http://www.cnblogs.com/LBSer/p/3390852.html
最近单位需要做自己的分布式监控系统,因此看了一些资料,其中就有google的分布式追踪系统dapper的论文:http://static.googleusercontent.com/external_content/untrusted_dlcp/research.google.com/zh-CN//pubs/archive/36356.pdf,结合自己的理解描述下这篇论文。
一、引子:
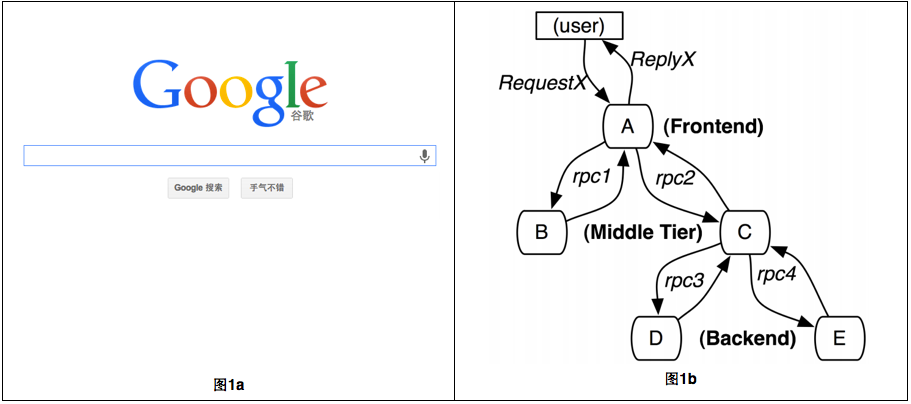
用户输入关键字后只要敲个回车键就能返回搜索结果(图1a),这样一个简单的过程可能涉及到上千个服务,可能需要上千个服务器协作完成。如图1b所示,user发了RequestX请求到达A,A通过rpc(远程过程调用,如thrift)调用B以及C,而C又需要通过rpc调用D以及E等等。
对user的一次请求,他迟迟未收到响应ReplyX,或者响应时间很慢,我们需要确认性能到底消耗在哪个环节,这个时候我们该怎么办呢?自然是分析我们的日志。
我们每个服务都会有请求日志,请求日志记录着一次调用所花费的时间,比如对A来说,记录着调用B所花费的时间以及调用C所花费的时间,同理C的请求日志记录着调用D以及E所花费的时间。对于互联网应用来说,各个服务比如B,同一时刻可能有成百上千次请求记录。
这种日志有个致命缺点---没有将这些记录与特定的请求关联一起。对于user的一条特定的请求RequestX,我们不知道B日志中哪条记录与之对应,也不知道C日志中哪条记录与之对应。。。总而言之,我们不能很具体的分析user的一次请求响应缓慢到底消耗在哪个环节。
二、 如何将各个服务日志的每一条记录与特定的请求关联在一起呢?
当前学术界和工业界有两种方法:
1)黑盒方法(black box)
日志还是一样的记录,只是通过机器学习的方法来关联记录与特定的请求。以一条特定请求RequestX为变量,通过黑盒(也就是机器学习的模型,比如回归分析)从A的日志中找出一条记录与之对应,同理可以找出B、C、D、E等等的相关记录。
黑盒方法的优势就是不需要改变现有日志记录方法,但是缺点很明显,机器学习的精度往往不高,实际使用中效果不好。
2)基于注释的方案
利用应用程序或中间件给每条记录一个全局标志符,借此将一串请求关联起来。比如对RequestX来说,赋予一个标志符1000,后续相关各个服务都会将标识符1000与记录一起打在日志里。这种方法的优势就是比较精确,目前google、twitter、淘宝等都采用这种方式。下面介绍google的分布式追踪系统解决方案---dapper。
三、dapper的设计目标:
1)低消耗
dapper本质是用来发现性能消耗问题,如果dapper本身很消耗性能,没人愿意使用,因此低消耗是必须的,dapper使用一系列创新方法确保低消耗,比如使用采样方法。
2)应用级透明
应用级透明的意思是程序员可以不需要在自己的代码中嵌入dapper相关的代码就能达到分布式追踪日志记录的目的。每一个工程师都希望自己的代码是纯粹的,如果需要嵌入dapper相关代码,那么既影响代码维护,又影响bug定位。
3)扩展性好
对于一个快速发展的互联网公司而言,用户规模快速增长导致着服务以及机器数量越来越多,因此dapper需要适应相应的发展,扩展性要好。
四、dapper的几个关键点:
1)dapper日志记录的格式是怎样的呢?
