直接用这种策略的场景还是有限的,如果RDD中数据比较多时(比如几十亿),直接用这种持久化级别,会导致JVM的OOM内存溢出异常。
如果使用MEMORY_ONLY级别时发生了内存溢出,那么建议尝试使用MEMORY_ONLY_SER级别。该级别会将RDD数据序列化后再保存在内存中,此时每个partition仅仅是一个字节数组而已,大大减少了对象数量,并降低了内存占用。这种级别比MEMORY_ONLY多出来的性能开销,主要就是序列化与反序列化的开销。但是后续算子可以基于纯内存进行操作,因此性能总体还是比较高的。此外,可能发生的问题同上,如果RDD中的数据量过多的话,还是可能会导致OOM内存溢出的异常。
如果纯内存的级别都无法使用,那么建议使用MEMORY_AND_DISK_SER策略,而不是MEMORY_AND_DISK策略。因为既然到了这一步,就说明RDD的数据量很大,内存无法完全放下。序列化后的数据比较少,可以节省内存和磁盘的空间开销。同时该策略会优先尽量尝试将数据缓存在内存中,内存缓存不下才会写入磁盘。
通常不建议使用DISK_ONLY和后缀为_2的级别:因为完全基于磁盘文件进行数据的读写,会导致性能急剧降低,有时还不如重新计算一次所有RDD。后缀为_2的级别,必须将所有数据都复制一份副本,并发送到其他节点上,数据复制以及网络传输会导致较大的性能开销,除非是要求作业的高可用性,否则不建议使用。
持久化算子:
cache:
MEMORY_ONLY
persist:
MEMORY_ONLY
MEMORY_ONLY_SER
MEMORY_AND_DISK_SER
一般不要选择带有_2的持久化级别。
checkpoint:
① 如果一个RDD的计算时间比较长或者计算起来比较复杂,一般将这个RDD的计算结果保存到HDFS上,这样数据会更加安全。
② 如果一个RDD的依赖关系非常长,也会使用checkpoint,会切断依赖关系,提高容错的效率。
3、尽量避免使用shuffle类的算子
使用广播变量来模拟使用join,使用情况:一个RDD比较大,一个RDD比较小。
join算子=广播变量+filter、广播变量+map、广播变量+flatMap
4、使用map-side预聚合的shuffle操作
即尽量使用有combiner的shuffle类算子。
combiner概念:
在map端,每一个map task计算完毕后进行的局部聚合。
combiner好处:
1) 降低shuffle write写磁盘的数据量。
2) 降低shuffle read拉取数据量的大小。
3) 降低reduce端聚合的次数。
有combiner的shuffle类算子:
1) reduceByKey:这个算子在map端是有combiner的,在一些场景中可以使用reduceByKey代替groupByKey。
2) aggregateByKey
3) combineByKey
5、尽量使用高性能的算子
使用reduceByKey替代groupByKey
使用mapPartition替代map
使用foreachPartition替代foreach
filter后使用coalesce减少分区数
使用repartitionAndSortWithinPartitions替代repartition与sort类操作
使用repartition和coalesce算子操作分区。
6、使用广播变量
开发过程中,会遇到需要在算子函数中使用外部变量的场景(尤其是大变量,比如100M以上的大集合),那么此时就应该使用Spark的广播(Broadcast)功能来提升性能,函数中使用到外部变量时,默认情况 下,Spark会将该变量复制多个副本,通过网络传输到task中,此时每个task都有一个变量副本。如果变量本身比较大的话(比如100M,甚至1G),那么大量的变量副本在网络中传输的性能开销,以及在各个节点的Executor中占用过多内存导致的频繁GC,都会极大地影响性能。如果使用的外部变量比较大,建议使用Spark的广播功能,对该变量进行广播。广播后的变量,会保证每个Executor的内存中,只驻留一份变量副本,而Executor中的task执行时共享该Executor中的那份变量副本。这样的话,可以大大减少变量副本的数量,从而减少网络传输的性能开销,并减少对Executor内存的占用开销,降低GC的频率。
