Hadoop完全分布式环境部署
2、使用软件及其版本
环境
虚拟机:VirtualBox 6.0.24 r139119
Linux:CentOS 7
Windows:Windows10
软件
JDK:Jdk1.8_131
Hadoop:Hadoop-2.6.0-cdh5.7.0
工具
IDE工具:IntelliJ IDEA 2018.3.6 (Ultimate Edition)
远程连接工具:XShell6
SFTP工具:FileZilla3.33.0
3、目标
-
hadoop完全分布式环境部署
4、操作步骤
-
Hadoop的集群规划
规划集群由3台主机构成,一个主节点,两个从节点,主机名分别为:
主节点:master
从节点1:slave01
从节点2:slave02
配置ip地址为:
master:192.168.137.2
slave01:192.168.137.3
slave02:192.168.137.4
节点的服务:
master:NameNode、DataNode、ResourceManager
slave01:DataNode、NodeManager
slave02:DataNode、NodeManager
-
前置安装
-
复制虚拟机镜像
根据上一章安装的单节点伪分布的环境进行复制(注意:复制前删除/opt/hdfs/tmp目录下文件)
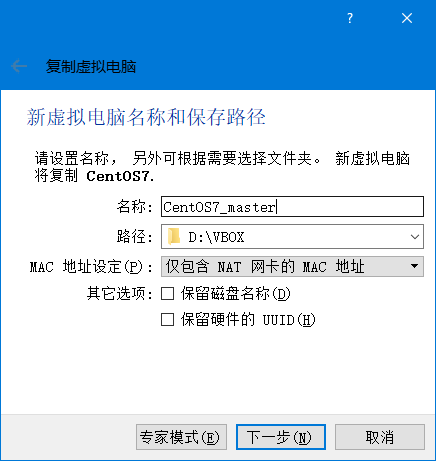
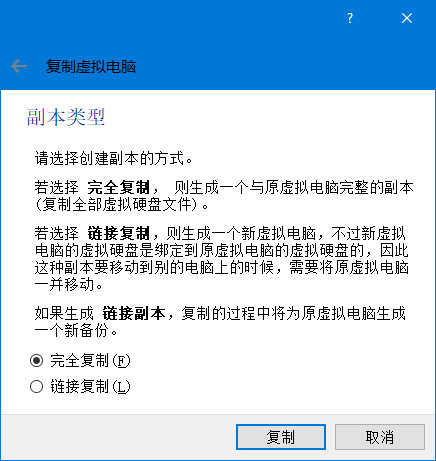
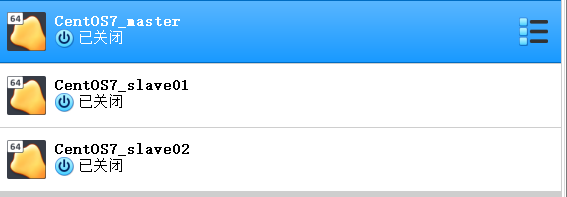
完成3个虚拟机的复制
-
设置slave01和slave02节点的主机名
-
slave01节点root用户下(或者拥有root 权限的用户下),使用命令:
sudo vi /etc/hostname -
slave02节点root用户下(或者拥有root 权限的用户下),使用命令:
sudo vi /etc/hostname
重启系统,使之生效!
-
-
修改slave01和slave02节点的ip地址
-
slave01节点,使用命令:
sudo vi /etc/sysconfig/network-scripts/ifcfg-enp0s3TYPE=Ethernet
PROXY_METHOD=none
BROWSER_ONLY=no
BOOTPROTO=static
DEFROUTE=yes
IPV4_FAILURE_FATAL=no
IPV6INIT=yes
IPV6_AUTOCONF=yes
IPV6_DEFROUTE=yes
IPV6_FAILURE_FATAL=no
IPV6_ADDR_GEN_MODE=stable-privacy
NAME=enp0s3
UUID=b99405f1-6afb-4d97-94e4-c3893e72700a
DEVICE=enp0s3
ONBOOT=yes
IPADDR=192.168.137.3
NETMASK=255.255.255.0
GATEWAY=192.168.137.1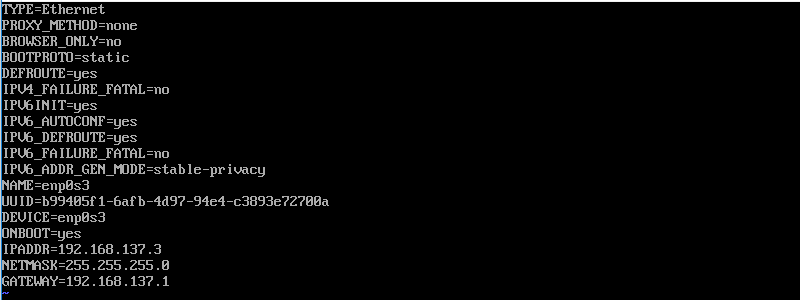
使用
systemctl restart network命令,重启网络使网络配置生效 -
slave02节点,使用命令:
sudo vi /etc/sysconfig/network-scripts/ifcfg-enp0s3TYPE=Ethernet
PROXY_METHOD=none
BROWSER_ONLY=no
BOOTPROTO=static
DEFROUTE=yes
IPV4_FAILURE_FATAL=no
IPV6INIT=yes
IPV6_AUTOCONF=yes
IPV6_DEFROUTE=yes
IPV6_FAILURE_FATAL=no
IPV6_ADDR_GEN_MODE=stable-privacy
NAME=enp0s3
UUID=b99405f1-6afb-4d97-94e4-c3893e72700a
DEVICE=enp0s3
ONBOOT=yes
IPADDR=192.168.137.4
NETMASK=255.255.255.0
GATEWAY=192.168.137.1
使用
systemctl restart network命令,重启网络使网络配置生效
-
-
设置master、slave01和slave02节点的ip和主机名的映射关系
-
在master节点,使用命令:
sudo vi /etc/hosts
添加配置:
192.168.137.2 master
192.168.137.3 slave01
192.168.137.4 slave02
-
slave01节点root用户下(或者拥有root 权限的用户下),使用命令:
sudo scp hadoop@192.168.137.2:/etc/hosts /etc/hosts
把master节点的hosts文件拷贝到本机,省去重复配置的麻烦。
-
slave02节点root用户下(或者拥有root 权限的用户下),使用命令:
sudo scp hadoop@192.168.137.2:/etc/hosts /etc/hosts
把master节点的hosts文件拷贝到本机,省去重复配置的麻烦。
-
-
关闭所有节点的防火墙
由于是通过单节点的机器复制出来的虚拟机,所有JDK已经安装完成!
-
验证防火墙
-
master节点,使用命令:
systemctl status firewalld
-
slave01节点,使用命令:
systemctl status firewalld
-
slave02节点,使用命令:
systemctl status firewalld
-
-
-
ssh免密码登陆设置
-
每个节点,执行命令:
ssh-keygen -t rsa
-
master节点
-
slave01节点
-
slave02节点
-
复制master节点的公钥到其他节点
-
在master节点进行操作,使用命令
ssh-copy-id -i ~/.ssh/id_rsa.pub masterssh-copy-id -i ~/.ssh/id_rsa.pub slave01ssh-copy-id -i ~/.ssh/id_rsa.pub slave02
-
在slave01,slave02节点执行同样操作,复制本节点公钥到其他节点
-
slave01节点
ssh-copy-id -i ~/.ssh/id_rsa.pub slave01ssh-copy-id -i ~/.ssh/id_rsa.pub masterssh-copy-id -i ~/.ssh/id_rsa.pub slave02 -
slave02节点
ssh-copy-id -i ~/.ssh/id_rsa.pub slave02ssh-copy-id -i ~/.ssh/id_rsa.pub masterssh-copy-id -i ~/.ssh/id_rsa.pub slave02
-
-
-
验证:
-
在master节点使用ssh命令登陆自己、slave01和slave02节点,使用命令:
ssh masterssh slave01ssh slave02
如果不需要输入密码,表示设置成功!后面的操作可以直接使用XShell远程连接工具直接进行各个主机的操作
-
-
-
-
JDK安装
由于是通过单节点的机器复制出来的虚拟机,所有JDK已经安装完成!
-
Hadoop集群的部署
-
在master节点修改hadoop安装目录下的slaves文件,使用命令
sudo vi slaves添加配置信息:
master
slave01
slave02
-
在master节点,分发该文件到slave01和slave02节点,使用命令
sudo scp slaves hadoop@slave01:~/app/hadoop-2.6.0-cdh5.7.0/etc/hadoop
sudo scp slaves hadoop@slave02:~/app/hadoop-2.6.0-cdh5.7.0/etc/hadoop
-
在master节点格式化Hadoop,使用命令
hadoop namenode -format
-
在master启动服务,在hadoop的sbin目录下,使用命令
./start-all.sh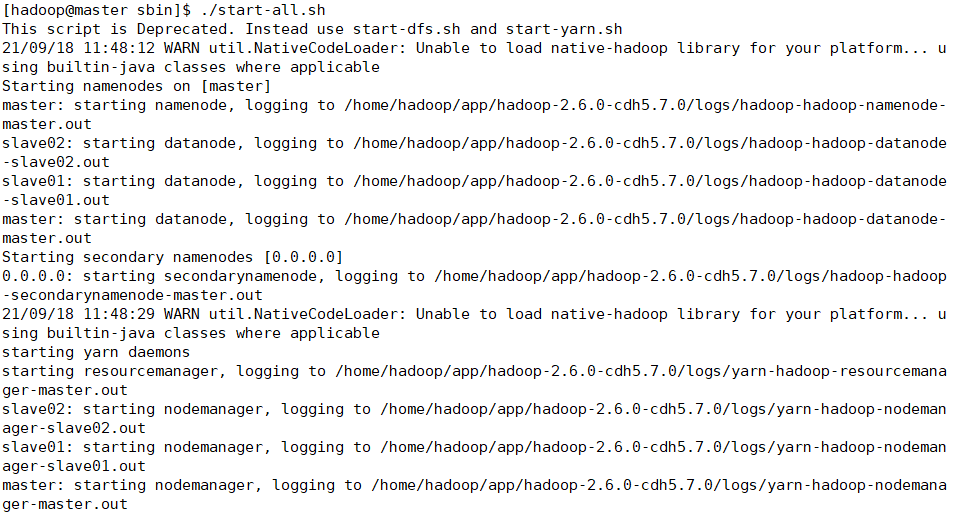
-
验证
-
在各个节点使用
jps命令检查进程,看是否和规划的一致-
master

-
slave01

-
slave02

-
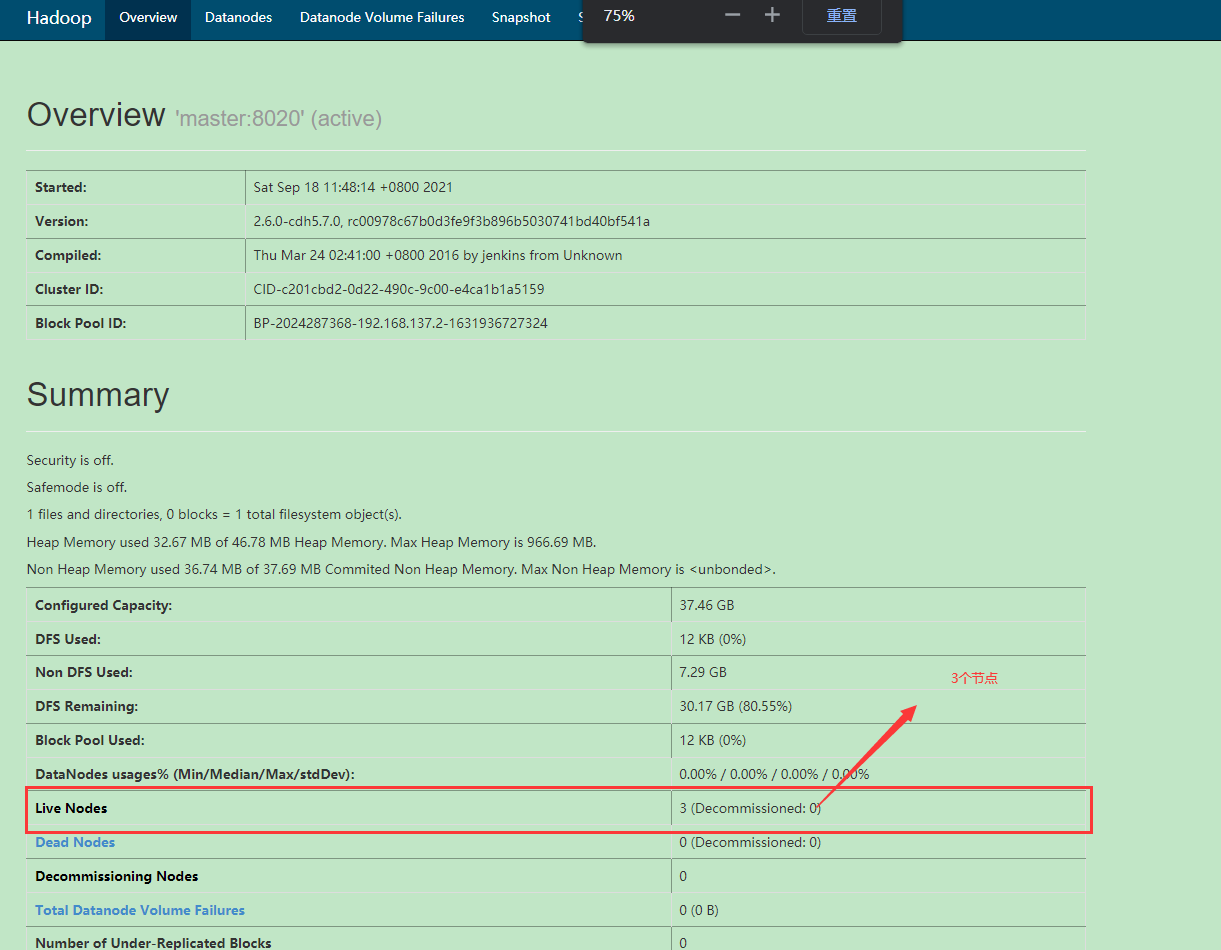
如果一致,表示hadoop的完全分布式环境搭建成功!
-
也可以使用浏览器验证,在windows中访问网址http://192.168.137.2:50070/
-
-
4、总结