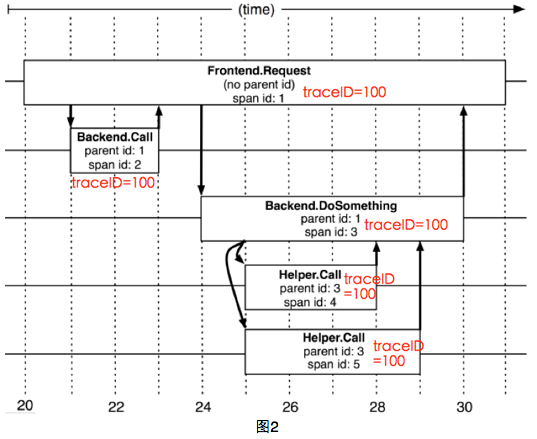
dapper用span来表示一个服务调用开始和结束的时间,也就是时间区间(图2对应着图1b的调用图)。dapper记录了span的名称以及每个span的ID和父ID,如果一个span没有父ID被称之为root span。所有的span都挂在一个特定得追踪上,共用一个跟踪ID,这些ID用全局64位整数标示,也就是图2的traceID。
2)如何实现应用级透明?
在google的环境中,所有的应用程序使用相同的线程模型、控制流和RPC系统,既然不能让工程师写代码记录日志,那么就只能让这些线程模型、控制流和RPC系统来自动帮助工程师记录日志了。
举个例子,几乎所有的google进程间通信是建立在一个用C++和JAVA开发的RPC框架上,dapper把跟踪植入这个框架,span的ID和跟踪的ID会从客户端发送到服务端,这样工程师也就不需要关心。
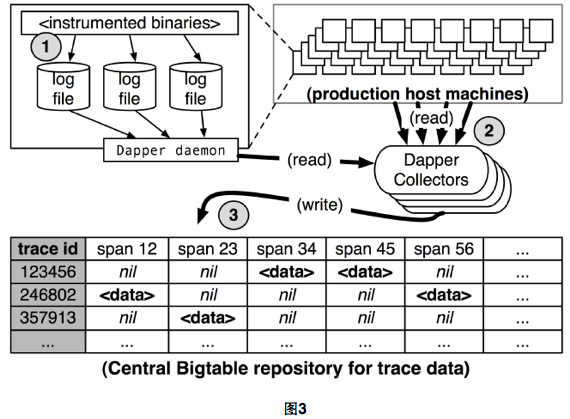
3)dapper跟踪收集的流程
如图3所示,分为3个阶段:a)各个服务将span数据写到本机日志上;b)dapper守护进程进行拉取,将数据读到dapper收集器里;c)dapper收集器将结果写到bigtable中,一次跟踪被记录为一行。
4)如何尽可能降低开销?
作为一个分布式追踪系统,dapper希望尽可能降低性能开销。如果对每一次的请求都进行追踪收集,开销还是有点大的。一个比较好的方式是通过统计采样的方法,抽样追踪一些请求,从而达到性能开销与精度的折中。
dapper的第一个版本设置了一个统一的采样率1/1024,也就是1024个请求才追踪一次。后来发现对一些高吞吐的服务来说是可以的,比如每秒几十万的请求,但是对一些低吞吐量的服务,比如每秒几十个请求的服务,如果采样率设置为1/1024,很多性能问题可能不会被追踪到。因此在第二版本dapper提供了自适应的采样率,在低吞吐量时候提高采样率,在高吞吐量时降低采样率。
上面的采样是在第一个阶段,此外在收集器将span数据写到bigtable时,还可以使用第二次采样,即不一定都将数据写入到bigtable中。
五、dapper的使用
1)监测新服务部署性能情况
对一个新服务,往往需要经过一段时间的观察,这时候可以使用dapper进行监测,从而发现存在的性能的问题;
2)推断服务间的依存关系
通过使用dapper,可以很清晰的表明一个服务依赖了哪些服务,以及一个服务影响到哪些服务,这样能促使我们在上线的时候能及时通知下游服务监控者重点观察。
...)
六、dapper的不足
1)某些时候缓冲一些请求,然后一次性操作会比较高效,比如I/O请求等。各个请求都有traceID,但是聚集之后只有一个请求,因此只能选择一个traceID用于传递到聚集请求,这时追踪会中断。
2)dapper可能找出某个环节慢了,但不一定能找出根源。比如一个请求慢可能不是它自身慢,而可能它在消息队列中比较靠后。
...)