一、前述
Spark中默认有两大类算子,Transformation(转换算子),懒执行。action算子,立即执行,有一个action算子 ,就有一个job。
通俗些来说由RDD变成RDD就是Transformation算子,由RDD转换成其他的格式就是Action算子。
二、常用Transformation算子
假设数据集为此:
1、filter
过滤符合条件的记录数,true保留,false过滤掉。
Java版:
package com.spark.spark.transformations; import org.apache.spark.SparkConf; import org.apache.spark.api.java.JavaRDD; import org.apache.spark.api.java.JavaSparkContext; import org.apache.spark.api.java.function.Function; import org.apache.spark.api.java.function.VoidFunction; /** * filter * 过滤符合符合条件的记录数,true的保留,false的过滤掉。 * */ public class Operator_filter { public static void main(String[] args) { /** * SparkConf对象中主要设置Spark运行的环境参数。 * 1.运行模式 * 2.设置Application name * 3.运行的资源需求 */ SparkConf conf = new SparkConf(); conf.setMaster("local"); conf.setAppName("filter"); /** * JavaSparkContext对象是spark运行的上下文,是通往集群的唯一通道。 */ JavaSparkContext jsc = new JavaSparkContext(conf); JavaRDD<String> lines = jsc.textFile("./words.txt"); JavaRDD<String> resultRDD = lines.filter(new Function<String, Boolean>() { /** * */ private static final long serialVersionUID = 1L; @Override public Boolean call(String line) throws Exception { return !line.contains("hadoop");//这里是不等于 } }); resultRDD.foreach(new VoidFunction<String>() { /** * */ private static final long serialVersionUID = 1L; @Override public void call(String line) throws Exception { System.out.println(line); } }); jsc.stop(); } }
scala版:
函数解释:
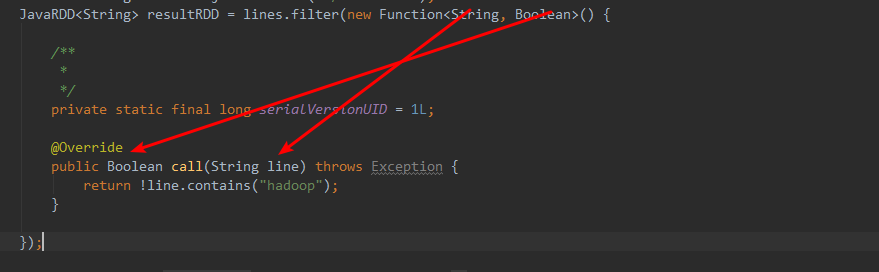
进来一个String,出去一个Booean.
结果:

2、map
将一个RDD中的每个数据项,通过map中的函数映射变为一个新的元素。
特点:输入一条,输出一条数据。
/** * map * 通过传入的函数处理每个元素,返回新的数据集。 * 特点:输入一条,输出一条。 * * * @author root * */ public class Operator_map { public static void main(String[] args) { SparkConf conf = new SparkConf(); conf.setMaster("local"); conf.setAppName("map"); JavaSparkContext jsc = new JavaSparkContext(conf); JavaRDD<String> line = jsc.textFile("./words.txt"); JavaRDD<String> mapResult = line.map(new Function<String, String>() { /** * */ private static final long serialVersionUID = 1L; @Override public String call(String s) throws Exception { return s+"~"; } }); mapResult.foreach(new VoidFunction<String>() { /** * */ private static final long serialVersionUID = 1L; @Override public void call(String t) throws Exception { System.out.println(t); } }); jsc.stop(); } }
函数解释:
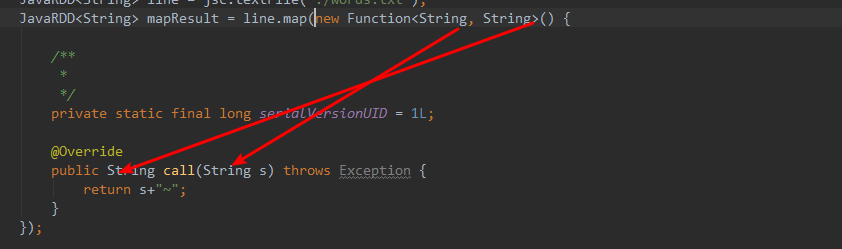
进来一个String,出去一个String。
函数结果:

3、flatMap(压扁输出,输入一条,输出零到多条)
先map后flat。与map类似,每个输入项可以映射为0到多个输出项。
package com.spark.spark.transformations; import java.util.Arrays; import org.apache.spark.SparkConf; import org.apache.spark.api.java.JavaRDD; import org.apache.spark.api.java.JavaSparkContext; import org.apache.spark.api.java.function.FlatMapFunction; import org.apache.spark.api.java.function.VoidFunction; /** * flatMap * 输入一条数据,输出0到多条数据。 * @author root * */ public class Operator_flatMap { public static void main(String[] args) { SparkConf conf = new SparkConf(); conf.setMaster("local"); conf.setAppName("flatMap"); JavaSparkContext jsc = new JavaSparkContext(conf); JavaRDD<String> lines = jsc.textFile("./words.txt"); JavaRDD<String> flatMapResult = lines.flatMap(new FlatMapFunction<String, String>() { /** * */ private static final long serialVersionUID = 1L; @Override public Iterable<String> call(String s) throws Exception { return Arrays.asList(s.split(" ")); } }); flatMapResult.foreach(new VoidFunction<String>() { /** * */ private static final long serialVersionUID = 1L; @Override public void call(String t) throws Exception { System.out.println(t); } }); jsc.stop(); } }
函数解释:
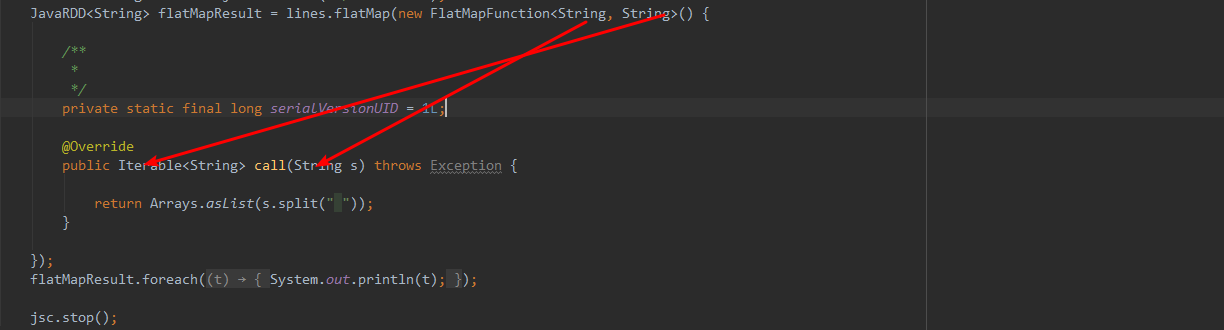
进来一个String,出去一个集合。
Iterater 集合
iterator 遍历元素
函数结果:

4、sample(随机抽样)
随机抽样算子,根据传进去的小数按比例进行又放回或者无放回的抽样。(True,fraction,long)
True 抽样放回
Fraction 一个比例 float 大致 数据越大 越准确
第三个参数:随机种子,抽到的样本一样 方便测试
package com.spark.spark.transformations; import java.util.ArrayList; import java.util.List; import org.apache.spark.SparkConf; import org.apache.spark.api.java.JavaPairRDD; import org.apache.spark.api.java.JavaRDD; import org.apache.spark.api.java.JavaSparkContext; import org.apache.spark.api.java.function.PairFlatMapFunction; import org.apache.spark.api.java.function.VoidFunction; import scala.Tuple2; public class Operator_sample { public static void main(String[] args) { SparkConf conf = new SparkConf(); conf.setMaster("local"); conf.setAppName("sample"); JavaSparkContext jsc = new JavaSparkContext(conf); JavaRDD<String> lines = jsc.textFile("./words.txt"); JavaPairRDD<String, Integer> flatMapToPair = lines.flatMapToPair(new PairFlatMapFunction<String, String, Integer>() { /** * */ private static final long serialVersionUID = 1L; @Override public Iterable<Tuple2<String, Integer>> call(String t) throws Exception { List<Tuple2<String,Integer>> tupleList = new ArrayList<Tuple2<String,Integer>>(); tupleList.add(new Tuple2<String,Integer>(t,1)); return tupleList; } }); JavaPairRDD<String, Integer> sampleResult = flatMapToPair.sample(true,0.3,4);//样本有7个所以大致抽样为1-2个 sampleResult.foreach(new VoidFunction<Tuple2<String,Integer>>() { /** * */ private static final long serialVersionUID = 1L; @Override public void call(Tuple2<String, Integer> t) throws Exception { System.out.println(t); } }); jsc.stop(); } }
函数结果:

5.reduceByKey
将相同的Key根据相应的逻辑进行处理。
package com.spark.spark.transformations; import java.util.Arrays; import org.apache.spark.SparkConf; import org.apache.spark.api.java.JavaPairRDD; import org.apache.spark.api.java.JavaRDD; import org.apache.spark.api.java.JavaSparkContext; import org.apache.spark.api.java.function.FlatMapFunction; import org.apache.spark.api.java.function.Function2; import org.apache.spark.api.java.function.PairFunction; import org.apache.spark.api.java.function.VoidFunction; import scala.Tuple2; public class Operator_reduceByKey { public static void main(String[] args) { SparkConf conf = new SparkConf(); conf.setMaster("local").setAppName("reduceByKey"); JavaSparkContext jsc = new JavaSparkContext(conf); JavaRDD<String> lines = jsc.textFile("./words.txt"); JavaRDD<String> flatMap = lines.flatMap(new FlatMapFunction<String, String>() { /** * */ private static final long serialVersionUID = 1L; @Override public Iterable<String> call(String t) throws Exception { return Arrays.asList(t.split(" ")); } }); JavaPairRDD<String, Integer> mapToPair = flatMap.mapToPair(new PairFunction<String, String, Integer>() { /** * */ private static final long serialVersionUID = 1L; @Override public Tuple2<String, Integer> call(String t) throws Exception { return new Tuple2<String,Integer>(t,1); } }); JavaPairRDD<String, Integer> reduceByKey = mapToPair.reduceByKey(new Function2<Integer,Integer,Integer>(){ /** * */ private static final long serialVersionUID = 1L; @Override public Integer call(Integer v1, Integer v2) throws Exception { return v1+v2; } },10); reduceByKey.foreach(new VoidFunction<Tuple2<String,Integer>>() { /** * */ private static final long serialVersionUID = 1L; @Override public void call(Tuple2<String, Integer> t) throws Exception { System.out.println(t); } }); jsc.stop(); } }
函数解释:
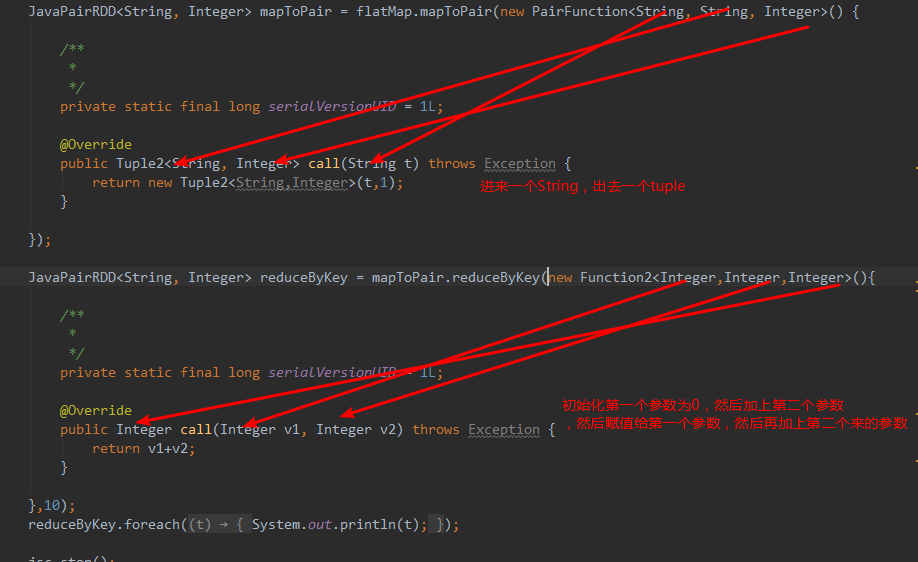
函数结果:

6、sortByKey/sortBy
作用在K,V格式的RDD上,对key进行升序或者降序排序。
Sortby在java中没有
package com.spark.spark.transformations;
import java.util.Arrays;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.FlatMapFunction;
import org.apache.spark.api.java.function.Function2;
import org.apache.spark.api.java.function.PairFunction;
import org.apache.spark.api.java.function.VoidFunction;
import scala.Tuple2;
public class Operator_sortByKey {
public static void main(String[] args) {
SparkConf conf = new SparkConf();
conf.setMaster("local");
conf.setAppName("sortByKey");
JavaSparkContext jsc = new JavaSparkContext(conf);
JavaRDD<String> lines = jsc.textFile("./words.txt");
JavaRDD<String> flatMap = lines.flatMap(new FlatMapFunction<String, String>() {
/**
*
*/
private static final long serialVersionUID = 1L;
@Override
public Iterable<String> call(String t) throws Exception {
return Arrays.asList(t.split(" "));
}
});
JavaPairRDD<String, Integer> mapToPair = flatMap.mapToPair(new PairFunction<String, String, Integer>() {
/**
*
*/
private static final long serialVersionUID = 1L;
@Override
public Tuple2<String, Integer> call(String s) throws Exception {
return new Tuple2<String, Integer>(s, 1);
}
});
JavaPairRDD<String, Integer> reduceByKey = mapToPair.reduceByKey(new Function2<Integer, Integer, Integer>() {
/**
*
*/
private static final long serialVersionUID = 1L;
@Override
public Integer call(Integer v1, Integer v2) throws Exception {
return v1+v2;
}
});
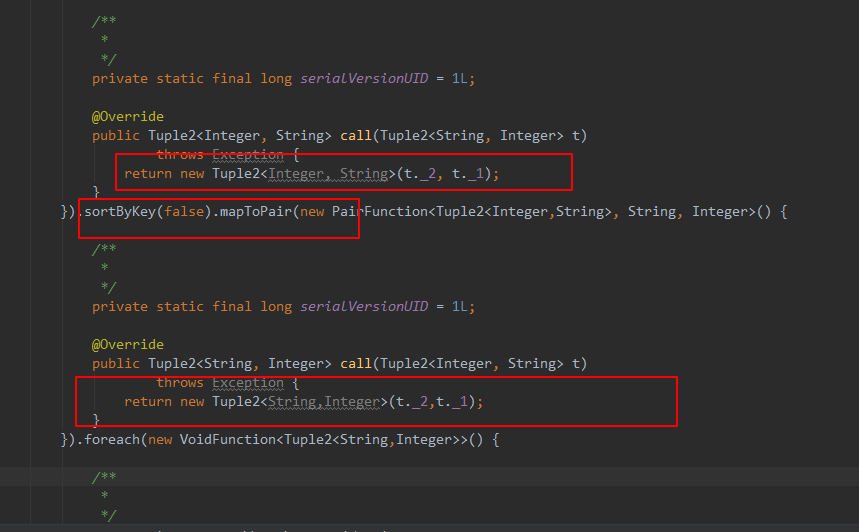
reduceByKey.mapToPair(new PairFunction<Tuple2<String,Integer>, Integer, String>() {
/**
*
*/
private static final long serialVersionUID = 1L;
@Override
public Tuple2<Integer, String> call(Tuple2<String, Integer> t)
throws Exception {
return new Tuple2<Integer, String>(t._2, t._1);
}
}).sortByKey(false).mapToPair(new PairFunction<Tuple2<Integer,String>, String, Integer>() {//先把key.value对调,然后排完序后再对调回来 false是降序,True是升序
/**
*
*/
private static final long serialVersionUID = 1L;
@Override
public Tuple2<String, Integer> call(Tuple2<Integer, String> t)
throws Exception {
return new Tuple2<String,Integer>(t._2,t._1);
}
}).foreach(new VoidFunction<Tuple2<String,Integer>>() {
/**
*
*/
private static final long serialVersionUID = 1L;
@Override
public void call(Tuple2<String, Integer> t) throws Exception {
System.out.println(t);
}
});
}
}
代码解释:先对调,排完序,在对调过来
代码结果:
