Flume整合Kafka
1、背景知识
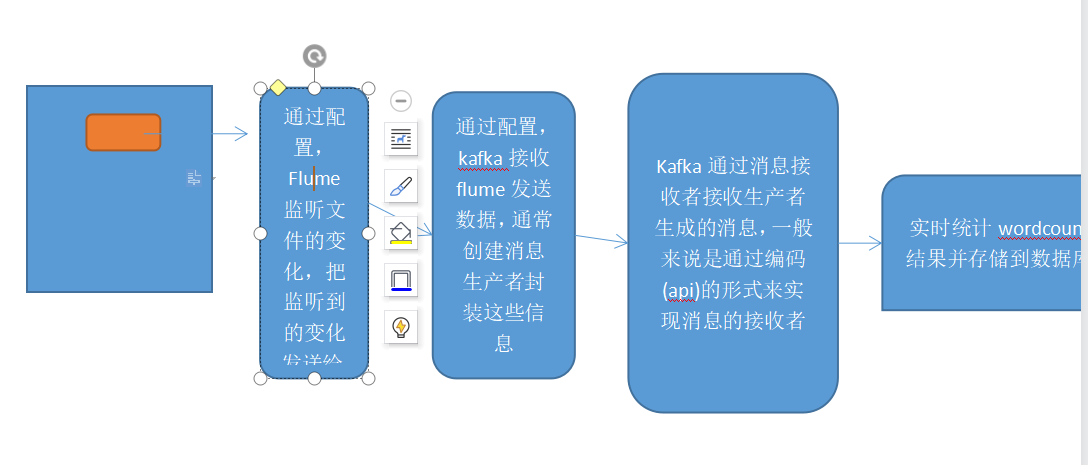
一般使用Flume+Kafka架构都是希望完成实时流式的日志处理,后面再连接上Flink/Storm/Spark Streaming等流式实时处理技术,从而完成日志实时解析的目标。
-
生产环境中,往往是读取日志进行分析,而这往往是多数据源的,如果Kafka构建多个生产者使用文件流的方式向主题写入数据再供消费者消费的话,无疑非常的不方便。
-
如果Flume直接对接实时计算框架,当数据采集速度大于数据处理速度,很容易发生数据堆积或者数据丢失,而kafka可以当做一个消息缓存队列,从广义上理解,把它当做一个数据库,可以存放一段时间的数据。
-
Kafka属于中间件,一个明显的优势就是使各层解耦,使得出错时不会干扰其他组件。
因此数据从数据源到flume再到Kafka时,数据一方面可以同步到HDFS做离线计算,另一方面可以做实时计算,可实现数据多分发。
2、使用软件及其版本
环境
虚拟机:VirtualBox 6.0.24 r139119
Linux:CentOS 7
Windows:Windows10
软件
Flume:apache-flume-1.6.0-bin
Kafka:kafka_2.11-2.3.0
工具
远程连接工具:XShell6
SFTP工具:FileZilla3.33.0
3、目标
-
Flume整合Kafka
4、操作步骤
-
Flume整合Kafka
-
在flume的安装目录的job目录下,使用
sudo vi flume-kafka.conf命令创建 flume-kafka.conf文件,添加内容# Name the components on this agent
agent.sources = r1
agent.channels = c1
agent.sinks = s1
# For each one of the sources
agent.sources.r1.type = spooldir
agent.sources.r1.spoolDir = /home/hadoop/data/flume/upload
agent.sources.r1.fileSuffix = .COMPLETED
agent.sources.r1.fileHeader = true
# Each sink's
agent.sinks.s1.type = org.apache.flume.sink.kafka.KafkaSink
agent.sinks.s1.topic = logstest
agent.sinks.s1.bootstrap.servers = master:9092
agent.sinks.s1.requiredAcks = 1
agent.sinks.s1.batchSize = 2
# Each channel's
agent.channels.c1.type = memory
agent.channels.c1.capacity = 1000
agent.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
agent.sources.r1.channels = c1
agent.sinks.s1.channel = c1创建文件夹 /home/hadoop/data/flume/upload
-
在Kafka的安装目录下的config目录下,使用
cp server.properties servers_flume_kafka.properties创建一个配置文件,然后使用vi sudo servers_flume_kafka.properties调整内容
broker.id=4
listeners=PLAINTEXT://master:9092
advertised.listeners=PLAINTEXT://master:9092
log.dirs=/home/hadoop/data/kafka/kafka-logs
zookeeper.connect=master:2181,slave01:2181,slave02:2181/kafka -
-
启动Kafka服务
在Kafka安装目录下的bin目录下,使用命令
./kafka-server-start.sh -daemon $KAFKA_HOME/config/servers_flume_kafka.properties & -
创建topic
进入Kafka安装目录下的bin目录,使用命令
./kafka-topics.sh --create --zookeeper master:2181/kafka --replication-factor 3 --partitions 3 --topic logstest
-
查看Topic是否创建成功
./kafka-topics.sh --list --zookeeper master:2181/kafka
-
创建一个生产端
./kafka-console-producer.sh --broker-list master:9092,slave01:9092,slave02:9092 --topic logstest
-
创建一个消费端
./kafka-console-consumer.sh --bootstrap-server master:9092 --topic logstest --from-beginning
-
启动Flume
进入flume的安装目录下的bin目录,执行命令
./flume-ng agent \
--conf conf \
--name agent \
--conf-file /home/hadoop/app/apache-flume-1.6.0-bin/job/flume-kafka.conf
-Dflume.root.logger==INFO,console -
在新窗口网upload目录中放入文件
-
使用
sudo vi student.log创建student.log文件,添加内容
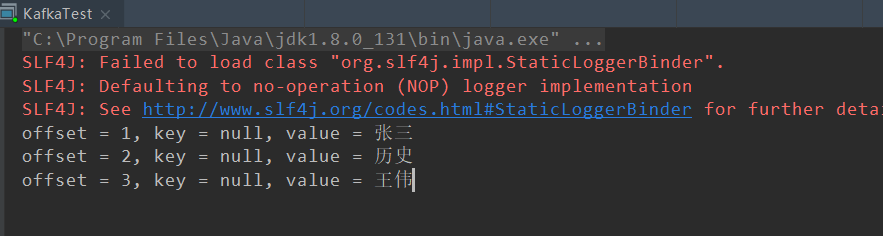
zhangsan 18 100
lishi 20 98
wangwu 19 60-
拷贝student.log到/home/hadoop/data/flume/upload目录之下
cp ../../student.log . -
观察结果
-
在Kafka消费端查看结果

-
-
2.使用Java读取Kafka
-
使用Idea创建maven项目
-
修改pom.xml文件
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.svse</groupId>
<artifactId>kafkatest</artifactId>
<version>1.0-SNAPSHOT</version>
<dependencies>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka_2.11</artifactId>
<version>2.3.0</version>
</dependency>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>2.3.0</version>
</dependency>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-streams</artifactId>
<version>2.3.0</version>
</dependency>
</dependencies>
</project> -
编写JAVA代码
package com.svse.kafak;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import java.util.Arrays;
import java.util.Properties;
public class KafkaTest {
public static void main(String[] args) {
//定义消费者对象
Properties props = new Properties();
props.put("bootstrap.servers", "master:9092");
props.put("group.id", "test");
props.put("enable.auto.commit", "true");
props.put("auto.commit.interval.ms", "1000");
props.put("session.timeout.ms", "30000");
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
KafkaConsumer<String, String> consumer = new KafkaConsumer(props);
consumer.subscribe(Arrays.asList("logstest"));
while (true) {
ConsumerRecords<String, String> records = consumer.poll(100);
for (ConsumerRecord<String, String> record : records)
System.out.printf("offset = %d, key = %s, value = %s\n", record.offset(), record.key(), record.value());
}
}
} -
执行应用程序,修改或添加内容到/home/hadoop/data/flume/upload目录之下

-
观察idea中的执行结果
5、总结