广播大变量发送方式:Executor一开始并没有广播变量,而是task运行需要用到广播变量,会找executor的blockManager要,bloackManager找Driver里面的blockManagerMaster要。
使用广播变量可以大大降低集群中变量的副本数。不使用广播变量,变量的副本数和task数一致。使用广播变量变量的副本和Executor数一致。
7、使用Kryo优化序列化性能
在Spark中,主要有三个地方涉及到了序列化:
1) 在算子函数中使用到外部变量时,该变量会被序列化后进行网络传输。
2) 将自定义的类型作为RDD的泛型类型时(比如JavaRDD<SXT>,SXT是自定义类型),所有自定义类型对象,都会进行序列化。因此这种情况下,也要求自定义的类必须实现Serializable接口。
3) 使用可序列化的持久化策略时(比如MEMORY_ONLY_SER),Spark会将RDD中的每个partition都序列化成一个大的字节数组。
4) Task发送时也需要序列化。
Kryo序列化器介绍:
Spark支持使用Kryo序列化机制。Kryo序列化机制,比默认的Java序列化机制,速度要快,序列化后的数据要更小,大概是Java序列化机制的1/10。所以Kryo序列化优化以后,可以让网络传输的数据变少;在集群中耗费的内存资源大大减少。
对于这三种出现序列化的地方,我们都可以通过使用Kryo序列化类库,来优化序列化和反序列化的性能。Spark默认使用的是Java的序列化机制,也就是ObjectOutputStream/ObjectInputStream API来进行序列化和反序列化。但是Spark同时支持使用Kryo序列化库,Kryo序列化类库的性能比Java序列化类库的性能要高很多。官方介绍,Kryo序列化机制比Java序列化机制,性能高10倍左右。Spark之所以默认没有使用Kryo作为序列化类库,是因为Kryo要求最好要注册所有需要进行序列化的自定义类型,因此对于开发者来说,这种方式比较麻烦。
Spark中使用Kryo:
Sparkconf.set("spark.serializer", "org.apache.spark.serializer.KryoSerializer").registerKryoClasses(new Class[]{SpeedSortKey.class})
8、优化数据结构
java中有三种类型比较消耗内存:
1) 对象,每个Java对象都有对象头、引用等额外的信息,因此比较占用内存空间。
2) 字符串,每个字符串内部都有一个字符数组以及长度等额外信息。
3) 集合类型,比如HashMap、LinkedList等,因为集合类型内部通常会使用一些内部类来封装集合元素,比如Map.Entry。
因此Spark官方建议,在Spark编码实现中,特别是对于算子函数中的代码,尽量不要使用上述三种数据结构,尽量使用字符串替代对象,使用原始类型(比如Int、Long)替代字符串,使用数组替代集合类型,这样尽可能地减少内存占用,从而降低GC频率,提升性能。
2、数据本地化
1、数据本地化的级别:
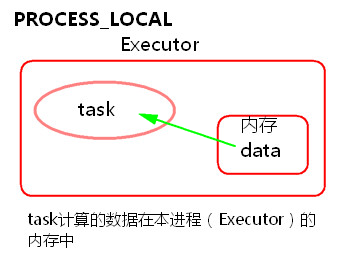
1) PROCESS_LOCAL
task要计算的数据在本进程(Executor)的内存中。
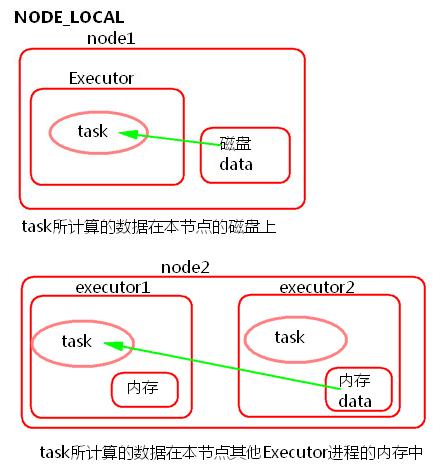
2) NODE_LOCAL
① task所计算的数据在本节点所在的磁盘上。
② task所计算的数据在本节点其他Executor进程的内存中。
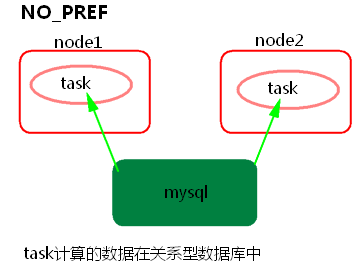
3) NO_PREF
task所计算的数据在关系型数据库中,如mysql。
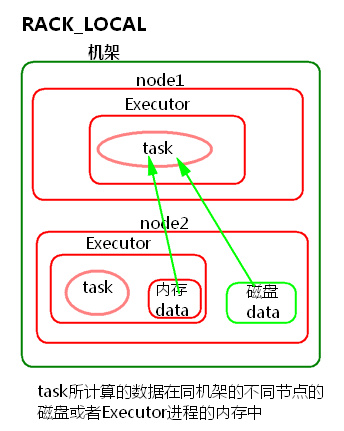
4) RACK_LOCAL
task所计算的数据在同机架的不同节点的磁盘或者Executor进程的内存中
5) ANY
跨机架。
2、Spark数据本地化调优:
Spark中任务调度时,TaskScheduler在分发之前需要依据数据的位置来分发,最好将task分发到数据所在的节点上,如果TaskScheduler分发的task在默认3s依然无法执行的话,TaskScheduler会重新发送这个task到相同的Executor中去执行,会重试5次,如果依然无法执行,那么TaskScheduler会降低一级数据本地化的级别再次发送task。
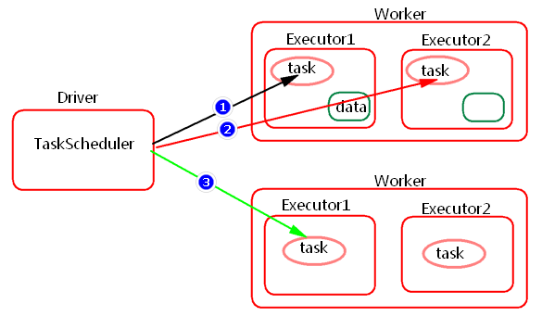
如上图中,会先尝试1,PROCESS_LOCAL数据本地化级别,如果重试5次每次等待3s,会默认这个Executor计算资源满了,那么会降低一级数据本地化级别到2,NODE_LOCAL,如果还是重试5次每次等待3s还是失败,那么还是会降低一级数据本地化级别到3,RACK_LOCAL。这样数据就会有网络传输,降低了执行效率。
1) 如何提高数据本地化的级别?
可以增加每次发送task的等待时间(默认都是3s),将3s倍数调大, 结合WEBUI来调节:
spark.locality.wait
spark.locality.wait.process
spark.locality.wait.node
spark.locality.wait.rack
注意:等待时间不能调大很大,调整数据本地化的级别不要本末倒置,虽然每一个task的本地化级别是最高了,但整个Application的执行时间反而加长。
2) 如何查看数据本地化的级别?
通过日志或者WEBUI
3、内存调优
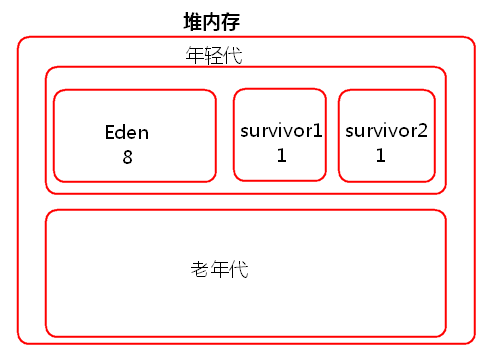
JVM堆内存分为一块较大的Eden和两块较小的Survivor,每次只使用Eden和其中一块Survivor,当回收时将Eden和Survivor中还存活着的对象一次性复制到另外一块Survivor上,最后清理掉Eden和刚才用过的Survivor。也就是说当task创建出来对象会首先往Eden和survivor1中存放,survivor2是空闲的,当Eden和survivor1区域放满以后就会触发minor gc小型垃圾回收,清理掉不再使用的对象。会将存活下来的对象放入survivor2中。
如果存活下来的对象大小大于survivor2的大小,那么JVM就会将多余的对象直接放入到老年代中。
如果这个时候年轻代的内存不是很大的话,就会经常的进行minor gc,频繁的minor gc会导致短时间内有些存活的对象(多次垃圾回收都没有回收掉,一直在用的又不能被释放,这种对象每经过一次minor gc都存活下来)频繁的倒来倒去,会导致这些短生命周期的对象(不一定长期使用)每进行一次垃圾回收就会长一岁。年龄过大,默认15岁,垃圾回收还是没有回收回去就会跑到老年代里面去了。
这样会导致在老年代中存放大量的短生命周期的对象,老年代应该存放的是数量比较少并且会长期使用的对象,比如数据库连接池对象。这样的话,老年代就会满溢(full gc 因为本来老年代中的对象很少,很少进行full gc 因此采取了不太复杂但是消耗性能和时间的垃圾回收算法)。不管minor gc 还是 full gc都会导致JVM的工作线程停止。
总结:
堆内存不足造成的影响:
1) 频繁的minor gc。
2) 老年代中大量的短生命周期的对象会导致full gc。
3) gc 多了就会影响Spark的性能和运行的速度。
Spark JVM调优主要是降低gc时间,可以修改Executor内存的比例参数。
RDD缓存、task定义运行的算子函数,可能会创建很多对象,这样会占用大量的堆内存。堆内存满了之后会频繁的GC,如果GC还不能够满足内存的需要的话就会报OOM。比如一个task在运行的时候会创建N个对象,这些对象首先要放入到JVM年轻代中。比如在存数据的时候我们使用了foreach来将数据写入到内存,每条数据都会封装到一个对象中存入数据库中,那么有多少条数据就会在JVM中创建多少个对象。
Spark中如何内存调优?
Spark Executor堆内存中存放(以静态内存管理为例):RDD的缓存数据和广播变量(spark.storage.memoryFraction 0.6),shuffle聚合内存(spark.shuffle.memoryFraction 0.2),task的运行(0.2)那么如何调优呢?
1) 提高Executor总体内存的大小
2) 降低储存内存比例或者降低聚合内存比例
如何查看gc?
Spark WEBUI中job->stage->task
4、Spark Shuffle调优
spark.shuffle.file.buffer 32k buffer大小 默认是32K maptask端的shuffle 降低磁盘IO .
spark.reducer.MaxSizeFlight 48M shuffle read拉取数据量的大小
spark.shuffle.memoryFraction 0.2 shuffle聚合内存的比例
spark.shuffle.io.maxRetries 3 拉取数据重试次数
spark.shuffle.io.retryWait 5s 调整到重试间隔时间60s
spark.shuffle.manager hash|sort Spark Shuffle的种类
spark.shuffle.consolidateFiles false----针对HashShuffle HashShuffle 合并机制
spark.shuffle.sort.bypassMergeThreshold 200----针对SortShuffle SortShuffle bypass机制 200次
5、调节Executor的堆外内存
原因:
Spark底层shuffle的传输方式是使用netty传输,netty在进行网络传输的过程会申请堆外内存(netty是零拷贝),所以使用了堆外内存。默认情况下,这个堆外内存上限默认是每一个executor的内存大小的10%;真正处理大数据的时候,这里都会出现问题,导致spark作业反复崩溃,无法运行;此时就会去调节这个参数,到至少1G(1024M),甚至说2G、4G。
executor在进行shuffle write,优先从自己本地关联的mapOutPutWorker中获取某份数据,如果本地block manager没有的话,那么会通过TransferService,去远程连接其他节点上executor的block manager去获取,尝试建立远程的网络连接,并且去拉取数据。频繁创建对象让JVM堆内存满溢,进行垃圾回收。正好碰到那个exeuctor的JVM在垃圾回收。处于垃圾回过程中,所有的工作线程全部停止;相当于只要一旦进行垃圾回收,spark / executor停止工作,无法提供响应,spark默认的网络连接的超时时长是60s;如果卡住60s都无法建立连接的话,那么这个task就失败了。task失败了就会出现shuffle file cannot find的错误。
解决方法:
1.调节等待时长。
在./spark-submit提交任务的脚本里面添加:
--conf spark.core.connection.ack.wait.timeout=300
Executor由于内存不足或者堆外内存不足了,挂掉了,对应的Executor上面的block manager也挂掉了,找不到对应的shuffle map output文件,Reducer端不能够拉取数据。
2.调节堆外内存大小
在./spark-submit提交任务的脚本里面添加
yarn下:
--conf spark.yarn.executor.memoryOverhead=2048 单位M
standalone下:
--conf spark.executor.memoryOverhead=2048单位M