选择模型类
在Scikit-Learn中分类树算法都保存在tree模块中,具体算法所属类为DecisionTreeClassifier
from sklearn.tree import DecisionTreeClassifier
DecisionTreeClassifier? #查看方法参数和输出属性
参数 | 解释
criterion:切分指数选择,即不纯度的衡量标准,除了默认的'gini'指数外还可输入信息熵‘entropy’用以计算信息增益
splitter :切分策略,默认是以不纯度衡量指标下降最快作为切分依据进行切分,即‘best’
max_depth:选择树的最大深度,如果对其进行设置,实际上相当于强行设置收敛条件(即树伸展几层),默认为None,即伸展至所有叶节点只 含有min_samples_split个数为止
min_samples_split:叶节点进行进一步切分时所需最少样本量,默认值为2,低于该值则不会再进行切分
min_samples_leaf: 叶节点最小样本量,默认值为1,若小于该数量,则会进行剪枝
部分属性说明:
属性 解释
classes_ :数据集标签列列名称
feature importances :特征重要性排名
n features :特征个数
选择模型超参数
可考虑强化收敛条件、修改不纯度衡量方法等,当然也可使⽤用默认超参数设置,直接进行实 例化操作
clf = DecisionTreeClassifier()
from sklearn.datasets import load_iris iris = load_iris()
iris.data#查看数据特征列
iris.target#查看数据标签列
数据集切割
sk-learn的切分数据集函数在model_selection类中。同时需要注意的 是,由于模型需要数组,因此训练集和测试集的特征数据和标签数据仍然需要分开存放
from sklearn.model_selection import train_test_split xtrain, xtest, ytrain, ytest = train_test_split(iris.data, iris.target, random_state=42)
同时 random_state=42 用于设置随机数种⼦子,可考虑输入 test_size 等参数用于设置数据集
切分比例,若不对其进行设置,则默认进行3:1的训练集和测试集的比例划分。更多参数设置参 见train_test_split函数相关⽅方法说明
训练模型
clf.fit(xtrain, ytrain) score = clf.score(xtest, ytest)#返回预测准确度 score
我们可以使利利用 Graphviz 模块导出决策树模型,第⼀次使用 Graphviz 之前需要对其
进行安装,若是使用conda进行的Python包管理,则可直接在命令行界面中利用下述指令进行安 装 conda install python-graphviz
from sklearn import tree import graphviz
将模型利用export_graphviz生成为DOT类型对象,该对象是专门用于绘制图形绘制的对
象,在其中可对图形进行⼀系列的设置,包括标签格式、决策树着色等,更多方法可在帮助文档 中进行查看,然后将其进一步转化为可生成图形的对象graph,该对象可直接用于展示图形
dot_data = tree.export_graphviz(clf, out_file=None)
graphviz.Source(dot_data)

为制定路路径、名称的PDF格式⽂文件
graph = graphviz.Source(dot_data) graph.render("iris")
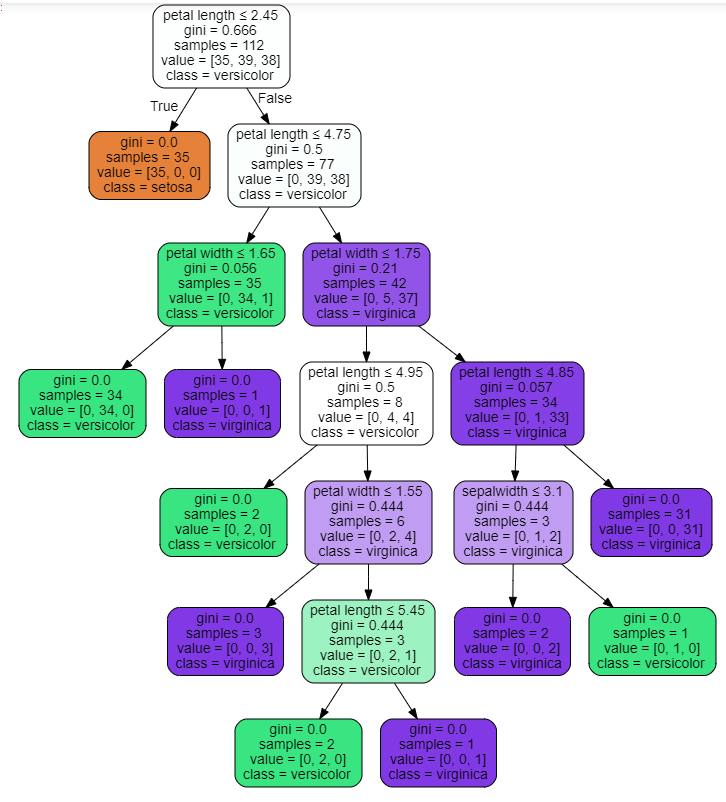
#美化图形 dot_data = tree.export_graphviz(clf, out_file=None, feature_names=['sepal length', 'sepalwidth', 'petal length', 'petal width'],#各变量名称 class_names=['setosa', 'versicolor','virginica'],#类别名称 filled=True,#让树的每一块有颜色,颜色越浅,表示不纯度越高 rounded=True,#树的块的形状 special_characters=True) graphviz.Source(dot_data)
clf.feature_importances_#各个特征列的重要程度
[*zip(['sepal length', 'sepalwidth', 'petal length', 'petal width'],clf.feature_importances_)]
classes_ :数据集标签列列名称
feature _ importances _:特征重要性排名
n _ features _:特征个数
In [ ]:
clf.classes_
Out[8]:
模型预测
y_clf = clf.predict(xtest)
y_clf
模型评估
#准确率评估 from sklearn.metrics import accuracy_score accuracy_score(ytest, y_clf)
所有函数显示
from sklearn.tree import DecisionTreeClassifier#导入模型 clf = DecisionTreeClassifier(criterion="entropy",random_state=30)#进行便利,注意这次我们调整了参数 from sklearn.model_selection import train_test_split xtrain, xtest, ytrain, ytest = train_test_split(iris.data, iris.target,random_state=42)#训练集与测试集合分割 clf.fit(xtrain, ytrain)#训练模型 score = clf.score(xtest, ytest)#返回预测准确度 score
#美化图形 dot_data = tree.export_graphviz(clf, out_file=None, feature_names=['sepal length', 'sepalwidth', 'petal length', 'petal width'],#各变量名称 class_names=['setosa', 'versicolor','virginica'],#类别名称 filled=True,#让树的每一块有颜色,颜色越浅,表示不纯度越高 rounded=True,#树的块的形状 special_characters=True) graphviz.Source(dot_data)
#保存决策树图像 graph = graphviz.Source(dot_data) graph.render("iris")
c
lf.feature_importances_#各个特征列的重要程度 [*zip(['sepal length', 'sepalwidth', 'petal length', 'petal width'],clf.feature_importances_)]
Out[55]:
y_clf = clf.predict(xtest)#模型预测
#准确率评估 from sklearn.metrics import accuracy_score accuracy_score(ytest, y_clf)